CDA數(shù)據(jù)分析師 出品
今年的第92屆奧斯卡可謂是大片云集,入圍的影片不僅藝術性極高��,而且市場口碑都極佳�����。當中有黑幫片《愛爾蘭人》���,經典IP《小婦人》��,昆汀的《好萊塢往事》��,戰(zhàn)爭片《1917》�����,另類超級英雄片《小丑》等等��,真正稱得上是神仙打架�。

可誰也沒想到,當中韓國電影《寄生蟲》爆冷成為了最大的贏家�。
這部由韓國導演奉俊昊自編自導的影片,一舉拿下最佳影片���、最佳導演��、最佳原創(chuàng)劇本和最佳國際電影四座奧斯卡獎杯���,創(chuàng)造歷史成為奧斯卡史上首部非英語最佳影片。

作為曾經戰(zhàn)斗在與韓國爭奪端午節(jié)到底是誰發(fā)明的一線鍵盤俠���,C君一下子吃了一筐檸檬���,酸到不行。今天我們就來聊聊韓國的這筐檸檬�,不對,這部電影《寄生蟲》���。

01
不一樣的奧斯卡
原汁原味的韓國電影
說到《寄生蟲》橫掃本屆奧斯卡�,你可能會說我們有李安啊��,不是也拿獎過嗎�?要知道作為奧斯卡的寵兒,李安導演在2001年憑借《臥虎藏龍》獲得奧斯卡外語片,在2006年和2013年各憑借《斷背山》和《少年派的奇幻漂流》收獲最佳導演獎�,而還未獲得最佳影片的殊榮。
這次韓國導演奉俊昊憑借《寄生蟲》拿下四座大獎�,直接超越了李安導演的記錄。
無論我們怎么說�����,李安拿最佳導演的那兩部電影都是屬于好萊塢電影��,李安甚至都該歸為好萊塢的導演���,英語說的賊溜。
但反觀《寄生蟲》����,扎扎實實的一部韓國電影,韓國人拍韓國事兒���,從導演到演員�,從主演到配角�����,愛喝酒的奉俊昊導演甚至連英語都不會說(頒獎詞還得要現(xiàn)場翻譯幫忙),而他之前的作品也都是韓國本土的電影���。

他自己也在臺上發(fā)表領獎感言的時候說:
“我要感謝昆汀把我的電影放到他的觀影表單里面����,讓全世界更多人知道了我的作品����。”
但就是這樣一個韓國本土導演�����,在今年大片云集的情況下拿走份量最重的4個奧斯卡小金人��,尤其是歷史上首次囊括最佳外語片和最佳電影�����,也為韓國第一次拿到了奧斯卡���,絕對的硬實力���。
02
近年頻頻開掛的
韓國電影
回顧這幾年���,韓國電影就像開掛一樣,每年都會出爆款���。比如警匪片《惡人傳》�����;根據(jù)村上春樹小說改編的《燃燒》;揭露殘酷社會現(xiàn)實的《熔爐》幾乎部部口碑炸裂��,在口味苛刻的豆瓣上都在7.7分以上�。

奉俊昊導演其實在韓國早已家喻戶曉,除了《寄生蟲》��,他的這些作品也都耳熟能詳����。
2006年的《漢江怪物》(豆瓣7.4分)是當時韓國少見的科幻電影,票房自上映以來整整保持了六年韓國票房冠軍之位直至2012年才被《盜賊同盟》趕超���。
2013年的《雪國列車》(豆瓣7.4分)該片的故事發(fā)生在一個被氣候變化毀掉的未來世界��,所有的生物都擠在一列環(huán)球行駛的火車上��。該片首日在韓國上映就刷新了單日最高票房紀錄�����。
而2003年的《殺人回憶》更是在豆瓣評分高達8.8分����,是許多影迷的必刷片,也影響了之火許多同類型影片����。同時,這部影片改編自真實事件華城連環(huán)殺人案���,公映時引起了強烈的社會探討���,令人欣慰的是在2019年9月《殺人回憶》的殺手原型也被緝拿歸案。

