SPSS帶你玩轉(zhuǎn)GLM方差分析,一學(xué)就會
方差分析(Analysis of Variance����,簡稱ANOVA),又稱“變異數(shù)分析”或“F檢驗”���,是R.A.Fisher發(fā)明的�,用于兩個及兩個以上樣本均數(shù)差別的顯著性檢驗�����。它是以F值為統(tǒng)計量的計量資料的假設(shè)檢驗方法�����。檢驗方法是將總方差分解成兩個或多個部分方差和����,推斷兩組或多組的總體無數(shù)是否相等。原假設(shè)H0:多個試驗組的總體均數(shù)相等����,即處理因素?zé)o作用。檢驗水準(zhǔn):ɑ=0.05���。
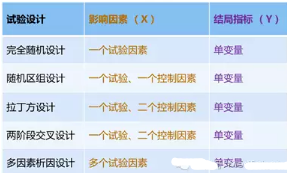
GLM(一般線性模型)一般用于完全隨機設(shè)計資料的方差分析(單因素方差分析)�����、隨機區(qū)組設(shè)計資料的方差分析(兩因素方差分析)���、拉丁方設(shè)計資料的方差分析�����、交叉設(shè)計的方差分析��、析因設(shè)計的方差分析�����、協(xié)方差分析和重復(fù)測量的方差分析���。
SPSS方差分析模塊——General Linear Model
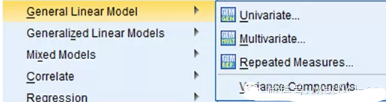
Univariate:單變量方差分析——單結(jié)局指標(biāo)(y),適用多種試驗設(shè)計的分析
Multivariate:多變量方差分析——多結(jié)局指標(biāo)(y1,y2…yk)
Repeated:重復(fù)測量方差分析
注意單因素方差分析是1個y��,1個x(三分類以上)�����,而單變量方差分析是1個y,1個或多個x�,多變量方差分析是多個y,1個或多個x�。單變量方差分析包含單因素方差分析(one-way ANOVA)����。
1完全隨機設(shè)計資料的方差分析
完全隨機設(shè)計資料的方差分析是將同質(zhì)的受試對象隨機地分配到各處理組,再觀察其試驗效應(yīng)��。各組樣本量可以相等或不等���。通過考察單因素或單變量結(jié)果一致性��,獲得一個因素的多個不同水平之間的關(guān)系�����,它也是t檢驗的擴展����。適用條件是樣本為獨立隨機樣本�����,服從正態(tài)分布,各組方差齊同�����,單個因變量為連續(xù)變量等��。
案例:
研究:3組不同藥物處理(A藥��,B藥與安慰劑)��,觀察對糖化血紅蛋白的影響���。
方法:為了研究三組糖化血紅蛋白水平的差異�,采用one way ANOVA分析����,也可以采用Univariate分析。
One-way ANOVA檢驗結(jié)果
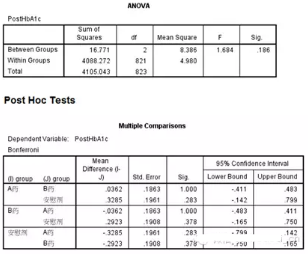
Univariate分析:
SPSS操作:Analyze ? General linear model ? Univariate
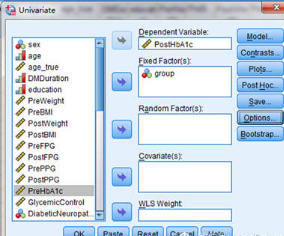
其中�,固定因子(fixed factor)是指該因子在樣本中所有可能的水平都出現(xiàn)了,即該因子的所有水平均列出了����,無需外推。隨機因子(random factor)是指該因子的所有可能的水平在樣本中沒有都出現(xiàn)�,需要進行外推���。可見固定因子和隨機因子是由試驗設(shè)計決定的���,所以我們可以根據(jù)試驗設(shè)計的不同���,將同一因素視為固定因子或隨機因子均可�����。
在試驗的設(shè)計中����,協(xié)變量是一個獨立變量(解釋變量),不為試驗者所操縱�,但仍影響實驗結(jié)果。在心理學(xué)����、行為科學(xué)中,是指與因變量有線性相關(guān)并在探討自變量與因變量關(guān)系時通過統(tǒng)計技術(shù)加以控制的變量�。常用的協(xié)變量包括因變量的前測分?jǐn)?shù)、人口統(tǒng)計學(xué)指標(biāo)以及與因變量明顯不同的個人特征等��。
Univariate分析結(jié)果
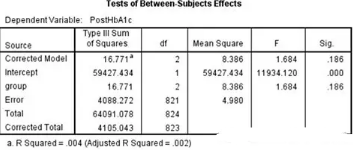
Univariate分析結(jié)果與one way ANOVA結(jié)果完全一致!
