Python數(shù)據(jù)挖掘之Kmeans聚類數(shù)據(jù)分析及Anaconda介紹
這次課程主要講述一個關(guān)于Kmeans聚類的數(shù)據(jù)分析案例��,通過這個案例讓同學(xué)們簡單了解大數(shù)據(jù)分析的基本流程�����,以及使用Python實現(xiàn)相關(guān)的聚類分析����。
主要內(nèi)容包括:
1.Anaconda軟件的安裝過程及簡單配置
2.聚類及Kmeans算法介紹
3.案例分析:Kmeans實現(xiàn)運動員位置聚集
前文推薦:【Python數(shù)據(jù)挖掘課程】一.安裝Python及爬蟲入門介紹
希望這篇文章對你有所幫助,尤其是剛剛接觸數(shù)據(jù)挖掘以及大數(shù)據(jù)的同學(xué)���,同時準(zhǔn)備嘗試以案例為主的方式進行講解�����。如果文章中存在不足或錯誤的地方��,還請海涵~
一. Anaconda軟件安裝及使用步驟
前面兩節(jié)課我是通過Python命令行和IDLE工具進行介紹的��,但是里面的配置比較麻煩����,包括pip安裝���,selenium、lda各種第三方包的安裝���。
從這節(jié)課我準(zhǔn)備使用Anacaonda軟件來講解�����,它集成了各種Python的第三方包�����,尤其包括數(shù)據(jù)挖掘和數(shù)據(jù)分析常用的幾個包���。
1. 配置過程
首先簡單介紹安裝過程以及如何使用����。
安裝Anaconda
安裝過程如下所示:
安裝最好在C盤默認(rèn)路徑下(空間不大�,方便配置),同時不要使用中文路徑�����。
安裝完成后��,點擊“Finish”����。點擊Anaconda文件夾,包括這些exe執(zhí)行文件:
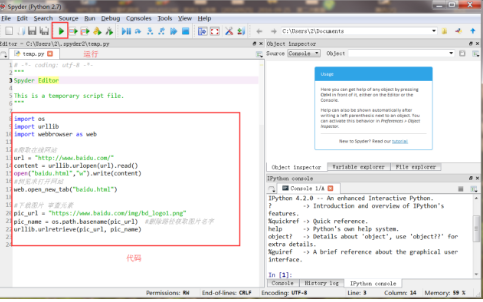
這里我們使用Spyder進行編寫Python程序�。運行如下所示,左邊是進行代碼編寫的�,右下角Console是輸出結(jié)果的地方����。
安裝第三方包
雖然Anaconda軟件集成了各種各樣的包�,但是還是缺少一些第三方包,需要通過調(diào)用pip或easy_install命令進行安裝��。
然后使用cd ..去到C盤根目錄���,cd去到Anaconda的Scripts目錄下��,輸入"pip install selenium"安裝selenium相應(yīng)的包��,"pip install lda"安裝lda包�����。
2. 機器學(xué)習(xí)常用包
下面這四個包通常用于Python數(shù)據(jù)挖掘和大數(shù)據(jù)分析的����,包括:
Scikit-Learn
Scikit-Learn是一個基于python的用于數(shù)據(jù)挖掘和數(shù)據(jù)分析的簡單且有效的工具���,它的基本功能主要被分為六個部分:分類(Classification)、回歸(Regression)���、聚類(Clustering)����、數(shù)據(jù)降維(Dimensionality Reduction)、模型選擇(Model Selection)��、數(shù)據(jù)預(yù)處理(Preprocessing)�。
NumPy
NumPy(Numeric Python)系統(tǒng)是Python的一種開源的數(shù)值計算擴展,一個用python實現(xiàn)的科學(xué)計算包�����。它提供了許多高級的數(shù)值編程工具����,如:矩陣數(shù)據(jù)類型、矢量處理�,以及精密的運算庫。專為進行嚴(yán)格的數(shù)字處理而產(chǎn)生�。
SciPy
SciPy (pronounced "Sigh Pie") 是一個開源的數(shù)學(xué)、科學(xué)和工程計算包���。它是一款方便����、易于使用、專為科學(xué)和工程設(shè)計的Python工具包�����,包括統(tǒng)計�、優(yōu)化、整合����、線性代數(shù)模塊、傅里葉變換�、信號和圖像處理、常微分方程求解器等等��。
Matplotlib
Matplotlib是一個Python的圖形框架����,類似于MATLAB和R語言。它是python最著名的繪圖庫�����,它提供了一整套和matlab相似的命令A(yù)PI��,十分適合交互式地進行制圖。而且也可以方便地將它作為繪圖控件��,嵌入GUI應(yīng)用程序中�����。
二. 聚類及Kmeans介紹
這部分內(nèi)容主要簡單介紹聚類的原理及Kmeans相關(guān)知識���。