讓我們回到《寄生蟲》這部影片����,榮獲這么多大獎,這部電影到底好在哪兒����?
03
《寄生蟲》講的是什么故事
《寄生蟲》主要講述的是�����,住在廉價的半地下室出租房里的一家四口�,原本全都是無業(yè)游民����。在長子基宇隱瞞真實學歷,去一戶住著豪宅的富有家庭擔任家教�����,之后他更是想方設法把父親����、母親和妹妹全都弄到這戶人家工作����,過上了“寄生”一般的生活…


《寄生蟲》表面上反映的是韓國社會的真實情景,內核上卻展現(xiàn)了所有社會都存在的階級矛盾這一主題��。從劇本設定上���,窮人一家混進富人一家寄生于此�,然后發(fā)現(xiàn)早有另一家寄居籬下,兩家窮人為了爭奪寄生權你死我活����,整個故事從開始的搞笑到最后的慘劇,沖突與轉折中充滿了黑色幽默�����。即使是韓語的故事����,也能幾乎讓所有的觀影者都產生理解和共鳴,這不是一部電影����,這就是一部涵蓋了社會道德和人與人關系的文學作品。
當我們在深刻分析�����,一本正經地寫影評的時候�����,愛喝酒的奉俊昊導演����,是這么調侃:
記者問:“為什么《寄生蟲》這部電影會讓這么多的觀眾產生共鳴����?”
奉俊昊回答:
“我聽到很多人說���,這部電影講述的是有關窮人富人以及資本主義����,這也是為什么很多人能從電影中找到共鳴的原因����。
當然這種說法沒錯�,但我認為主要原因是電影開頭兩個年輕人��,拿著手機到處找wifi���,全世界的人不都是這樣嗎?很多觀眾從開頭就找到了共鳴����。”
真是你拿了大獎����,說什么都好聽����。
04
那觀眾又怎么看呢��?
我們爬取了《寄生蟲》在豆瓣上的影評數(shù)據(jù)�����。整個數(shù)據(jù)分析的過程分為三步:
· 獲取數(shù)據(jù)
· 數(shù)據(jù)預處理
· 數(shù)據(jù)可視化
以下是具體的步驟和代碼實現(xiàn):
獲取數(shù)據(jù)
豆瓣從2017.10月開始全面限制爬取數(shù)據(jù)��,非登錄狀態(tài)下最多獲取200條����,登錄狀態(tài)下最多為500條,本次我們共獲取數(shù)據(jù)521條�。
為了解決登錄的問題,本次使用Selenium框架發(fā)起網頁請求�,然后使用xpath進行數(shù)據(jù)的提取。
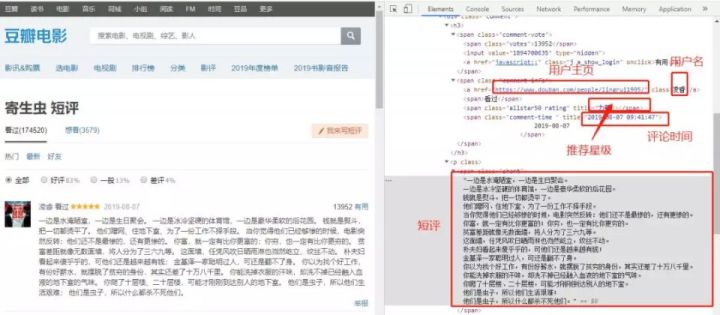
如下圖所示��,本此數(shù)據(jù)爬取主要獲取的內容有:
· 評論用戶ID
· 評論用戶主頁
· 評論內容
· 評分星級
· 評論日期
· 用戶所在城市
代碼實現(xiàn):
# 導入所需包
import numpy as np
import pandas as pd
import time
import requests
import re
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
def login_douban:
'''功能:自動登錄豆瓣網站'''
global browser # 設置為全局變量
browser = webdriver.Chrome
# 進入登錄頁面
login_url = 'https://accounts.douban.com/passport/login?source=movie'
browser.get(login_url)
# 點擊密碼登錄
browser.find_element_by_class_name('account-tab-account').click
# 輸入賬號和密碼
username = browser.find_element_by_id('username')
username.send_keys('你的用戶名')
password = browser.find_element_by_id('password')
password.send_keys('你的密碼')
# 點擊登錄
browser.find_element_by_class_name('btn-account').click
def get_one_page(url):
'''功能:傳入url���,豆瓣電影一頁的短評信息'''
# 進入短評頁
browser.get(url)
# 獲取網頁
browser.get(url)
# 解析網頁
html = etree.HTML(browser.page_source)
# 提取用戶名
user_name = html.xpath('//div/div[2]/h3/span[2]/a/text')
# 提取用戶主頁
user_url = html.xpath('//div/div[2]/h3/span[2]/a/@href')
# 提取推薦星級
star = html.xpath('//div/div[2]/h3/span[2]/span[2]/@title')
# 提取評論時間
comment_time = html.xpath('//div/div[2]/h3/span[2]/span[3]/@title')
# 星級和評論時間bug處理��,有的用戶沒有填寫推薦星級
star_dealed =
for i in range(len(user_name)):
if re.compile(r'(\d)').match(star[i]) is not None:
star_dealed.append('還行')
# 相同的索引位置插入一個時間
comment_time.insert(i, star[i])
else:
star_dealed.append(star[i])
# 提取短評信息
short_comment = html.xpath('//div/div[2]/p/span/text')
# 提取投票次數(shù)
votes = html.xpath('//div/div[2]/h3/span[1]/span/text')
# 存儲數(shù)據(jù)
df = pd.DataFrame({'user_name': user_name,