2隨機區(qū)組設(shè)計資料的方差分析
隨機區(qū)組設(shè)計(randomized block design)�,是將受試對象按性質(zhì)(如動物的性別、體重����,病人的病情、性別���、年齡等非試驗因素)相同或相近組成b個區(qū)組�,每個區(qū)組中的k個受試對象分別隨機分配到k個處理組中去��;區(qū)組間差別越大越好�,區(qū)組內(nèi)差別越小越好。隨機區(qū)組設(shè)計的作用是進一步控制個體差異����,檢驗效能高于完全隨機設(shè)計的方差分析。
1.單獨效應(yīng)(simple effect):其他因素的水平固定時���,同一因素不同水平間的差別��。
2.主效應(yīng)(main effect):因子不同水平設(shè)置對響應(yīng)造成的差異(這時不考慮其他因子的水平設(shè)置)����。
3.交互作用(interaction) :一個因子在另一個因子的不同水平下的主效應(yīng)是否有差異。理解為條件主效應(yīng)的差異���。

案例:
原案例(完全隨機對照)中���,考慮各處理組(A藥,B藥與安慰劑)對結(jié)局(糖化血紅蛋白)的影響�,但糖尿病病程可能是對患者結(jié)局影響的重要混雜因素。我們可以在事先設(shè)計中�,將糖尿病病程相近的36個人分成12個區(qū)組,再將每個區(qū)組的3個人隨機分入3組(隨機區(qū)組設(shè)計)�。
隨機區(qū)組設(shè)計的分析方法
One-way ANOVA只能獨立分析各處理組對結(jié)局(糖化血紅蛋白)的影響,無法同時分析組別(試驗因素)和病程(控制因素)對結(jié)局的影響���。此時應(yīng)該采用Univariate分析。
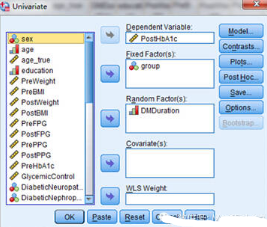
Univariate分析設(shè)置:Model
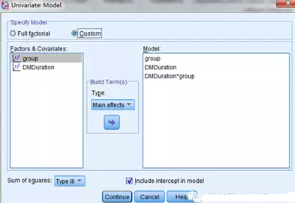
對話框中選擇custom(自定義模型)�,Main effects(主效應(yīng)),TypeⅢ(常見平方和類型)��。DMDuration*group為交互效應(yīng)�����,如果沒有交互一般不選擇這項。
Univariate分析設(shè)置:Contrasts
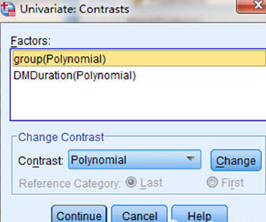
Contrast選擇Polynomial(多項式模型趨勢檢驗)���。
Univariate分析設(shè)置: Post Hoc
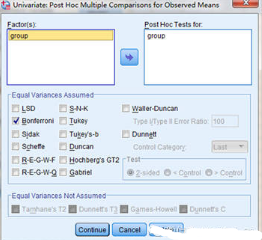
Univariate結(jié)果解讀
主體間效應(yīng)的檢驗
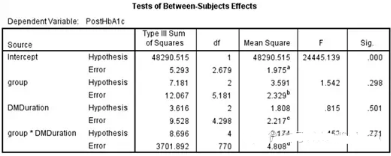
各組間糖化血紅蛋白水平��,以及各病程間糖化血紅蛋白水平�����,以及病程對分組的交互影響不明顯��。
期望均方表
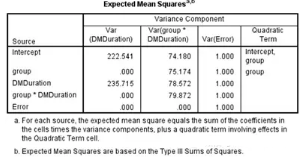
類似方差分析表因素變異和殘差
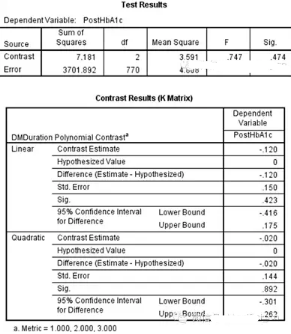
兩個模型中�,假定值均相同都等于0���,故參照估計值和差值相等��;參照估計值和差值在線性和二次模型中均p>0.05�,表明均不服從模型����;按α=0.05檢驗水準(zhǔn),各組糖化不呈線性和二次模型趨勢���。
