作者 | CDA數(shù)據(jù)分析師
我們把菜品挑選出來以后�,就可以開始切菜了。比如要做涼拌黃瓜絲��,把黃瓜找出來以后����,那就可以把黃瓜切成絲了����。
一���、數(shù)值替換
數(shù)值替換就是將數(shù)值A(chǔ)替換成B�,可以用在異常值替換處理�、缺失值填充處理中。主要有一對一替換��、多對一替換�����、多對多替換三種替換方法����。
1、一對一替換
一對一替換是將某一塊區(qū)域中的一個值全部替換成另一個值��。已知現(xiàn)在有一個年齡值是240���,很明顯這是一個異常值�,我們要把它替換成一個正常范圍內(nèi)的年齡值(用正常年齡的均值33)�,怎么實現(xiàn)呢?
(1)Excel實現(xiàn)
在Excel中對某個值進行替換�,首先要把待替換的區(qū)域選中,如果只是替換某一列中的值���,只需要選中這一列即可�����;如果要在這一片區(qū)域中進行替換��,那么拖動鼠標(biāo)選中這一片區(qū)域�����。然后依次單擊編輯菜單欄中的查找和選擇>���;替換選項(如下圖所示)即可調(diào)出替換界面。使用快捷鍵Ctrl+H也可以調(diào)出替換界面�。
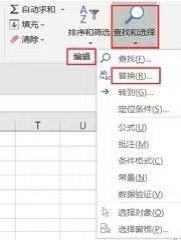
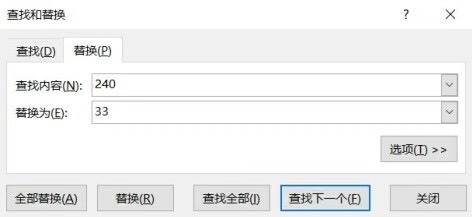
下圖為替換界面,分別輸入查找內(nèi)容和替換內(nèi)容���,然后根據(jù)需要單擊全部替換或者替換全部即可���。
(2)Python實現(xiàn)
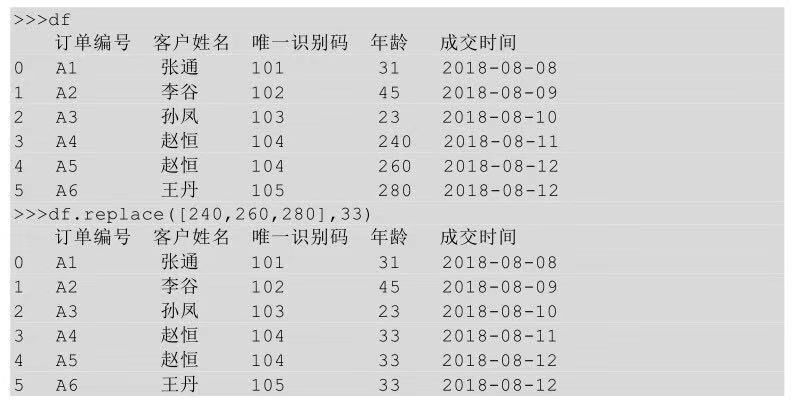
在python中對某個值進行替換利用的是replace()方法���,replace(A,B)表示將A替換成B�。
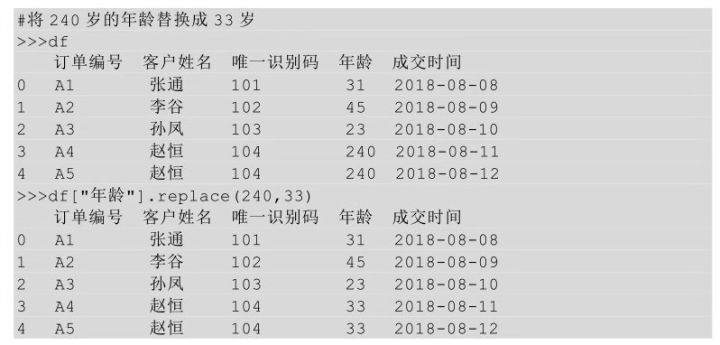
上面的代碼是對年齡這一列進行替換,所以把年齡這一列選中����,然后調(diào)用replace()方法。有時候要對整個表進行替換��,比如對全表中的缺失值進行替換�,這個時候replace()方法就相當(dāng)于fillna()方法了。
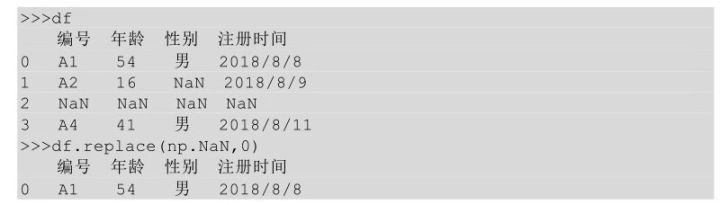