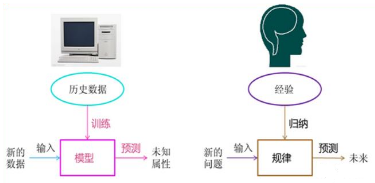
機器學(xué)習(xí)的基本思想,我還是介紹下面這張圖�����,非常經(jīng)典���。
這里講述聚類的部分�����,我簡單推薦"簡書-程sir"的文章����,簡單易懂���,很不錯���。
1. 分類與聚類
聚類
俗話說“物以類聚”�,其實從廣義上說��,聚類就是將數(shù)據(jù)集中在某些方面相似的數(shù)據(jù)成員放在一起�����。一個聚類就是一些數(shù)據(jù)實例的集合���,其中處于相同聚類中的數(shù)據(jù)元素彼此相似���,但是處于不同聚類中的元素彼此不同。
由于在聚類中那些表示數(shù)據(jù)類別的分類或分組信息是沒有的�����,即這些數(shù)據(jù)是沒有標(biāo)簽的����,所有聚類及時通常被成為無監(jiān)督學(xué)習(xí)(Unsupervised Learning)。
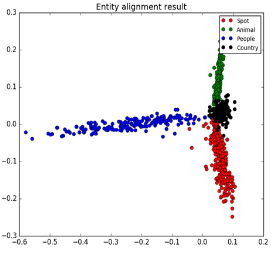
下圖是800篇文章���,每個點可以看成一篇文章����,然后對文本進行聚類分析,可以看到相同主題的文章是聚集在一起的����??偣菜膫€主題,紅色表示景區(qū)Spot��、藍色表示人物People�����、黑色表示國家Country����、綠色表示動物Animal。
分類
在理解聚類之前���,必須要先理解聚類和分類的區(qū)別�,簡單舉個例子�。
分類其實是從特定的數(shù)據(jù)中挖掘模式,作出判斷的過程。比如Gmail郵箱里有垃圾郵件分類器���,一開始的時候可能什么都不過濾�����,在日常使用過程中��,我人工對于每一封郵件點選“垃圾”或“不是垃圾”�,過一段時間���,Gmail就體現(xiàn)出一定的智能��,能夠自動過濾掉一些垃圾郵件了���。
這是因為在點選的過程中,其實是給每一條郵件打了一個“標(biāo)簽”�����,這個標(biāo)簽只有兩個值��,要么是“垃圾”�,要么“不是垃圾”�����,Gmail就會不斷研究哪些特點的郵件是垃圾�����,哪些特點的不是垃圾����,形成一些判別的模式���,這樣當(dāng)一封信的郵件到來,就可以自動把郵件分到“垃圾”和“不是垃圾”這兩個我們?nèi)斯ぴO(shè)定的分類的其中一個�����。
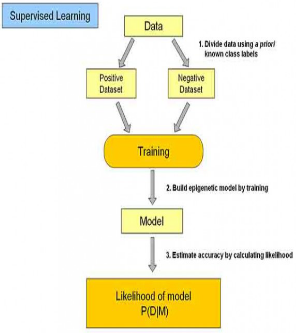
分類學(xué)習(xí)主要過程如下:
(1)訓(xùn)練數(shù)據(jù)集存在一個類標(biāo)記號�,判斷它是正向數(shù)據(jù)集(起積極作用,不垃圾郵件)��,還是負(fù)向數(shù)據(jù)集(起抑制作用�����,垃圾郵件);
(2)然后需要對數(shù)據(jù)集進行學(xué)習(xí)訓(xùn)練��,并構(gòu)建一個訓(xùn)練的模型���;
(3)通過該模型對預(yù)測數(shù)據(jù)集進預(yù)測�,并計算其結(jié)果的性能�。
聚類的的目的也是把數(shù)據(jù)分類,但是事先我是不知道如何去分的�����,完全是算法自己來判斷各條數(shù)據(jù)之間的相似性�����,相似的就放在一起����。在聚類的結(jié)論出來之前,我完全不知道每一類有什么特點����,一定要根據(jù)聚類的結(jié)果通過人的經(jīng)驗來分析,看看聚成的這一類大概有什么特點��。
總之,聚類主要是"物以類聚"��,通過相似性把相似元素聚集在一起���,它沒有標(biāo)簽����;而分類通過標(biāo)簽來訓(xùn)練得到一個模型��,對新數(shù)據(jù)集進行預(yù)測的過程��,其數(shù)據(jù)存在標(biāo)簽的�����。
2. Kmeans算法
該部分轉(zhuǎn)載簡書-程sir的文章:聚類�����、K-Means����、例子�、細(xì)節(jié)
K-Means是聚類算法中的最常用的一種�����,算法最大的特點是簡單��,好理解��,運算速度快�,但是只能應(yīng)用于連續(xù)型的數(shù)據(jù)�����,并且一定要在聚類前需要手工指定要分成幾類��。
下面����,我們描述一下K-means算法的過程,為了盡量不用數(shù)學(xué)符號�����,所以描述的不是很嚴(yán)謹(jǐn)��,大概就是這個意思,“物以類聚���、人以群分”:
1���、首先輸入k的值,即我們希望將數(shù)據(jù)集經(jīng)過聚類得到k個分組��。
2����、從數(shù)據(jù)集中隨機選擇k個數(shù)據(jù)點作為初始大哥(質(zhì)心,Centroid)
