Python數(shù)據(jù)挖掘之決策樹DTC數(shù)據(jù)分析及鳶尾數(shù)據(jù)集分析
今天主要講述的內(nèi)容是關(guān)于決策樹的知識(shí)���,主要包括以下內(nèi)容:1.分類及決策樹算法介紹2.鳶尾花卉數(shù)據(jù)集介紹3.決策樹實(shí)現(xiàn)鳶尾數(shù)據(jù)集分析����。希望這篇文章對(duì)你有所幫助�,尤其是剛剛接觸數(shù)據(jù)挖掘以及大數(shù)據(jù)的同學(xué),同時(shí)準(zhǔn)備嘗試以案例為主的方式進(jìn)行講解��。如果文章中存在不足或錯(cuò)誤的地方���,還請(qǐng)海涵~
一. 分類及決策樹介紹
1.分類
分類其實(shí)是從特定的數(shù)據(jù)中挖掘模式,作出判斷的過程����。比如Gmail郵箱里有垃圾郵件分類器,一開始的時(shí)候可能什么都不過濾����,在日常使用過程中,我人工對(duì)于每一封郵件點(diǎn)選“垃圾”或“不是垃圾”,過一段時(shí)間��,Gmail就體現(xiàn)出一定的智能�����,能夠自動(dòng)過濾掉一些垃圾郵件了��。
這是因?yàn)樵邳c(diǎn)選的過程中����,其實(shí)是給每一條郵件打了一個(gè)“標(biāo)簽”,這個(gè)標(biāo)簽只有兩個(gè)值�����,要么是“垃圾”����,要么“不是垃圾”,Gmail就會(huì)不斷研究哪些特點(diǎn)的郵件是垃圾�,哪些特點(diǎn)的不是垃圾,形成一些判別的模式���,這樣當(dāng)一封信的郵件到來��,就可以自動(dòng)把郵件分到“垃圾”和“不是垃圾”這兩個(gè)我們?nèi)斯ぴO(shè)定的分類的其中一個(gè)�。
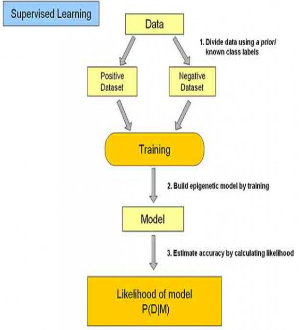
分類學(xué)習(xí)主要過程如下:
(1)訓(xùn)練數(shù)據(jù)集存在一個(gè)類標(biāo)記號(hào),判斷它是正向數(shù)據(jù)集(起積極作用���,不垃圾郵件)�,還是負(fù)向數(shù)據(jù)集(起抑制作用��,垃圾郵件)�;
(2)然后需要對(duì)數(shù)據(jù)集進(jìn)行學(xué)習(xí)訓(xùn)練,并構(gòu)建一個(gè)訓(xùn)練的模型�����;
(3)通過該模型對(duì)預(yù)測(cè)數(shù)據(jù)集進(jìn)預(yù)測(cè)�,并計(jì)算其結(jié)果的性能��。
2.決策樹(decision tree)
決策樹是用于分類和預(yù)測(cè)的主要技術(shù)之一���,決策樹學(xué)習(xí)是以實(shí)例為基礎(chǔ)的歸納學(xué)習(xí)算法����,它著眼于從一組無次序����、無規(guī)則的實(shí)例中推理出以決策樹表示的分類規(guī)則�。構(gòu)造決策樹的目的是找出屬性和類別間的關(guān)系����,用它來預(yù)測(cè)將來未知類別的記錄的類別。它采用自頂向下的遞歸方式����,在決策樹的內(nèi)部節(jié)點(diǎn)進(jìn)行屬性的比較,并根據(jù)不同屬性值判斷從該節(jié)點(diǎn)向下的分支�����,在決策樹的葉節(jié)點(diǎn)得到結(jié)論�����。
決策樹算法根據(jù)數(shù)據(jù)的屬性采用樹狀結(jié)構(gòu)建立決策模型����, 決策樹模型常用來解決分類和回歸問題。常見的算法包括:分類及回歸樹(Classification And Regression Tree��, CART)��, ID3 (Iterative Dichotomiser 3), C4.5��, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 隨機(jī)森林(Random Forest)�, 多元自適應(yīng)回歸樣條(MARS)以及梯度推進(jìn)機(jī)(Gradient Boosting Machine, GBM)����。
決策數(shù)有兩大優(yōu)點(diǎn):1)決策樹模型可以讀性好,具有描述性���,有助于人工分析��;2)效率高����,決策樹只需要一次構(gòu)建�,反復(fù)使用,每一次預(yù)測(cè)的最大計(jì)算次數(shù)不超過決策樹的深度����。
示例1:
下面舉兩個(gè)例子�����,參考下面文章,強(qiáng)烈推薦大家閱讀�����,尤其是決策樹原理���。
算法雜貨鋪——分類算法之決策樹(Decision tree) - leoo2sk
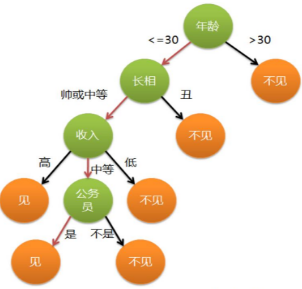
這個(gè)也是我上課講述的例子��,引用上面文章的����。通俗來說�����,決策樹分類的思想類似于找對(duì)象?����,F(xiàn)想象一個(gè)女孩的母親要給這個(gè)女孩介紹男朋友�,于是有了下面的對(duì)話:
女兒:多大年紀(jì)了?
母親:26�����。
女兒:長(zhǎng)的帥不帥?
母親:挺帥的�。
女兒:收入高不?
母親:不算很高�,中等情況。
女兒:是公務(wù)員不����?
母親:是,在稅務(wù)局上班呢�。
女兒:那好,我去見見��。
這個(gè)女孩的決策過程就是典型的分類樹決策����。相當(dāng)于通過年齡、長(zhǎng)相����、收入和是否公務(wù)員對(duì)將男人分為兩個(gè)類別:見和不見。假設(shè)這個(gè)女孩對(duì)男人的要求是:30歲以下����、長(zhǎng)相中等以上并且是高收入者或中等以上收入的公務(wù)員��,那么這個(gè)可以用下圖表示女孩的決策邏輯。
示例2:
另一個(gè)課堂上的例子��,參考CSDN的大神lsldd的文章�,推薦大家閱讀學(xué)習(xí)信息熵。
用Python開始機(jī)器學(xué)習(xí)(2:決策樹分類算法)
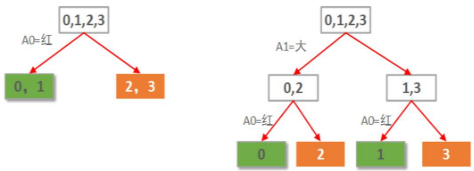
假設(shè)要構(gòu)建這么一個(gè)自動(dòng)選好蘋果的決策樹���,簡(jiǎn)單起見�����,我只讓他學(xué)習(xí)下面這4個(gè)樣本:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
樣本 紅 大 好蘋果
0 1 1 1
1 1 0 1
2 0 1 0
3 0 0 0
樣本中有2個(gè)屬性����,A0表示是否紅蘋果���。A1表示是否大蘋果����。
本例僅2個(gè)屬性�����。那么很自然一共就只可能有2棵決策樹,如下圖所示:
示例3:
第三個(gè)例子�����,推薦這篇文章:決策樹學(xué)習(xí)筆記整理 - bourneli

決策樹構(gòu)建的基本步驟如下:
1. 開始����,所有記錄看作一個(gè)節(jié)點(diǎn);
2. 遍歷每個(gè)變量的每一種分割方式��,找到最好的分割點(diǎn)���;
3. 分割成兩個(gè)節(jié)點(diǎn)N1和N2�����;
4. 對(duì)N1和N2分別繼續(xù)執(zhí)行2-3步��,直到每個(gè)節(jié)點(diǎn)足夠“純”為止�����。
二. 鳶尾花卉Iris數(shù)據(jù)集
在Sklearn機(jī)器學(xué)習(xí)包中���,集成了各種各樣的數(shù)據(jù)集,上節(jié)課講述Kmeans使用的是一個(gè)NBA籃球運(yùn)動(dòng)員數(shù)據(jù)集,需要定義X多維矩陣或讀取文件導(dǎo)入���,而這節(jié)課使用的是鳶尾花卉Iris數(shù)據(jù)集�,它是很常用的一個(gè)數(shù)據(jù)集�����。
數(shù)據(jù)集來源:Iris plants data set - KEEL dataset
該數(shù)據(jù)集一共包含4個(gè)特征變量��,1個(gè)類別變量�。共有150個(gè)樣本���,鳶尾有三個(gè)亞屬�����,分別是山鳶尾 (Iris-setosa)��,變色鳶尾(Iris-versicolor)和維吉尼亞鳶尾(Iris-virginica)��。
iris是鳶尾植物�,這里存儲(chǔ)了其萼片和花瓣的長(zhǎng)寬��,共4個(gè)屬性,鳶尾植物分三類�����。
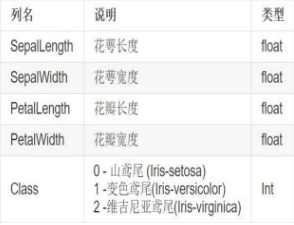
iris里有兩個(gè)屬性iris.data����,iris.target。
data里是一個(gè)矩陣����,每一列代表了萼片或花瓣的長(zhǎng)寬,一共4列�����,每一列代表某個(gè)被測(cè)量的鳶尾植物�����,一共采樣了150條記錄����。代碼如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#導(dǎo)入數(shù)據(jù)集iris
from sklearn.datasets import load_iris
#載入數(shù)據(jù)集
iris = load_iris()
#輸出數(shù)據(jù)集
print iris.data
輸出如下所示:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]
[ 5.4 3.9 1.7 0.4]
[ 4.6 3.4 1.4 0.3]
[ 5. 3.4 1.5 0.2]
[ 4.4 2.9 1.4 0.2]
....
[ 6.7 3. 5.2 2.3]
[ 6.3 2.5 5. 1.9]
[ 6.5 3. 5.2 2. ]
[ 6.2 3.4 5.4 2.3]
[ 5.9 3. 5.1 1.8]]