Np.NaN是python中對缺失值的一種表示方法���。
2�、多對一替換
多對一替換就是把一塊區(qū)域中的多個值替換成某一個值����,已知現(xiàn)在有三個異常年齡(240、260��、280)需要把這三個年齡都替換成正常范圍年齡的平均值33,該怎么實現(xiàn)呢����?
(1)Excel實現(xiàn)
在Excel中需要借助if函數(shù)來實現(xiàn)多對一替換����。一直年齡這一列是D列,要想對這個異常值進行替換���,可以通過如下函數(shù)實現(xiàn)���。

上面的公式借助了Excel中的OR()函數(shù),表示如果D列等于240����、260、或者280時����,該單元格的值為33,否則為D列的值���。替換后的結(jié)果如下圖所示����。
(2)Python實現(xiàn)
在 Python 中實現(xiàn)多對一的替換比較簡單,同樣也是利用replace()方法���,replace([A,B],C)表示將A�、B替換成C�����。
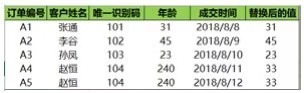
3���、多對多替換
多對多替換其實就是某個區(qū)域中多個一對一的替換。比如將年齡異常值240替換成平均值減一�,260替換成平均值,280替換成平均值加一�����,該怎么實現(xiàn)呢��?
(1)Excel實現(xiàn)
若想在Excel中實現(xiàn)����,需要借助函數(shù),且需要多個if嵌套語句來實現(xiàn),同時已知年齡列為D列�����,具體函數(shù)如下:
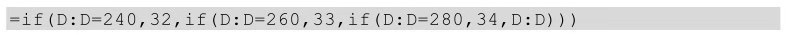
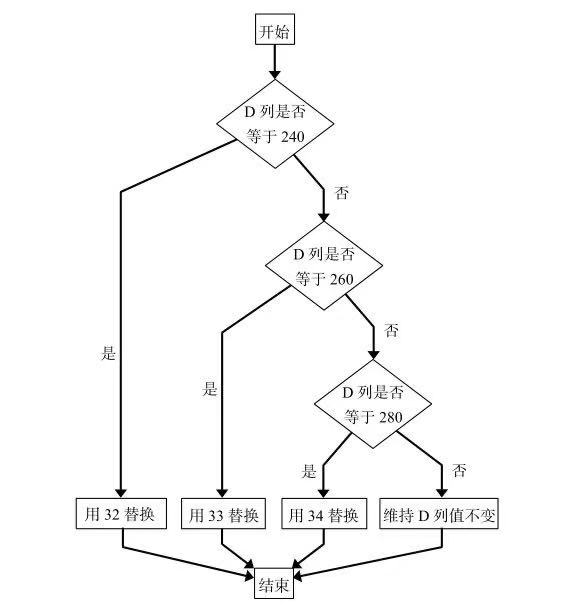
下圖為該函數(shù)執(zhí)行的流程�����。
替換后的結(jié)果如下圖所示:

(2)Python實現(xiàn)
在Python中若想實現(xiàn)多對多的替換��,同樣是借助replace()方法�,將替換值與待替換值用字典的形式表示����,replace(“A”:“a”,“B”:“b”)表示用a替換A�,用b 替換B。
二���、數(shù)值排序
數(shù)值排序是按照具體數(shù)值的大小進行排序的��,有升序和降序兩種����,升序就是數(shù)值由小到大排列,降序是數(shù)值由大到小排列����。
1、按照一列數(shù)值進行排序
按照一列數(shù)值進行排序就是整個數(shù)據(jù)表都以某一列為準(zhǔn)�����,進行升序或者降序排列�。
(1)Excel實現(xiàn)
在Excel中想要按照某列進行數(shù)值排序,只要選中這一列的字段名�,然后單擊編輯菜單欄下的排序和篩選按鈕;在下拉菜單中選擇升序或者降序選項即可���,操作流程如下圖所示�。
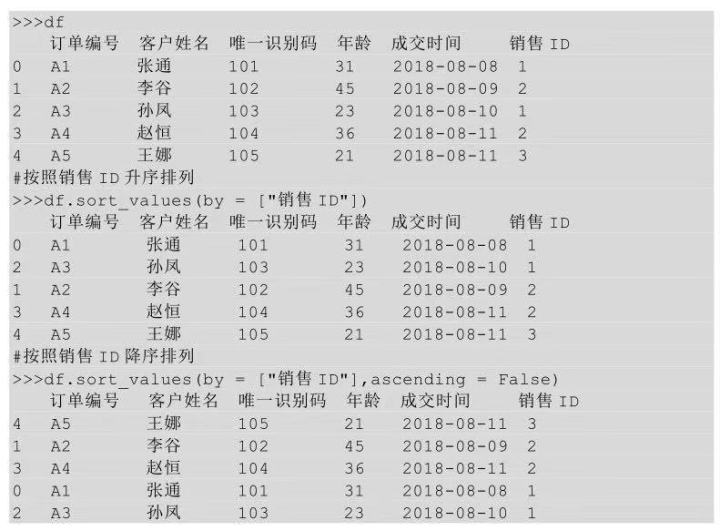
按照銷售ID進行升序排列前后的結(jié)果如下圖所示:

(2)Python實現(xiàn)
在Python中我們?nèi)粝氚凑漳沉羞M行排序���,需要用到sort_values()方法�����,在sort_values后的括號中指明要排序的列名�����,以及升序還是降序排序����。