3�����、對集合中每一個小弟�����,計算與每一個大哥的距離(距離的含義后面會講)���,離哪個大哥距離近,就跟定哪個大哥��。
4���、這時每一個大哥手下都聚集了一票小弟���,這時候召開人民代表大會���,每一群選出新的大哥(其實是通過算法選出新的質(zhì)心)。
5����、如果新大哥和老大哥之間的距離小于某一個設(shè)置的閾值(表示重新計算的質(zhì)心的位置變化不大,趨于穩(wěn)定����,或者說收斂),可以認(rèn)為我們進行的聚類已經(jīng)達到期望的結(jié)果���,算法終止��。
6���、如果新大哥和老大哥距離變化很大,需要迭代3~5步驟��。
下面這個例子很好的,真心推薦大家學(xué)習(xí)他的博客�。
他搞了6個點,從圖上看應(yīng)該分成兩推兒�����,前三個點一堆兒����,后三個點是另一堆兒。現(xiàn)在手工執(zhí)行K-Means���,體會一下過程���,同時看看結(jié)果是不是和預(yù)期一致。
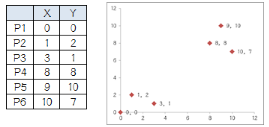
1.選擇初始大哥:
我們就選P1和P2
2.計算小弟和大哥的距離:
P3到P1的距離從圖上也能看出來(勾股定理)����,是√10 = 3.16;P3到P2的距離√((3-1)^2+(1-2)^2 = √5 = 2.24���,所以P3離P2更近����,P3就跟P2混���。同理��,P4�����、P5�����、P6也這么算���,如下:
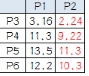
P3到P6都跟P2更近,所以第一次站隊的結(jié)果是:
? 組A:P1
? 組B:P2���、P3��、P4���、P5、P6
3.人民代表大會:
組A沒啥可選的���,大哥還是P1自己
組B有五個人����,需要選新大哥,這里要注意選大哥的方法是每個人X坐標(biāo)的平均值和Y坐標(biāo)的平均值組成的新的點��,為新大哥��,也就是說這個大哥是“虛擬的”����。
因此,B組選出新大哥的坐標(biāo)為:P哥((1+3+8+9+10)/5�����,(2+1+8+10+7)/5)=(6.2�,5.6)。
綜合兩組�,新大哥為P1(0,0)�,P哥(6.2,5.6)���,而P2-P6重新成為小弟�。
4.再次計算小弟到大哥的距離:
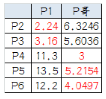
這時可以看到P2、P3離P1更近��,P4�、P5����、P6離P哥更近,第二次站隊的結(jié)果是:
? 組A:P1�、P2、P3
? 組B:P4���、P5����、P6(虛擬大哥這時候消失)
5.第二屆人民代表大會:
按照上一屆大會的方法選出兩個新的虛擬大哥:P哥1(1.33��,1) P哥2(9���,8.33)��,P1-P6都成為小弟���。
6.第三次計算小弟到大哥的距離:
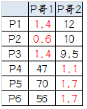
這時可以看到P1���、P2、P3離P哥1更近���,P4��、P5�、P6離P哥2更近����,所以第二次站隊的結(jié)果是:
? 組A:P1、P2�����、P3
? 組B:P4�、P5、P6
我們發(fā)現(xiàn)����,這次站隊的結(jié)果和上次沒有任何變化了,說明已經(jīng)收斂�����,聚類結(jié)束,聚類結(jié)果和我們最開始設(shè)想的結(jié)果完全一致����。
三. 案例分析:Kmeans聚類運動員數(shù)據(jù)
1. 數(shù)據(jù)集
現(xiàn)在存在下面的數(shù)據(jù)集,是籃球球員比賽的數(shù)據(jù)�。
數(shù)據(jù)集地址:KEEL-dataset - Basketball data set
該數(shù)據(jù)集主要包括5個特征(Features),共96行數(shù)據(jù)���。

特征描述:共5個特征,每分鐘助攻數(shù)�����、運動員身高�����、運動員出場時間����、運動員年齡和每分鐘得分?jǐn)?shù)。

20行數(shù)據(jù)集如下:
[html] view plain copy 在CODE上查看代碼片派生到我的代碼片
assists_per_minute height time_played age points_per_minute
0 0.0888 201 36.02 28 0.5885
1 0.1399 198 39.32 30 0.8291
2 0.0747 198 38.80 26 0.4974