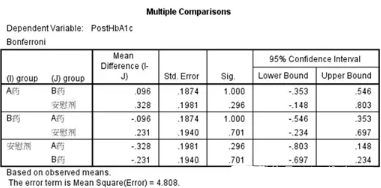
兩兩比較����,同樣無顯著性差異。
3析因設(shè)計資料的方差分析
普通分組設(shè)計:A藥與B藥對比���,或三組:A藥, B藥�,安慰劑�;析因設(shè)計:A藥與安慰劑;B藥與安慰劑��。普通分組重點考察兩類藥物本身的對比�����。而析因則相對獨立成組�,能比較A藥與安慰劑,B藥與安慰劑��,但一般并不比較A藥與B藥間差異�����。析因能分析A與B的交互��,普通分組則不可以���。
析因設(shè)計(factorial)
研究目的:觀察兩類藥物對疾病的影響
Univariate分析設(shè)置
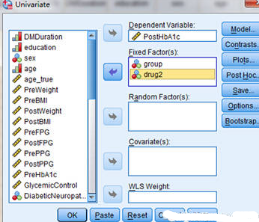
Univariate分析設(shè)置:Plots
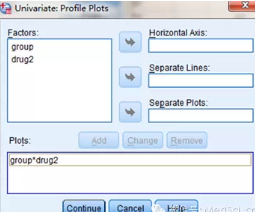
Univariate分析設(shè)置:Model(參閱前文)
Univariate分析設(shè)置:Options
Univariate分析設(shè)置:contrasts(參閱前文)
Univariate分析設(shè)置: Post Hoc(參閱前文)
Univariate結(jié)果解讀
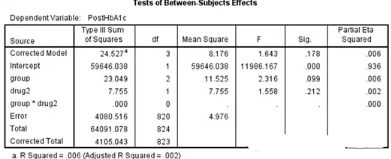
各處理組間���,以及drug2對糖化血紅蛋白水平均無顯著性影響。
凡涉及存在交互效應(yīng)���,或不同效應(yīng)因素(隨機效應(yīng)���,或協(xié)變量存在),都建議采用GLM方法����,而并不建議用one-way ANOVA。完全隨機對照可以使用one-way ANOVA����,但隨機區(qū)組設(shè)計和析因研究則要采用univariate方法分析。
4協(xié)方差分析
為了提高試驗的精確性和準(zhǔn)確性�����,對處理以外的一切條件都需要采取有效措施嚴(yán)加控制�����,使它們在各處理間盡量一致��,比如隨機區(qū)組設(shè)計���。并且試驗設(shè)計也有可能疏忽����,限于試驗條件的限制,因素?zé)o法掌控等��,就要采用協(xié)方差分析�。它是試驗控制的一種輔助手段���。經(jīng)這種矯正���,試驗誤差將減小����,對試驗處理效應(yīng)估計更為準(zhǔn)確。
協(xié)方差分析等于回歸分析加方差分析,分析步驟:
1�����、回歸:建立應(yīng)變量Y隨協(xié)變量X變化的線性回歸關(guān)系,并利用這種回歸關(guān)系把X值化為相等后再進行各組Y的修正����;
2�、方差:各組Y的修正均數(shù)間比較的假設(shè)檢驗。
實質(zhì):從Y中扣除或均衡這些不可控的協(xié)變量因素的影響后�����,再比較多組均數(shù)間的差別����。
協(xié)方差分析應(yīng)用時要注意各組協(xié)變量X與因變量Y的關(guān)系是線性的,各組回歸直線平行�。
推薦學(xué)習(xí)書籍
《CDA一級教材》適合CDA一級考生備考,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我���。完整電子版已上線CDA網(wǎng)校��,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330