上面代碼表示df表按照col1列進行排序,ascending = False表示按照col1列進行降序排列��。Ascending參數(shù)默認值為True��,表示升序排列���。所以����,如果是要根據(jù)col1進行升序排序���,則可以只指明列名��,不需要額外聲明排序方式。

2����、按照有缺失值的列進行排序
(1)Python實現(xiàn)
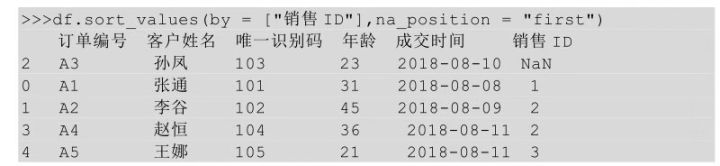
在Python中���,當(dāng)待排序的列中有缺失值時���,可以通過設(shè)置na_position參數(shù)對缺失值的顯示位置進行設(shè)置����,默認參數(shù)值為last���,可以不寫�,表示將缺失值顯示在最后���。
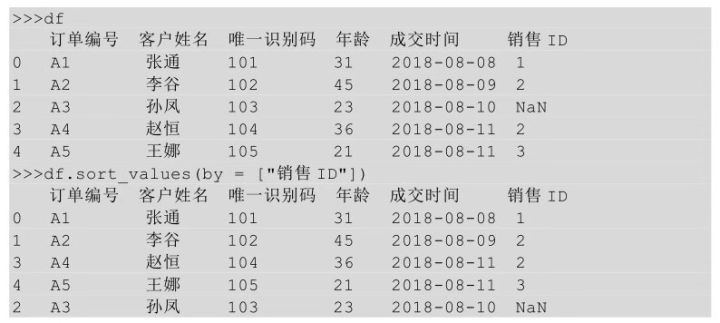
通過設(shè)置na_position參數(shù)將缺失值顯示在最前面����。
3、按照多列數(shù)值進行排序
按照多列數(shù)值排序是指同時依據(jù)多列數(shù)據(jù)進行升序、降序排序,當(dāng)?shù)谝涣谐霈F(xiàn)重復(fù)值時按照第二列進行排序���,當(dāng)?shù)诙斐霈F(xiàn)重復(fù)值時按照第三列進行排序,以此類推。
(1)Excel實現(xiàn)
在Excel中實現(xiàn)按照多列排序�����,選中待排序的所有數(shù)據(jù)���,單擊編輯菜單欄下的排序和篩選按鈕����,在下拉菜單中選擇自定義排序選項就會出現(xiàn)如下圖所示界面。添加條件就是添加按照排序的列,在次序里面可以單獨定義每一列的升序或者降序�����。
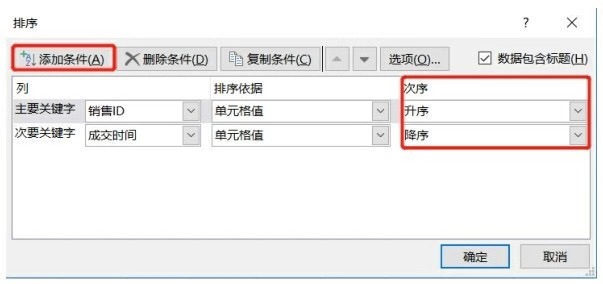
舉個例子�����,對下圖左側(cè)的Before表先按照銷售ID升序排列,當(dāng)遇到重復(fù)的銷售ID時���,再按成交時間降序排列,得出下圖右側(cè)的After表�����。