3 0.0983 191 40.71 30 0.5772
4 0.1276 196 38.40 28 0.5703
5 0.1671 201 34.10 31 0.5835
6 0.1906 193 36.20 30 0.5276
7 0.1061 191 36.75 27 0.5523
8 0.2446 185 38.43 29 0.4007
9 0.1670 203 33.54 24 0.4770
10 0.2485 188 35.01 27 0.4313
11 0.1227 198 36.67 29 0.4909
12 0.1240 185 33.88 24 0.5668
13 0.1461 191 35.59 30 0.5113
14 0.2315 191 38.01 28 0.3788
15 0.0494 193 32.38 32 0.5590
16 0.1107 196 35.22 25 0.4799
17 0.2521 183 31.73 29 0.5735
18 0.1007 193 28.81 34 0.6318
19 0.1067 196 35.60 23 0.4326
20 0.1956 188 35.28 32 0.4280
需求:現(xiàn)在需要通過運動員的數(shù)據(jù)����,判斷他是什么位置�。
如果某些運動員得分高��,他可能是得分后衛(wèi)����;如果某些運動員身高高或籃板多,他可能是中鋒���;助攻高可能是控衛(wèi)�����。
2. 代碼
這里我僅僅使用兩列數(shù)據(jù)�,助攻數(shù)和得分?jǐn)?shù)進行實驗���,相當(dāng)于20*2的矩陣����,其中輸出y_pred結(jié)果表示聚類的類標(biāo)��。類簇數(shù)設(shè)置為3��,類標(biāo)位0、1���、2��,它也是與20個球員數(shù)據(jù)一一對應(yīng)的�。
Sklearn機器學(xué)習(xí)包中導(dǎo)入了KMeans聚類����,同時需要注意Matplotlib包繪制圖形的過程。代碼如下��,并包括詳細(xì)注釋:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
"""
第一部分:導(dǎo)入包
從sklearn.cluster機器學(xué)習(xí)聚類包中導(dǎo)入KMeans聚類
"""
# coding=utf-8
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
"""
第二部分:數(shù)據(jù)集
X表示二維矩陣數(shù)據(jù)�,籃球運動員比賽數(shù)據(jù)
總共20行�����,每行兩列數(shù)據(jù)
第一列表示球員每分鐘助攻數(shù):assists_per_minute
第二列表示球員每分鐘得分?jǐn)?shù):points_per_minute
"""
X = [[0.0888, 0.5885],
[0.1399, 0.8291],
[0.0747, 0.4974],
[0.0983, 0.5772],
[0.1276, 0.5703],
[0.1671, 0.5835],
[0.1906, 0.5276],
[0.1061, 0.5523],
[0.2446, 0.4007],
[0.1670, 0.4770],
[0.2485, 0.4313],
[0.1227, 0.4909],
[0.1240, 0.5668],
[0.1461, 0.5113],
[0.2315, 0.3788],
[0.0494, 0.5590],
[0.1107, 0.4799],
[0.2521, 0.5735],
[0.1007, 0.6318],
[0.1067, 0.4326],
[0.1956, 0.4280]
]
#輸出數(shù)據(jù)集
print X
"""
第三部分:KMeans聚類
clf = KMeans(n_clusters=3) 表示類簇數(shù)為3�,聚成3類數(shù)據(jù),clf即賦值為KMeans
y_pred = clf.fit_predict(X) 載入數(shù)據(jù)集X�����,并且將聚類的結(jié)果賦值給y_pred
"""
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
#輸出完整Kmeans函數(shù)����,包括很多省略參數(shù)
print(clf)