target是一個(gè)數(shù)組,存儲(chǔ)了data中每條記錄屬于哪一類鳶尾植物���,所以數(shù)組的長(zhǎng)度是150��,數(shù)組元素的值因?yàn)楣灿?類鳶尾植物����,所以不同值只有3個(gè)。種類:
Iris Setosa(山鳶尾)
Iris Versicolour(雜色鳶尾)
Iris Virginica(維吉尼亞鳶尾)
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#輸出真實(shí)標(biāo)簽
print iris.target
print len(iris.target)
#150個(gè)樣本 每個(gè)樣本4個(gè)特征
print iris.data.shape
輸出結(jié)果如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
(150L, 4L)
可以看到�����,類標(biāo)共分為三類��,前面50個(gè)類標(biāo)位0�,中間50個(gè)類標(biāo)位1���,后面為2����。
下面給詳細(xì)介紹使用決策樹進(jìn)行對(duì)這個(gè)數(shù)據(jù)集進(jìn)行測(cè)試的代碼�。
三. 決策樹實(shí)現(xiàn)鳶尾數(shù)據(jù)集分析
1. DecisionTreeClassifier
Sklearn機(jī)器學(xué)習(xí)包中,決策樹實(shí)現(xiàn)類是DecisionTreeClassifier���,能夠執(zhí)行數(shù)據(jù)集的多類分類����。
輸入?yún)?shù)為兩個(gè)數(shù)組X[n_samples,n_features]和y[n_samples],X為訓(xùn)練數(shù)據(jù),y為訓(xùn)練數(shù)據(jù)的標(biāo)記數(shù)據(jù)�。
DecisionTreeClassifier構(gòu)造方法為:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
sklearn.tree.DecisionTreeClassifier(criterion='gini'
, splitter='best'
, max_depth=None
, min_samples_split=2
, min_samples_leaf=1
, max_features=None
, random_state=None
, min_density=None
, compute_importances=None
, max_leaf_nodes=None)
鳶尾花數(shù)據(jù)集使用決策樹的代碼如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 14 21:44:19 2016
@author: 楊秀璋
"""
#導(dǎo)入數(shù)據(jù)集iris
from sklearn.datasets import load_iris
#載入數(shù)據(jù)集
iris = load_iris()
print iris.data #輸出數(shù)據(jù)集
print iris.target #輸出真實(shí)標(biāo)簽
print len(iris.target)
print iris.data.shape #150個(gè)樣本 每個(gè)樣本4個(gè)特征
#導(dǎo)入決策樹DTC包
from sklearn.tree import DecisionTreeClassifier
#訓(xùn)練
clf = DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
print clf
#預(yù)測(cè)
predicted = clf.predict(iris.data)
#獲取花卉兩列數(shù)據(jù)集
X = iris.data
L1 = [x[0] for x in X]
print L1
L2 = [x[1] for x in X]
print L2
#繪圖
import numpy as np
import matplotlib.pyplot as plt
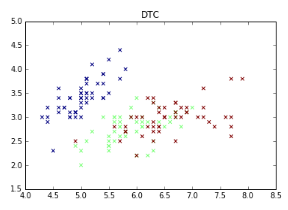
plt.scatter(L1, L2, c=predicted, marker='x') #cmap=plt.cm.Paired
plt.title("DTC")
plt.show()
輸出結(jié)果如下所示,可以看到分位三類����,分別代表數(shù)據(jù)集三種鳶尾植物。
2.代碼優(yōu)化
在課堂上我講過�����,這里存在兩個(gè)問題:
1.前面鳶尾Iris數(shù)據(jù)集包括四個(gè)特征(萼片長(zhǎng)度��、萼片寬度�、花瓣長(zhǎng)度、花瓣寬度)����,上面代碼中"L1 = [x[0] for x in X]"我獲取了第一列和第二列數(shù)據(jù)集進(jìn)行的繪圖,而真是數(shù)據(jù)集中可能存在多維特征�����,那怎么實(shí)現(xiàn)呢��?
這里涉及到一個(gè)降維操作,后面會(huì)詳細(xì)介紹�����。
2.第二個(gè)問題是�����,分類學(xué)習(xí)模型如下所示����,它的預(yù)測(cè)是通過一組新的數(shù)據(jù)集�����。
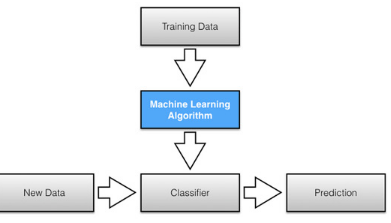
而上面的代碼"predicted = clf.predict(iris.data)"是對(duì)整個(gè)的數(shù)據(jù)集進(jìn)行決策樹分析��,而真是的分類分析����,需要把一部分?jǐn)?shù)據(jù)集作為訓(xùn)練,一部分作為預(yù)測(cè)����,這里使用70%的訓(xùn)練����,30%的進(jìn)行預(yù)測(cè)���。代碼如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#訓(xùn)練集
train_data = np.concatenate((iris.data[0:40, :], iris.data[50:90, :], iris.data[100:140, :]), axis = 0)
#訓(xùn)練集樣本類別
train_target = np.concatenate((iris.target[0:40], iris.target[50:90], iris.target[100:140]), axis = 0)
#測(cè)試集
test_data = np.concatenate((iris.data[40:50, :], iris.data[90:100, :], iris.data[140:150, :]), axis = 0)
#測(cè)試集樣本類別
test_target = np.concatenate((iris.target[40:50], iris.target[90:100], iris.target[140:150]), axis = 0)
優(yōu)化后的完整代碼如下所示����,同時(shí)輸出準(zhǔn)確率����、召回率等。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 14 21:44:19 2016
@author: 楊秀璋
"""
#導(dǎo)入數(shù)據(jù)集iris
from sklearn.datasets import load_iris
#載入數(shù)據(jù)集
iris = load_iris()
'''''
print iris.data #輸出數(shù)據(jù)集
print iris.target #輸出真實(shí)標(biāo)簽
print len(iris.target)
print iris.data.shape #150個(gè)樣本 每個(gè)樣本4個(gè)特征
'''
'''''
重點(diǎn):分割數(shù)據(jù)集 構(gòu)造訓(xùn)練集/測(cè)試集���,120/30
70%訓(xùn)練 0-40 50-90 100-140
30%預(yù)測(cè) 40-50 90-100 140-150
'''
#訓(xùn)練集
train_data = np.concatenate((iris.data[0:40, :], iris.data[50:90, :], iris.data[100:140, :]), axis = 0)
#訓(xùn)練集樣本類別
train_target = np.concatenate((iris.target[0:40], iris.target[50:90], iris.target[100:140]), axis = 0)
#測(cè)試集
test_data = np.concatenate((iris.data[40:50, :], iris.data[90:100, :], iris.data[140:150, :]), axis = 0)
#測(cè)試集樣本類別
test_target = np.concatenate((iris.target[40:50], iris.target[90:100], iris.target[140:150]), axis = 0)
#導(dǎo)入決策樹DTC包
from sklearn.tree import DecisionTreeClassifier
#訓(xùn)練
clf = DecisionTreeClassifier()
#注意均使用訓(xùn)練數(shù)據(jù)集和樣本類標(biāo)
clf.fit(train_data, train_target)