'user_url': user_url,
'star': star_dealed,
'comment_time': comment_time,
'short_comment': short_comment,
'votes': votes})
return df
def get_25_page(movie_id):
'''功能:傳入電影ID�,獲取豆瓣電影25頁的短評信息(目前所能獲取的最大頁數(shù))'''
# 創(chuàng)建空的DataFrame
df_all = pd.DataFrame
# 循環(huán)翻頁
for i in range(25):
url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&sort=new_score&status=P".format(movie_id,i*20)
print('我正在抓取第{}頁'.format(i+1), end='\r')
# 調用函數(shù)
df_one = get_one_page(url)
# 循環(huán)追加
df_all = df_all.append(df_one, ignore_index=True)
# 休眠一秒
time.sleep(1)
return df_all
if __name__ == '__main__':
# 先運行登錄函數(shù)
login_douban
# 休眠兩秒
time.sleep(2)
# 再運行循環(huán)翻頁函數(shù)
movie_id = 27010768 # 寄生蟲
df_all = get_25_page(movie_id)
爬取出來的數(shù)據(jù)以數(shù)據(jù)框的形式存儲,結果如下所示:
從用戶主頁的地址可以獲取到用戶的城市信息��,這一步比較簡單����,此處的代碼省略。
數(shù)據(jù)預處理
對于獲取到的數(shù)據(jù)���,我們需要進行以下的處理以方便后續(xù)分析:
· 推薦星級:轉換為1-5分�。
· 評論時間:轉換為時間類型����,提取出日期信息
· 城市:有城市空缺、海外城市�、亂寫和pyecharts尚不支持的城市,需要進行處理
· 短評信息:需要進行分詞和提取關鍵詞
代碼實現(xiàn):
# 定義轉換函數(shù)
def transform_star(x):
if x == '力薦':
return 5
elif x == '推薦':
return 4
elif x == '還行':
return 3
elif x == '較差':
return 2
else:
return 1
# 星級轉換
df_all['star'] = df_all.star.map(lambda x:transform_star(x))
# 處理日期數(shù)據(jù)
df_all['comment_time'] = pd.to_datetime(df_all.comment_time)
# 定義函數(shù)-獲取短評信息關鍵詞
def get_comment_word(df):
'''功能:傳入df�����,提取短評信息關鍵詞'''
import jieba.analyse
import os
# 集合形式存儲-去重
stop_words = set
# 加載停用詞
cwd = os.getcwd
stop_words_path = cwd + '\\stop_words.txt'
with open(stop_words_path, 'r', encoding='utf-8') as sw:
for line in sw.readlines:
stop_words.add(line.strip)
# 添加停用詞
stop_words.add('6.3')
stop_words.add('一張')
stop_words.add('這部')
stop_words.add('一部')
stop_words.add('寄生蟲')
stop_words.add('一家')
stop_words.add('一家人')
stop_words.add('電影')
stop_words.add('只能')
stop_words.add('感覺')
stop_words.add('全片')
stop_words.add('表達')
stop_words.add('真的')
stop_words.add('本片')
stop_words.add('劇作')
# 合并評論信息
df_comment_all = df['short_comment'].str.cat
# 使用TF-IDF算法提取關鍵詞
word_num = jieba.analyse.extract_tags(df_comment_all, topK=100, withWeight=True, allowPOS=)
# 做一步篩選
word_num_selected =
# 篩選掉停用詞
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
else:
pass
return word_num_selected
key_words = get_comment_word(df_all)
key_words = pd.DataFrame(key_words, columns=['words','num'])
數(shù)據(jù)可視化
用Python做可視化分析的工具很多�,目前比較好用可以實現(xiàn)動態(tài)可視化的是pyecharts。我們主要對以下幾個方面信息進行可視化分析:
· 評論總體評分分布
· 評分時間走勢
· 城市分布
· 評論內容
總體評分分布
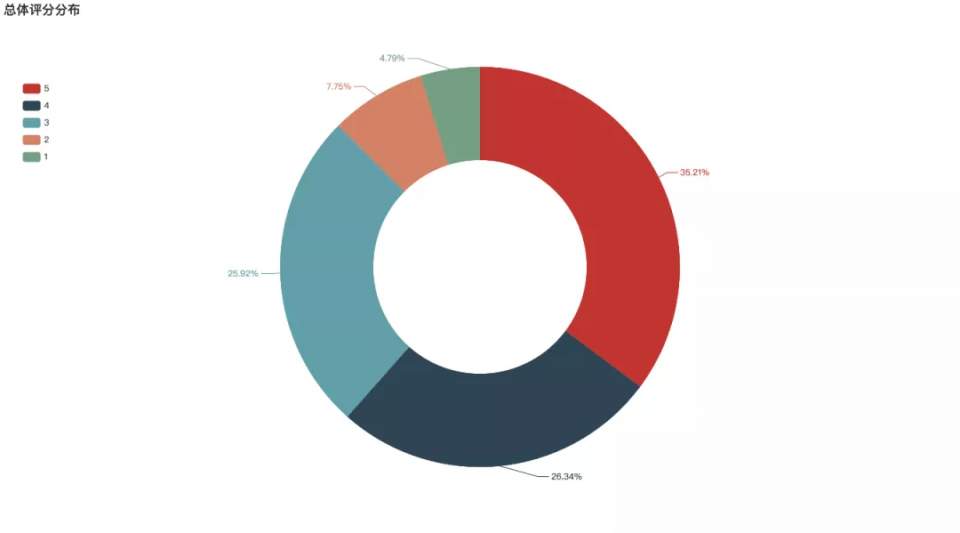
截止到目前為止����,《寄生蟲》在豆瓣電影上有超過63萬人評價,網站上的總體評分為8.7分�,這個分數(shù)無疑是非常高的。好于97% 喜劇片�����,好于94% 劇情片�����。

