2. 描述性統(tǒng)計 上一篇介紹了數(shù)據(jù)的分類��、統(tǒng)計學是什么����、以及統(tǒng)計學知識的大分類����,本篇我們重點學習描述性統(tǒng)計學。
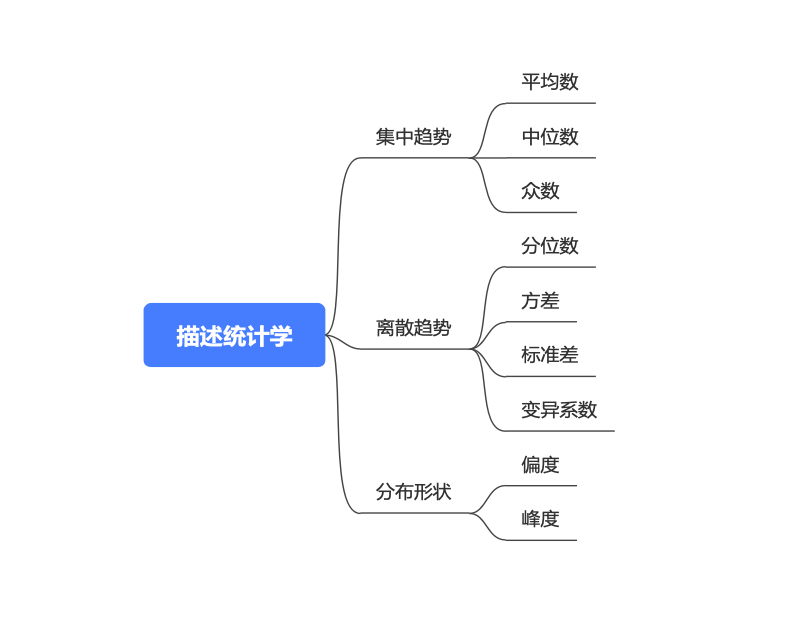
我們描述一組數(shù)據(jù)的時候���,通常分三個方面描述:集中趨勢�、離散趨勢、分布形狀��。通俗來說�,集中趨勢是描述數(shù)據(jù)集中在什么位置 ,離散趨勢描述的是數(shù)據(jù)分散的程度 ���,分布形狀描述的是數(shù)據(jù)形狀 ���。
首先,來看描述數(shù)據(jù)的集中趨勢 ����,使用的三個常見的統(tǒng)計量:
平均數(shù)
算術(shù)平均數(shù)
算術(shù)平均數(shù)是n個數(shù)求和后除以n得到的結(jié)果。廣泛應(yīng)用于各個領(lǐng)域��,用于描述和分析數(shù)據(jù)的平均水平和集中趨勢
Excel求算術(shù)平均數(shù)的函數(shù)=AVERAGE(A1:A8)
PS:聰明的你肯定知道把上面8個數(shù)據(jù) 2,23,4,17,12,12,13,16��,用左手復(fù)制到你Excel中的A1:A8單元格(記得豎著放?。?/p>
用Python求算術(shù)平均數(shù)
import numpy as np2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]
幾何平均數(shù)
幾何平均數(shù)就是n個數(shù)乘積的n次方根。在金融財務(wù)�、投資和銀行業(yè) 的問題中,幾何平均數(shù)的應(yīng)用尤為常見�。當你任何時候想確定過去幾個連續(xù)時期的平均變化率 時,都能應(yīng)用幾何平均數(shù)���。其他通常的應(yīng)用包括物種總體��、農(nóng)作物產(chǎn)量��、污染水平以及出生率和死亡率的變化��。(在第8節(jié)案例8.1 中會舉例說明)����。
公式如下:
Excel求幾何平均數(shù)的函數(shù)=GEOMEAN(A1:A8)
用Python求幾何平均數(shù)
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]n個數(shù)的倒數(shù)的算術(shù)平均數(shù)的倒數(shù)
Excel求調(diào)和平均數(shù)的函數(shù)=HARMEAN(A1:A8)
Python求調(diào)和平均數(shù)
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]還沒看暈吧?我們小結(jié)一下����,三者的大小排序一般是算術(shù)平均值 ≥ 幾何平均值 ≥ 調(diào)和平均值。另外
數(shù)值類數(shù)據(jù)的均值一般用算術(shù)平均值 ��,比例型數(shù)據(jù)的均值一般用幾何平均值 �,平均速度一般用調(diào)和平均數(shù)
中位數(shù) 中位數(shù)是把數(shù)據(jù)按照順序排列��,處于中間位置的那個數(shù)
Excel求中位數(shù)的函數(shù)=MEDIAN(A1:A8)
Python求中位數(shù)
import numpy as np2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]眾數(shù) 眾數(shù)是一組數(shù)據(jù)中出現(xiàn)次數(shù)最多的變量值�����。