(2)Python實現(xiàn)
在Python中實現(xiàn)按照多列進行排序,用到的方法同樣是sort_values()����,只要sort_values()后的括號中以列表的形式指明要排序的多列列名及每列的排序方式即可。
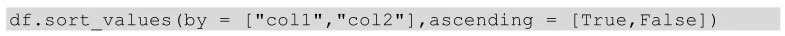
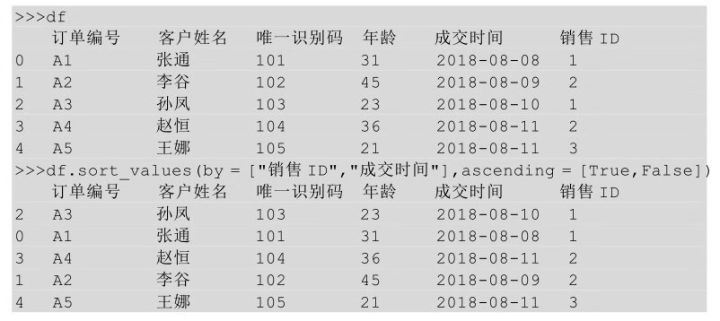
上面代碼表示df表現(xiàn)按照col1列進行升序排列�,當(dāng)col1 列遇到重復(fù)值時,再按照col2列進行降序排列����。對于表df我們依舊先按照銷售ID升序排列,當(dāng)遇到重復(fù)的銷售ID時���,再按照成交時間降序排列�����,代碼如下圖所示:
三�、數(shù)值排名
數(shù)值排名和數(shù)值排序是相對應(yīng)的����,排名會新增一列,這一列用來存放數(shù)據(jù)的排名情況�,排名是從1開始的
(1)Excel實現(xiàn)
在Excel中用于排名的函數(shù)有RANK.AVG()和RANK.EQ()兩個。
當(dāng)待排名的數(shù)值沒有重復(fù)值時�����,這兩個函數(shù)的效果是完全一樣的,兩個函數(shù)的不同在于處理重復(fù)值方式不同���。
●RANK.AVG(number,ref,order)
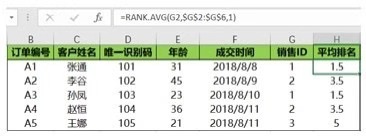
number表示待排名的數(shù)值,ref表示一整列數(shù)值的范圍�,order用來指明降序還是升序排名。當(dāng)待排名的數(shù)值由重復(fù)值時���,返回重復(fù)值的平均排名�。
對銷售ID進行平均排名以后的結(jié)果如下圖所示�。圖中銷售ID為1的值有兩個,假設(shè)一個排名是1���,另一個排名是2���,那么二者的均值就是1.5,所以平均排名就是1.5����;銷售ID為2的值同樣有兩個,同樣假設(shè)一個排名為3 ���,另一個排名為4�����,那么二者的均值是3.5�;銷售ID為3的值沒有重復(fù)值,所以排名就是5�。
●RANK.EQ(number,ref,order)
RANK.EQ的參數(shù)與RANK.AVG的意思是一樣的。當(dāng)待排名的數(shù)值有重復(fù)值時�����,RANK.EQ返回重復(fù)值的最佳排名���。
對銷售ID進行最佳排名以后的結(jié)果如下圖所示��。圖中銷售ID為1的值有兩個����,第一個重復(fù)值的排名為1���,所以兩個值的最佳排名均為1 ���;銷售ID為2的值也有兩個�����,第一個重復(fù)值的排名為3���,所以兩個值的最佳排名均為3,;銷售ID為3的值沒有重復(fù)值����,最佳排名為5�����。

(2)Python實現(xiàn)
在Python中對數(shù)值進行排名���,小用到rank()方法�����。Rank()方法主要有兩個參數(shù)��,一個是ascending����,用來指明升序排列還是降序排列,默認升序排列��,和Excel中的order的意思一致�;另一個是method,用來指明待排列值有重復(fù)值時的處理情況�。下表是參數(shù)method可取的不同參數(shù)值及說明。
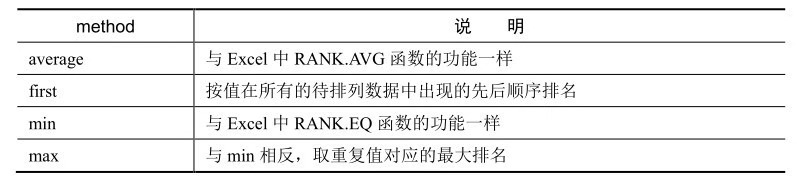
method取值為average時的排名情況����,與Excel中RANK.AVG函數(shù)一致。

method取值為first時的排名情況���,銷售ID為1的值有兩個����,第一個出現(xiàn)的排名為1�,第二個出現(xiàn)的排名為2;銷售ID為2的以此類推�。

method取值為min時的排名情況,與Excel中RANK.EQ函數(shù)一致���。

method取值為max時的排名情況�,與method取值min時相反,銷售ID為1的值有兩個�����,第二個重復(fù)值的排名為2�����,所以兩個值的排名均為2;銷售ID為2的值有兩個�����,兩個重復(fù)值的排名為4��,所以兩個值的排名均為4。

四��、數(shù)值刪除
數(shù)值刪除是對數(shù)據(jù)表中一些無用的數(shù)據(jù)進行刪除操作�。
1、刪除列
(1)Excel實現(xiàn)
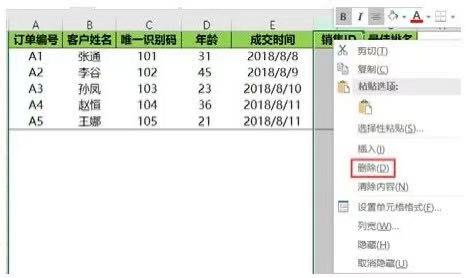
在Excel中���,要刪除某一列或某幾列��,只需要選中這些列��,然后單擊鼠標(biāo)右鍵����,在彈出的菜單中選擇刪除選項即可(或者單擊鼠標(biāo)右鍵以后按D鍵),如下圖所示��。
(2)Python實現(xiàn)
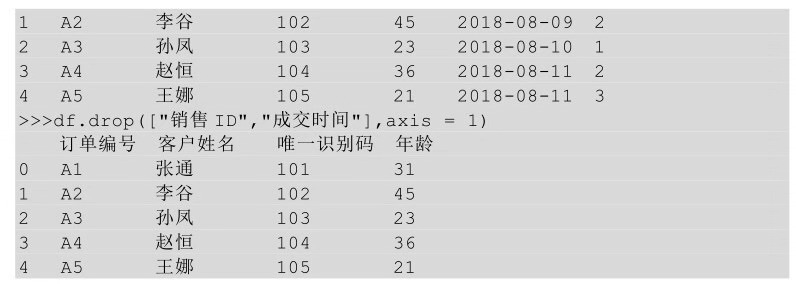
在Python中,要刪除某列�����,用到的是drop()方法��,即在drop方法后的括號中指明要刪除的列名或者列的位置���,即第幾列���。
在drop方法后的括號中直接傳入待刪除列的列名,需要加一個參數(shù)axis��,并讓其參數(shù)值等于1����,表示刪除列。