#輸出聚類預(yù)測結(jié)果�,20行數(shù)據(jù)�,每個y_pred對應(yīng)X一行或一個球員,聚成3類�,類標(biāo)為0、1�����、2
print(y_pred)
"""
第四部分:可視化繪圖
Python導(dǎo)入Matplotlib包����,專門用于繪圖
import matplotlib.pyplot as plt 此處as相當(dāng)于重命名,plt用于顯示圖像
"""
import numpy as np
import matplotlib.pyplot as plt
#獲取第一列和第二列數(shù)據(jù) 使用for循環(huán)獲取 n[0]表示X第一列
x = [n[0] for n in X]
print x
y = [n[1] for n in X]
print y
#繪制散點圖 參數(shù):x橫軸 y縱軸 c=y_pred聚類預(yù)測結(jié)果 marker類型 o表示圓點 *表示星型 x表示點
plt.scatter(x, y, c=y_pred, marker='x')
#繪制標(biāo)題
plt.title("Kmeans-Basketball Data")
#繪制x軸和y軸坐標(biāo)
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
#設(shè)置右上角圖例
plt.legend(["A","B","C"])
#顯示圖形
plt.show()
注意:后面會介紹如何讀取數(shù)據(jù)進行聚類的���。
聚類核心代碼:
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
繪圖核心代碼:
import matplotlib.pyplot as plt
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans-Basketball Data")
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
plt.show()
3. 運行結(jié)果
運行結(jié)果如下所示:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#數(shù)據(jù)集
[[0.0888, 0.5885], [0.1399, 0.8291], [0.0747, 0.4974], [0.0983, 0.5772], [0.1276, 0.5703], [0.1671, 0.5835], [0.1906, 0.5276], [0.1061, 0.5523], [0.2446, 0.4007], [0.167, 0.477], [0.2485, 0.4313], [0.1227, 0.4909], [0.124, 0.5668], [0.1461, 0.5113], [0.2315, 0.3788], [0.0494, 0.559], [0.1107, 0.4799], [0.2521, 0.5735], [0.1007, 0.6318], [0.1067, 0.4326], [0.1956, 0.428]]
#KMeans函數(shù)
KMeans(copy_x=True, init='k-means++', max_iter=300, n_clusters=3, n_init=10,
n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001,
verbose=0)
#y_pred 預(yù)測的聚類類標(biāo)結(jié)果
[0 2 0 0 0 0 0 0 1 1 1 0 0 0 1 0 0 0 0 1 1]
#獲取x���、y坐標(biāo)
[0.0888, 0.1399, 0.0747, 0.0983, 0.1276, 0.1671, 0.1906, 0.1061, 0.2446, 0.167, 0.2485, 0.1227, 0.124, 0.1461, 0.2315, 0.0494, 0.1107, 0.2521, 0.1007, 0.1067, 0.1956]
[0.5885, 0.8291, 0.4974, 0.5772, 0.5703, 0.5835, 0.5276, 0.5523, 0.4007, 0.477, 0.4313, 0.4909, 0.5668, 0.5113, 0.3788, 0.559, 0.4799, 0.5735, 0.6318, 0.4326, 0.428]
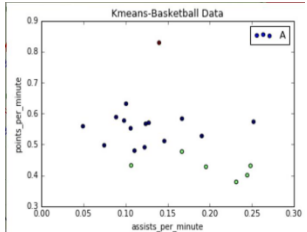
輸出圖形如下所示:
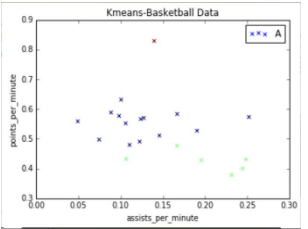
如果設(shè)置marker='o',輸出圓形�,可以看到紅色點很高,他得分和助攻都比較高��,相當(dāng)于籃球里面的"喬丹"���,然后中間一部分���,右下角一部分助攻很高����、得分低���,可能是控衛(wèi)��。當(dāng)然數(shù)據(jù)集越多����,聚類的效果越好���。
常見問題:
1�����、安裝Anaconda不能使用中文路徑,以及電腦名稱為中文��;
2����、Spyder如何顯示中文���,而不是"口口口"亂碼,需要改Fonts��;
3��、Matplotlib如何顯示顏色����,定義樣式等;
4�、如何讀取數(shù)據(jù),賦值給變量�,在讓其顯示。
希望這篇文章對你有所幫助��,主要是介紹一個基于Python的Kmeans聚類案例���,后面會陸續(xù)詳細(xì)介紹各種知識���。非常想上好這門課,因為是我的專業(yè)方向�����,另外學(xué)生們真的好棒,好認(rèn)真�����,用手機錄像��、問問題�����、配環(huán)境等等�,只要有用心的學(xué)生,我定不負(fù)你�����!同時��,這節(jié)課的思路好點了����,摸著石頭過馬路�����,需要慢慢學(xué)吧,但還是挺享受的�,畢竟9800,哈哈哈��!
最后提供籃球的完整數(shù)據(jù)集:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
@relation basketball
@attribute assists_per_minuteReal real [0.0494, 0.3437]
@attribute heightInteger integer [160, 203]
@attribute time_playedReal real [10.08, 40.71]
@attribute ageInteger integer [22, 37]
@attribute points_per_minuteReal real [0.1593, 0.8291]
@inputs assists_per_minuteReal, heightInteger, time_playedReal, ageInteger, points_per_minuteReal
@data
0.0888, 201, 36.02, 28, 0.5885
0.1399, 198, 39.32, 30, 0.8291
0.0747, 198, 38.8, 26, 0.4974
0.0983, 191, 40.71, 30, 0.5772
0.1276, 196, 38.4, 28, 0.5703
0.1671, 201, 34.1, 31, 0.5835
0.1906, 193, 36.2, 30, 0.5276
0.1061, 191, 36.75, 27, 0.5523
0.2446, 185, 38.43, 29, 0.4007
0.167, 203, 33.54, 24, 0.477
0.2485, 188, 35.01, 27, 0.4313
0.1227, 198, 36.67, 29, 0.4909
0.124, 185, 33.88, 24, 0.5668
0.1461, 191, 35.59, 30, 0.5113
0.2315, 191, 38.01, 28, 0.3788
0.0494, 193, 32.38, 32, 0.559
0.1107, 196, 35.22, 25, 0.4799
0.2521, 183, 31.73, 29, 0.5735
0.1007, 193, 28.81, 34, 0.6318
0.1067, 196, 35.6, 23, 0.4326
0.1956, 188, 35.28, 32, 0.428
0.1828, 191, 29.54, 28, 0.4401
0.1627, 196, 31.35, 28, 0.5581
0.1403, 198, 33.5, 23, 0.4866
0.1563, 193, 34.56, 32, 0.5267
0.2681, 183, 39.53, 27, 0.5439
0.1236, 196, 26.7, 34, 0.4419
0.13, 188, 30.77, 26, 0.3998
0.0896, 198, 25.67, 30, 0.4325
0.2071, 178, 36.22, 30, 0.4086
0.2244, 185, 36.55, 23, 0.4624
0.3437, 185, 34.91, 31, 0.4325