從評分星級來看���,5星的占比最高�����,占總數(shù)的35.21%�,4星以上的比重占到50%以上�����,給到3星以下的比重比較少,僅10%不到�����。
代碼實現(xiàn):
# 總體評分
score_perc = df_all.star.value_counts / df_all.star.value_counts.sum
score_perc = np.round(score_perc*100,2)
# 導入所需包
from pyecharts.faker import Faker
from pyecharts import options as opts
from pyecharts.charts import Pie, Page
# 繪制柱形圖
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add("",
[*zip(score_perc.index, score_perc.values)],
radius=["40%","75%"])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='總體評分分布'),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
toolbox_opts=opts.ToolboxOpts)
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%"))
pie1.render('總體評分分布.html')
評分時間走勢圖
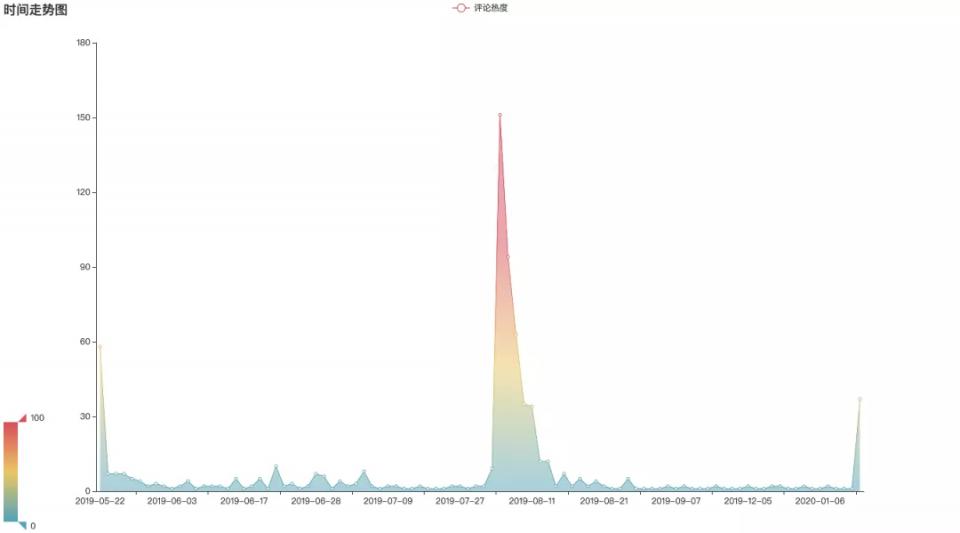
評論的熱度在2019年8月份最高���?���?赡苁浅鼍W上資源的時候吧...
代碼實現(xiàn):
time = df_all.comment_date.value_counts
time.sort_index(inplace=True)
from pyecharts.charts import Line
# 繪制時間走勢圖
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
line1.add_xaxis(time.index.tolist)
line1.add_yaxis('評論熱度', time.values.tolist, areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False))
line1.set_global_opts(title_opts=opts.TitleOpts(title="時間走勢圖"),
toolbox_opts=opts.ToolboxOpts,
visualmap_opts=opts.VisualMapOpts)
line1.render('評論時間走勢圖.html')
評論用戶城市分布
接下來分析了評論者所在的城市分布�。
從觀影評價城市來看,北京占到絕大多數(shù)��,其次是上海�����。這跟微博統(tǒng)計的數(shù)據(jù)基本一致����。