Excel求眾數(shù)的函數(shù)=MODE(A1:A8)
Python求眾數(shù)
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]以上便是描述數(shù)據(jù)集中趨勢的幾個統(tǒng)計量����,接下來我們來看描述數(shù)據(jù)離散趨勢的統(tǒng)計量:
分位數(shù) 四分位數(shù)用3個分位數(shù)����,將數(shù)據(jù)等分成4個部分。這3個四分位數(shù)�����,分別位于這組數(shù)據(jù)升序排序后的25%���、50%和75%的位置上�。另外���,75%分位數(shù)與25%分位數(shù)的差叫做四分位距。
Excel求分位數(shù)的函數(shù)=QUARTILE(A1:A8,1) �����,括號里面的參數(shù):0代表最小值,1代表25%分位數(shù)��,2代表50%分位數(shù)���,3代表75%分位數(shù),4代表最大值,
Python求該組數(shù)據(jù)的下四分位數(shù)與上四分位數(shù)
from scipy import stats as sts 2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]25 )) 75 )) 10.0 16.25
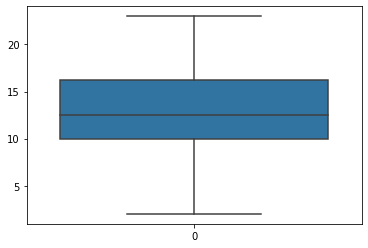
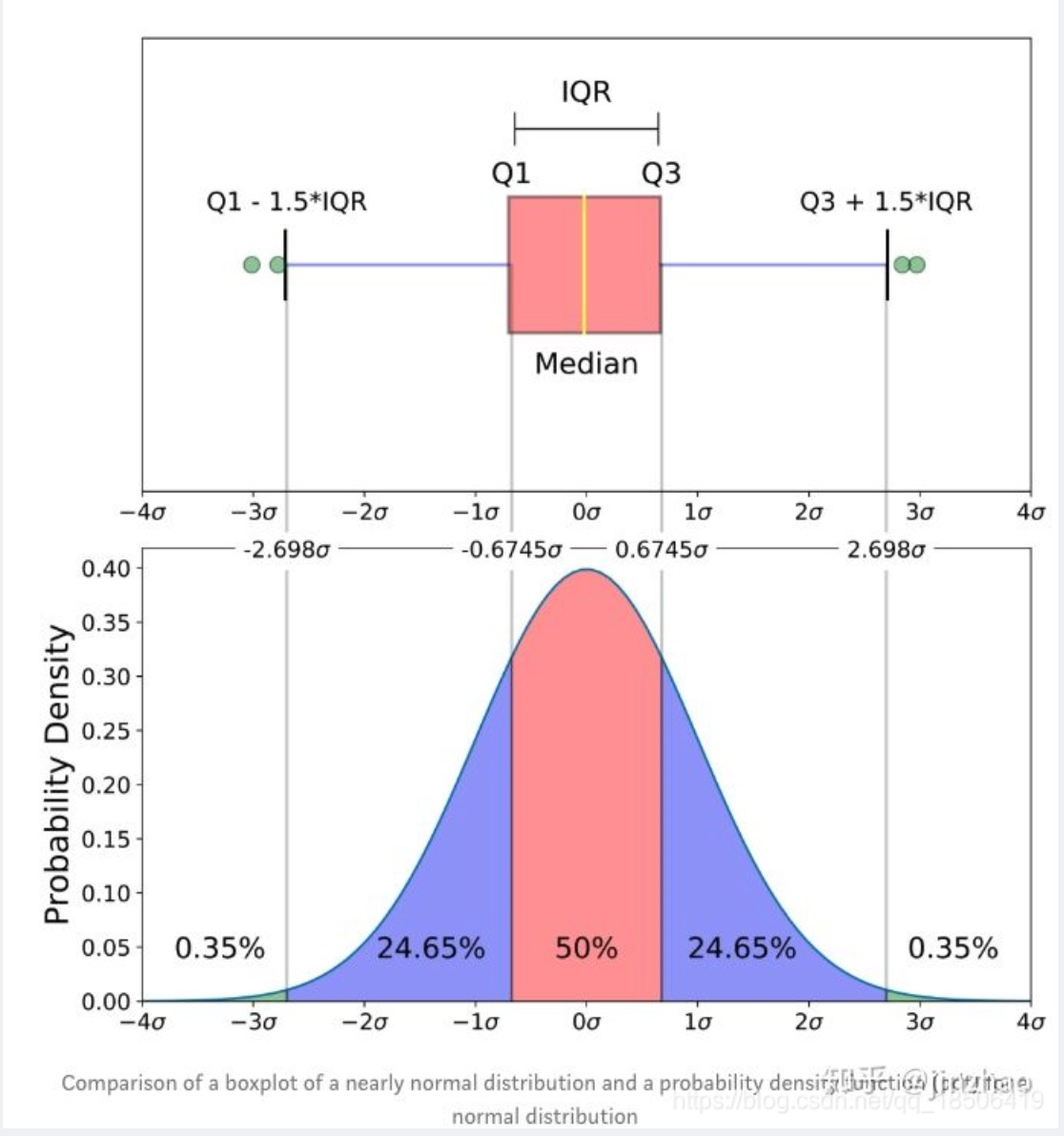
補充一點���,關(guān)于描述性統(tǒng)計部分的圖表可視化,本系列教程不做展開,唯一值得一提的是箱線圖 第8節(jié)案例8.2 中會詳細舉例說明)這里先簡單舉例如下
用四分位數(shù)繪制的箱線圖
import seaborn as sns箱線圖 可以很直觀地看到:數(shù)據(jù)的最大值��、最小值��、以及大部分數(shù)據(jù)集中在什么區(qū)間��。
具體來說就是:
異常值 、上邊緣 Q3+1.5(Q3-Q1)�����、上四分位數(shù) Q3���、中位數(shù) Q2
下四分位數(shù) Q1、下邊緣 Q1-1.5(Q3-Q1)
極差又稱范圍誤差或全距����,是指一組數(shù)據(jù)中最大值與最小值的差
Excel求極差的函數(shù)=MAX(A1:A8) - MIN(A1:A8)
Python 求極差
import numpy as np2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]四分位距是上四分位數(shù)與下四分位數(shù)之差,一般用
Excel求分位數(shù)的函數(shù)=QUARTILE(A1:A8,3)-QUARTILE(A1:A8,1)
Python 求四分位距
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]75 )-sts.scoreatpercentile(data,25 ))方差 是一組數(shù)據(jù)中的各數(shù)據(jù)值與該組數(shù)據(jù)算術(shù)平均數(shù)之差的平方的算術(shù)平均數(shù)。
Excel求方差 的函數(shù)=VAR(A1:A8)
Python求方差
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]1 ))標準差 為方差 的開方���。總體標準差 常用σ表示��,樣本標準差 常用S表示�����。