還可以在drop方法后的括號中直接傳入待刪除列的位置���,但也需要用axis參數(shù)����。
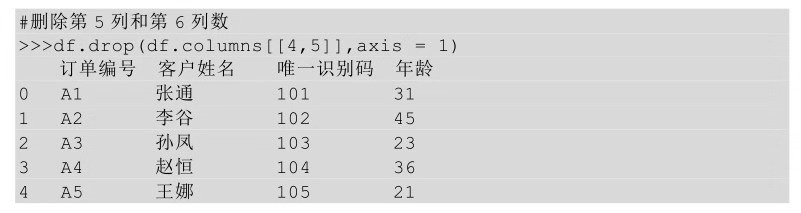
也可以將列名以列表的形式傳給columns參數(shù)�����,這個時候就不需要axis參數(shù)了���。
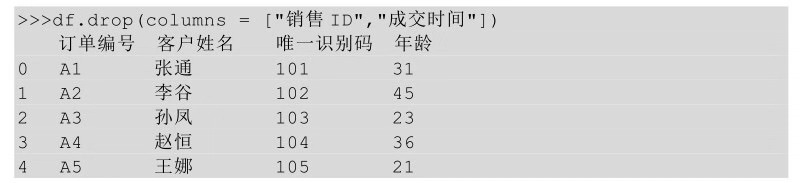
2��、刪除行
(1)Excel實現(xiàn)
在 Excel 中���,要刪除某些行使用的方法與刪除列是一致的���,先選中要刪除的行����,然后單擊鼠標(biāo)右鍵,在彈出的下拉菜單中選擇刪除選項就可以刪除行了����。
(2)Python實現(xiàn)
在Python中,要刪除某些行用到的方法依然是drop()�����,與刪除列類似的是�����,刪除行也要指明行相關(guān)的信息��。
在drop方法后的括號中直接傳入待刪除行的行名���,并讓axis參數(shù)值等于0�����,表示刪除行�����。
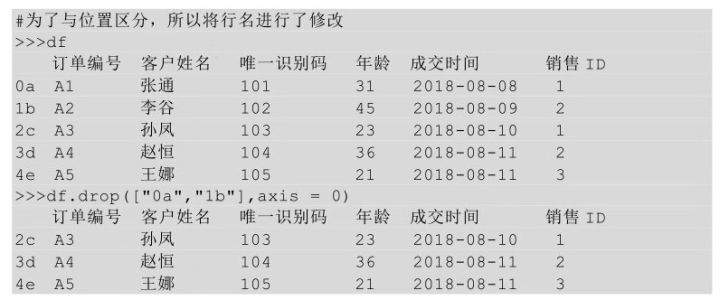
除了傳入行索引名稱��,還可以在drop方法后的括號中直接傳入待刪除行的行號�,也需要用axis參數(shù),并讓其參數(shù)值等于0��。
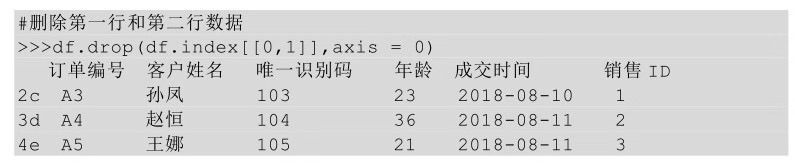
也可以將待刪除行的行名傳給index參數(shù)��,這個時候就不需要axis參數(shù)了���。
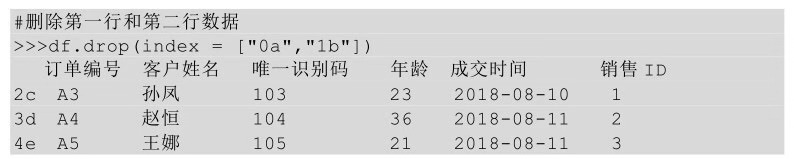
3�、刪除特定行
刪除特定行一般指刪除滿足某個條件的行�����,我們前面的異常值刪除算是刪除特定的行��。
(1)Excel實現(xiàn)
在Excel中刪除特定行分為兩步���,第一步先將符合條件的行篩選出來�����,第二步選中這些篩選出來的行然后單擊鼠標(biāo)右鍵,在彈出的下拉菜單中選擇刪除選項��。
(2)Python實現(xiàn)
在Python中刪除特定行使用的方法有些特殊,我們不直接刪除滿足條件的值���,而是把不滿足條件的值篩選出來作為新的數(shù)據(jù)源���,這樣就把要刪除的行過濾掉了。
在如下例子中���,要刪除年齡值大于等于40對應(yīng)的行�,我們并不直接刪除這一部分��,而是把它的相反部分取出來����,即把年齡小于40的行篩選出來作為新的數(shù)據(jù)源。