print clf
#預(yù)測(cè)結(jié)果
predict_target = clf.predict(test_data)
print predict_target
#預(yù)測(cè)結(jié)果與真實(shí)結(jié)果比對(duì)
print sum(predict_target == test_target)
#輸出準(zhǔn)確率 召回率 F值
from sklearn import metrics
print(metrics.classification_report(test_target, predict_target))
print(metrics.confusion_matrix(test_target, predict_target))
#獲取花卉測(cè)試數(shù)據(jù)集兩列數(shù)據(jù)集
X = test_data
L1 = [n[0] for n in X]
print L1
L2 = [n[1] for n in X]
print L2
#繪圖
import numpy as np
import matplotlib.pyplot as plt
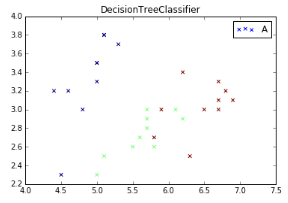
plt.scatter(L1, L2, c=predict_target, marker='x') #cmap=plt.cm.Paired
plt.title("DecisionTreeClassifier")
plt.show()
輸出結(jié)果如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
30
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 10
2 1.00 1.00 1.00 10
avg / total 1.00 1.00 1.00 30
[[10 0 0]
[ 0 10 0]
[ 0 0 10]]
繪制圖形如下所示:
3.補(bǔ)充知識(shí)
最后補(bǔ)充Skleaern官網(wǎng)上的一個(gè)決策樹的例子��,推薦大家學(xué)習(xí)����。
推薦地址:Plot the decision surface of a decision tree on the iris dataset
代碼如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 12 23:30:34 2016
@author: yxz15
"""
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# Parameters
n_classes = 3
plot_colors = "bry"
plot_step = 0.02
# Load data
iris = load_iris()
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
[1, 2], [1, 3], [2, 3]]):
# We only take the two corresponding features
X = iris.data[:, pair]
y = iris.target
# Train
clf = DecisionTreeClassifier().fit(X, y)
# Plot the decision boundary
plt.subplot(2, 3, pairidx + 1)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.xlabel(iris.feature_names[pair[0]])
plt.ylabel(iris.feature_names[pair[1]])
plt.axis("tight")
# Plot the training points
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
cmap=plt.cm.Paired)
plt.axis("tight")
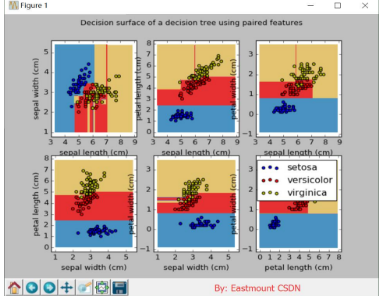
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend()
plt.show()
輸出如下所示:
繪制可視化決策樹圖部分��,總是報(bào)錯(cuò):
AttributeError: 'NoneType' object has no attribute 'write'
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
'''''
生成可視化訓(xùn)練好的決策樹
詳見:http://scikit-learn.org/stable/modules/tree.html