0.1058, 191, 28.35, 28, 0.4903
0.2326, 185, 33.53, 27, 0.4802
0.1577, 193, 31.07, 25, 0.4345
0.2327, 185, 36.52, 32, 0.4819
0.1256, 196, 27.87, 29, 0.6244
0.107, 198, 24.31, 34, 0.3991
0.1343, 193, 31.26, 28, 0.4414
0.0586, 196, 22.18, 23, 0.4013
0.2383, 185, 35.25, 26, 0.3801
0.1006, 198, 22.87, 30, 0.3498
0.2164, 193, 24.49, 32, 0.3185
0.1485, 198, 23.57, 27, 0.3097
0.227, 191, 31.72, 27, 0.4319
0.1649, 188, 27.9, 25, 0.3799
0.1188, 191, 22.74, 24, 0.4091
0.194, 193, 20.62, 27, 0.3588
0.2495, 185, 30.46, 25, 0.4727
0.2378, 185, 32.38, 27, 0.3212
0.1592, 191, 25.75, 31, 0.3418
0.2069, 170, 33.84, 30, 0.4285
0.2084, 185, 27.83, 25, 0.3917
0.0877, 193, 21.67, 26, 0.5769
0.101, 193, 21.79, 24, 0.4773
0.0942, 201, 20.17, 26, 0.4512
0.055, 193, 29.07, 31, 0.3096
0.1071, 196, 24.28, 24, 0.3089
0.0728, 193, 19.24, 27, 0.4573
0.2771, 180, 27.07, 28, 0.3214
0.0528, 196, 18.95, 22, 0.5437
0.213, 188, 21.59, 30, 0.4121
0.1356, 193, 13.27, 31, 0.2185
0.1043, 196, 16.3, 23, 0.3313
0.113, 191, 23.01, 25, 0.3302
0.1477, 196, 20.31, 31, 0.4677
0.1317, 188, 17.46, 33, 0.2406
0.2187, 191, 21.95, 28, 0.3007
0.2127, 188, 14.57, 37, 0.2471
0.2547, 160, 34.55, 28, 0.2894
0.1591, 191, 22.0, 24, 0.3682
0.0898, 196, 13.37, 34, 0.389
0.2146, 188, 20.51, 24, 0.512
0.1871, 183, 19.78, 28, 0.4449
0.1528, 191, 16.36, 33, 0.4035
0.156, 191, 16.03, 23, 0.2683
0.2348, 188, 24.27, 26, 0.2719
0.1623, 180, 18.49, 28, 0.3408
0.1239, 180, 17.76, 26, 0.4393
0.2178, 185, 13.31, 25, 0.3004
0.1608, 185, 17.41, 26, 0.3503
0.0805, 193, 13.67, 25, 0.4388
0.1776, 193, 17.46, 27, 0.2578
0.1668, 185, 14.38, 35, 0.2989
0.1072, 188, 12.12, 31, 0.4455
0.1821, 185, 12.63, 25, 0.3087
0.188, 180, 12.24, 30, 0.3678
0.1167, 196, 12.0, 24, 0.3667
0.2617, 185, 24.46, 27, 0.3189
0.1994, 188, 20.06, 27, 0.4187
0.1706, 170, 17.0, 25, 0.5059
0.1554, 183, 11.58, 24, 0.3195
0.2282, 185, 10.08, 24, 0.2381
0.1778, 185, 18.56, 23, 0.2802
0.1863, 185, 11.81, 23, 0.381
0.1014, 193, 13.81, 32, 0.1593
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330