五�����、數(shù)值計數(shù)
數(shù)值計數(shù)就是計算某個值在一系列數(shù)值中出現(xiàn)的次數(shù)��。
(1)Excel實現(xiàn)
在Excel中實現(xiàn)數(shù)值計數(shù)���,我們使用的是COUNTIF()函數(shù)�����,COUNTIF()函數(shù)用來計算某個區(qū)域中滿足給定條件的單元格數(shù)目�����。

range表示一系列值的范圍��,criteria表示某一個值或者某一個條件����。
銷售ID的值的計數(shù)結(jié)果如下圖所示。銷售ID為1的值在F2:F6這個范圍內(nèi)出現(xiàn)了兩次���;銷售ID為2的值在該范圍內(nèi)也出現(xiàn)了兩次��;銷售ID為3的值出現(xiàn)了1次��。

(2)Python實現(xiàn)
在Python中����,要對某些值的出現(xiàn)次數(shù)進行計數(shù)���,我們用到的方法是value_counts()����。

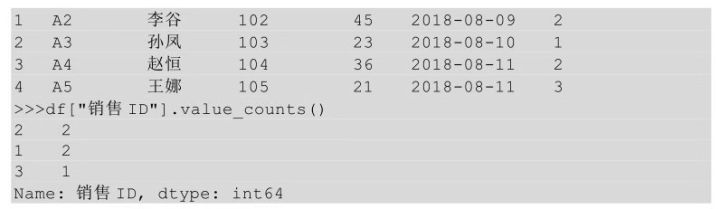
上面代碼運行的結(jié)果表示銷售ID為2的值出現(xiàn)了兩次�,銷售ID為1的值出現(xiàn)了兩次,銷售ID為3的值出現(xiàn)了1次�����。這些是值出現(xiàn)的絕對次數(shù)���,還可以看一下不同值出現(xiàn)的占比���,只需要給value_counts()方法傳入?yún)?shù)normalize = True即可。

上面代碼的運行結(jié)果表示銷售ID為2的值的占比為0.4����,銷售ID為1的值的占比為0.4,銷售ID為3的值的占比為0.2�。上面銷售ID的排序是2、1�����、3��,這是按照計數(shù)值降序排列的(0.4、0.4�、0.2),通過設(shè)置sort=False可以實現(xiàn)不按計數(shù)值降序排列�。