'''
from sklearn.externals.six import StringIO
from sklearn.tree import export_graphviz
with open("iris.dot", 'w') as f:
f = export_graphviz(clf, out_file=f)
import pydotplus
from sklearn import tree
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(clf, out_file="tree.dot",
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
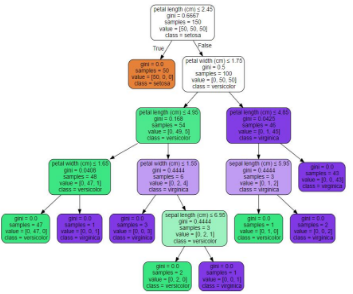
其中iris.dot數(shù)據(jù)如下所示:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
digraph Tree {
node [shape=box] ;
0 [label="X[2] <= 2.6\ngini = 0.6667\nsamples = 120\nvalue = [40, 40, 40]"] ;
1 [label="gini = 0.0\nsamples = 40\nvalue = [40, 0, 0]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="X[3] <= 1.75\ngini = 0.5\nsamples = 80\nvalue = [0, 40, 40]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
3 [label="X[2] <= 4.95\ngini = 0.2014\nsamples = 44\nvalue = [0, 39, 5]"] ;
2 -> 3 ;
4 [label="X[3] <= 1.65\ngini = 0.0512\nsamples = 38\nvalue = [0, 37, 1]"] ;
3 -> 4 ;
5 [label="gini = 0.0\nsamples = 37\nvalue = [0, 37, 0]"] ;
4 -> 5 ;
6 [label="gini = 0.0\nsamples = 1\nvalue = [0, 0, 1]"] ;
4 -> 6 ;
7 [label="X[3] <= 1.55\ngini = 0.4444\nsamples = 6\nvalue = [0, 2, 4]"] ;
3 -> 7 ;
8 [label="gini = 0.0\nsamples = 3\nvalue = [0, 0, 3]"] ;
7 -> 8 ;
9 [label="X[0] <= 6.95\ngini = 0.4444\nsamples = 3\nvalue = [0, 2, 1]"] ;
7 -> 9 ;
10 [label="gini = 0.0\nsamples = 2\nvalue = [0, 2, 0]"] ;
9 -> 10 ;
11 [label="gini = 0.0\nsamples = 1\nvalue = [0, 0, 1]"] ;
9 -> 11 ;
12 [label="X[2] <= 4.85\ngini = 0.054\nsamples = 36\nvalue = [0, 1, 35]"] ;
2 -> 12 ;
13 [label="X[1] <= 3.1\ngini = 0.4444\nsamples = 3\nvalue = [0, 1, 2]"] ;
12 -> 13 ;
14 [label="gini = 0.0\nsamples = 2\nvalue = [0, 0, 2]"] ;
13 -> 14 ;
15 [label="gini = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
13 -> 15 ;
16 [label="gini = 0.0\nsamples = 33\nvalue = [0, 0, 33]"] ;
12 -> 16 ;
}
想生成如下圖���,希望后面能修改��。也可以進(jìn)入shell下輸入命令:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
$ sudo apt-get install graphviz
$ dot -Tpng iris.dot -o tree.png # 生成png圖片
$ dot -Tpdf iris.dot -o tree.pdf # 生成pdf
最后文章對(duì)你有所幫助��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330