Excel求方差 的函數(shù)=STDEV(A1:A8)
Python求標準差 :
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]1 ))變異系數(shù) 對不同變量或不同數(shù)組的離散程度進行比較時,如果它們的平均水平和計量單位都相同,才能利用上述指標進行分析���,否則需利用變異系數(shù)來比較它們的離散程度。
變異系數(shù)又稱為離散系數(shù)���,是一組數(shù)據(jù)中的極差�����、四分位差或標準差 等離散指標與算術(shù)平均數(shù)的比率�����。
Excel求變異系數(shù)的函數(shù)=STDEV(A1:A8)/AVERAGE(A1:A8)
Python求標準差 變異系數(shù):
from scipy import stats as stsprint (sts.tstd(data)/sts.tmean(data))看完了描述數(shù)據(jù)離散程度的幾個統(tǒng)計量,我們接著看描述數(shù)據(jù)分布形狀的偏度和峰度:
偏度 偏度系數(shù)是對分布偏斜程度的測度�����,通常用SK表示。偏度衡量隨機變量 概率分布 的不對稱性����,是相對于平均值不對稱程度的度量。
當偏度系數(shù)為正值時�����,表示正偏離差數(shù)值較大����,可以判斷為正偏態(tài)或右偏態(tài)�����;反之�,當偏度系數(shù)為負值時����,表示負偏離差數(shù)值較大��,可以判斷為負偏態(tài)或左偏態(tài)�����。偏度系數(shù)的絕對值越大����,表示偏斜的程度就越大��。
Excel求偏度的函數(shù)=SKEW(A1:A8)
Python如何求偏度:
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]False )) 峰度 峰度描述的是分布集中趨勢高峰的形態(tài),通常與標準正態(tài)分布 相比較����。在歸一化到同一方差 時,若分布的形狀比標準正態(tài)分布 更“瘦”���、更“高”���,則稱為尖峰分布�;若比標準正態(tài)分布 更“矮”�、更“胖”,則稱為平峰分布��。
峰度系數(shù)是對分布峰度的測度�����,通常用K表示:
由于標準正態(tài)分布 的峰度系數(shù)為0�,所以當峰度系數(shù)大于0時為尖峰分布,當峰度系數(shù)小于0時為平峰分布�����。
Excel求峰度的函數(shù)
=KURT(A1:A8)
Python如何求峰度:
from scipy import stats as sts2 ,23 ,4 ,17 ,12 ,12 ,13 ,16 ]False ))
下期預(yù)告:《Python統(tǒng)計學極簡入門》第3節(jié) 數(shù)據(jù)分布
這里分享一個你一定用得到的小程序——CDA數(shù)據(jù)分析師考試小程序���。
它是專為CDA數(shù)據(jù)分析認證考試報考打造的一款小程序?���?梢詭湍憧焖賵竺荚嚒⒉槌煽?��、查證書�、查積分,通過該小程序����,考生可以享受更便捷的服務(wù)。
掃碼加入CDA小程序����,與圈內(nèi)考生一同學習、交流����、進步!













 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330