六、唯一值獲取
唯一值獲取就是把某一系列值刪除重復(fù)項以后的結(jié)果�,一般可以將表中某一列認為是一系列值。
(1)Excel實現(xiàn)
在Excel中����,我們?nèi)粝氩榭茨骋涣袛?shù)值中的唯一值,可以把這一列數(shù)值復(fù)制粘貼出來��,然后刪除重復(fù)項����,剩下的就是唯一值了。
(2)Python實現(xiàn)
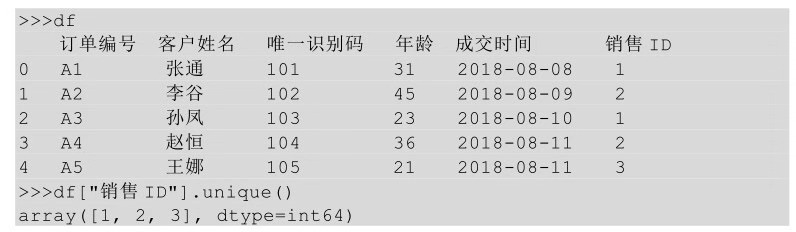
在Python中���,我們要獲取一列值的唯一值�,整體思路與Excel的是一致的����,先把某一列的值復(fù)制粘貼出來,然后用刪除重復(fù)項的方法實現(xiàn),關(guān)于刪除重復(fù)項在前面講過了�����,本節(jié)用另一種獲取唯一值的方法unique()實現(xiàn)�。
舉個例子����,對表df中的銷售ID取唯一值,先把銷售ID取出來��,然后利用unique()方法獲取唯一值��,代碼如下所示�。
七、數(shù)值查找
數(shù)值查找就是查看數(shù)據(jù)表中的數(shù)據(jù)是否包含某個值或者某些值�����。
(1)Excel實現(xiàn)
在Excel中我們要想查看數(shù)據(jù)表中是否包含某個值可以直接利用查找功能�。首先要把待查找區(qū)域選中,可以選擇一列或者多列���,如果不選�,則默認在全表中查詢�,然后單擊編輯菜單欄的查找和選擇按鈕�����,在下拉菜單中選擇查找選項���,如下圖所示。
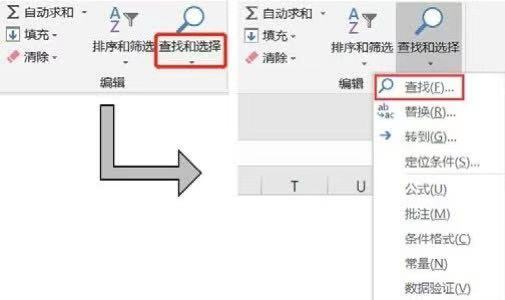
下圖為選擇查找選項后彈出的查找和替換對話框(也可以使用快捷鍵Ctrl+F打開查找和替換對話框)���,在查找內(nèi)容框輸入要查找的內(nèi)容即可�,可以選擇查找全部�����,這樣就會把所有查找到的內(nèi)容顯示出來��;也可以選擇查找下一個�,這樣會把查找結(jié)果一個一個顯示出來。
(2)Python實現(xiàn)
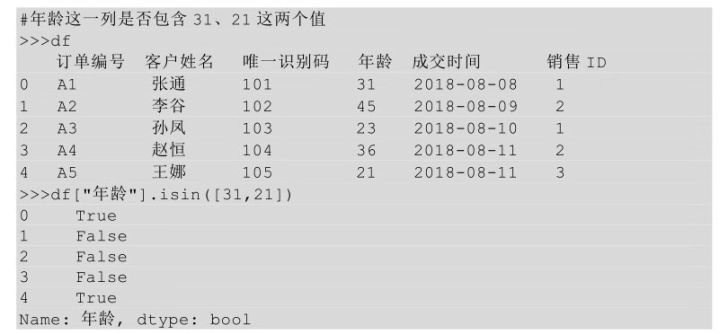
在Python中查看數(shù)據(jù)表中是否包含某個值用到的是isin()方法��,而且可以同時查找多個值��,只需要在isin方法后的括號中指明即可�����。
可以將某列數(shù)據(jù)取出來,然后在這一列上調(diào)用 isin()方法����,看這一列中是否包含某個/些值,如果包含則返回True����,否則返回False�����。
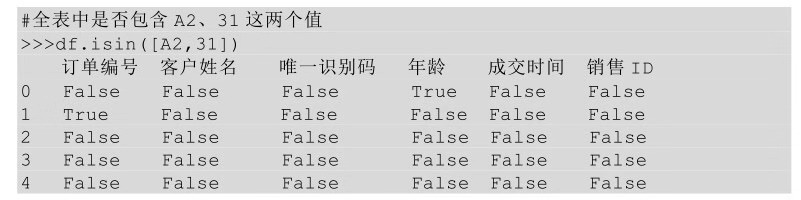
也可以針對全表查找是否包含某個值�����。
八����、區(qū)間切分
區(qū)間切分就是將一系列數(shù)值分成若干份,比如現(xiàn)在有10個人���,你要根據(jù)這10個人的年齡將他們分為三組��,這個切分過程就稱為區(qū)間切分��。
(1)Excel實現(xiàn)
在Excel中實現(xiàn)區(qū)間切分我們借助的是if函數(shù)����,具體公式如下:
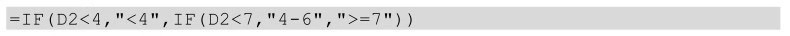
if函數(shù)的實現(xiàn)流程如下圖所示。
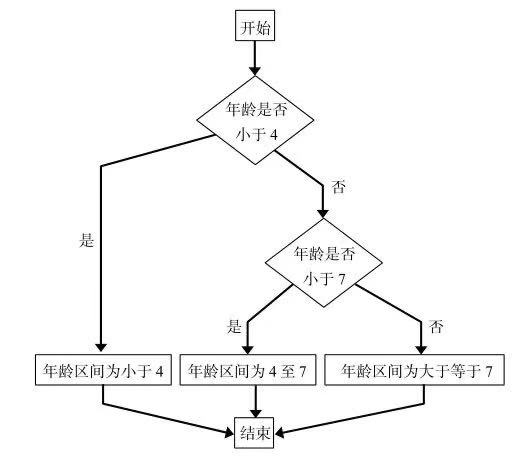
下圖為利用if嵌套函數(shù)實現(xiàn)的結(jié)果�。

(2)Python實現(xiàn)
在Python中對區(qū)間切分利用的是cut()方法,cut()方法有一個參數(shù)bins用來指明切分區(qū)間��。
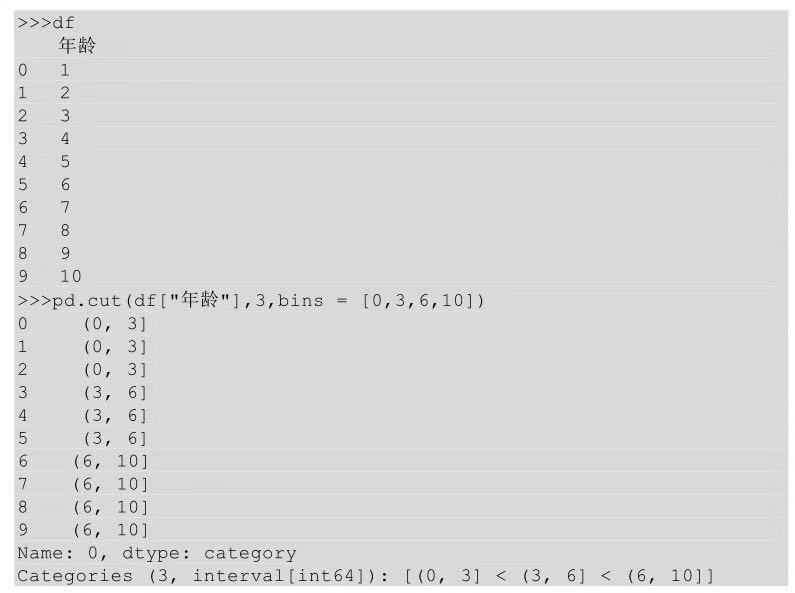
cut()方法的切分結(jié)果是幾個左開右閉的區(qū)間���,(0,3]就表示大于0小于等于3,(3,6]表示大于3小于等于6,(6,10]表示大于6小于等于10�����。
與cut()方法類似的還有qcut()方法���,qcut()方法不需要事先指明切分區(qū)間,只需要指明切分個數(shù)���,即你要把待切分數(shù)據(jù)切成幾份�����,然后它就會根據(jù)待切分數(shù)據(jù)的情況���,將數(shù)據(jù)切分成事先指定的份數(shù)����,依據(jù)的原則就是每個組里面的數(shù)據(jù)個數(shù)盡可能相等��。