代碼實現(xiàn):
# 國內城市top10
city_top10 = df_all.city_dealed.value_counts[:12]
city_top10.drop('國外', inplace=True)
city_top10.drop('未知', inplace=True)
from pyecharts.charts import Bar
# 條形圖
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(city_top10.index.tolist)
bar1.add_yaxis("城市", city_top10.values.tolist)
bar1.set_global_opts(title_opts=opts.TitleOpts(title="評論者Top10城市分布"),
toolbox_opts=opts.ToolboxOpts,
visualmap_opts=opts.VisualMapOpts)
bar1.render('評論者Top10城市分布條形圖.html')
評分詞云圖

代碼實現(xiàn):
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType, ThemeType
word = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
word.add("", [*zip(key_words.words, key_words.num)],
word_size_range=[20, 200], shape='diamond')
word.set_global_opts(title_opts=opts.TitleOpts(title="寄生蟲電影評論詞云圖"),
toolbox_opts=opts.ToolboxOpts)
word.render('寄生蟲電影評論詞云圖.html')
從電影短評的分詞來看,主要集中對“奉俊昊”導演的探討上��。畢竟在此之前���,讓大家說出一個韓國導演的名字���,大家還是有點摸不著頭腦的,就知道殺人回憶����、漢江怪物挺好看。
其次關于“窮人”“富人”“階級”等影片故事內核的關注度也很高����。
這里面就有一句大家最常提及的臺詞,引人深思:不是“有錢卻很善良”�����,是“有錢所以善良”��,懂嗎�?如果我有這些錢的話,我也會很善良�����,超級善良����。
與此同時針對影片的劇情“反轉”�����,“鏡頭”等拍攝手法也是觀眾的焦點��。
很有意思的是���,看本片時觀眾還會跟《燃燒》等韓國電影進行比較。這里也推薦大家可以去看看《燃燒》��,也是非常不錯的一部作品�����。
結語
最后��,被檸檬酸到不行的我們����,可以繼續(xù)當個鍵盤俠去羨慕一下韓國的電影審查制度。但最根本的還是年輕的鍵盤俠們真正長大到要去拍電影���、審查電影的時候����,能不能真正如自己所說的那般帶來改變。當然也可以學學中國足球����,我們是不是可以歸化一個韓國導演�����?
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�����;












 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330