在數(shù)據(jù)分布比較均勻的情況下��,cut()方法和 qcut()方法得到的區(qū)間基本一致���,當(dāng)數(shù)據(jù)分布不均勻��,即方差比較大時,兩者得到的區(qū)間的偏差就會比較大�。
九、插入新的行或列
在特定的位置插入行或者列也是比較常用的操作�����。具體的插入操作有兩個關(guān)鍵要素�,一個是在哪插入,另一個是插入什么���。
(1)Excel實現(xiàn)
在Excel中要插入行或列首先要確定在哪一行或哪一列前面插入����,然后選中這一列或這一行單擊鼠標(biāo)右鍵,在彈出的下拉菜單中選擇插入選項即可�����。
要在唯一識別碼列前面插入一列���,選中唯一識別碼這一列然后單擊鼠標(biāo)右鍵��,在彈出的下拉菜單中選擇插入選項即可��,如下圖所示���。
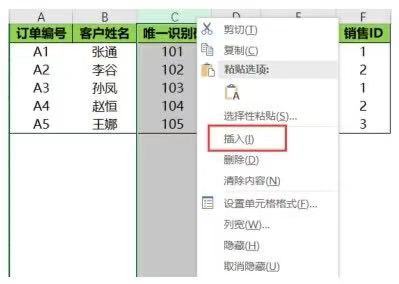
完成上面的操作后,就會有一個新的空行或空列�����,在空行或空列里面輸入要插入的數(shù)據(jù)即可����。
(2)Python實現(xiàn)
在Python中沒有專門用來插入行的方法����,可以把待插入的行當(dāng)作一個新的表�����,然后將兩個表在縱軸方向上進行拼接���。關(guān)于表拼接在后面的章節(jié)會講��。
在Python中插入一個新的列用到的方法是insert()��,在insert方法后的括號中指明要插入的位置��、插入后新列的列名�,以及要插入的數(shù)據(jù)��。

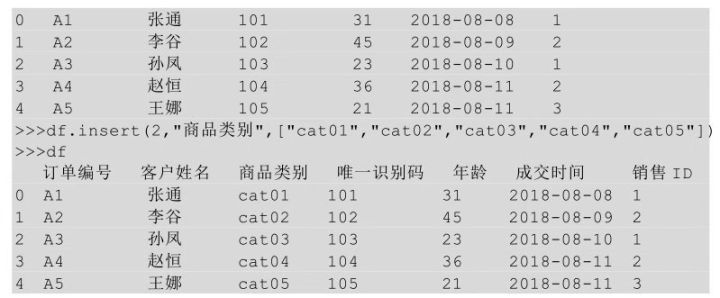
還可以直接以索引的方式進行列的插入���,直接讓新的一列等于某列值即可。

上面的代碼表示新插入一列名為商品類別的值�,這一列的值就是后面列表中的值。
十�����、行列互換
所謂的行列互換(又稱轉(zhuǎn)置)就是將行數(shù)據(jù)轉(zhuǎn)換到列方向上,將列數(shù)據(jù)轉(zhuǎn)換到行方向上��。
(1)Excel實現(xiàn)
在Excel中行列互換(轉(zhuǎn)置)需要先把待轉(zhuǎn)置的內(nèi)容復(fù)制��,然后粘貼在新的區(qū)域中�,粘貼選項選擇轉(zhuǎn)置即可,轉(zhuǎn)置選項如下圖所示����。
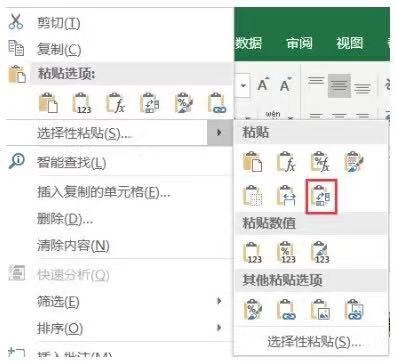
轉(zhuǎn)置前后的效果對比如下圖所示。

(2)Python實現(xiàn)
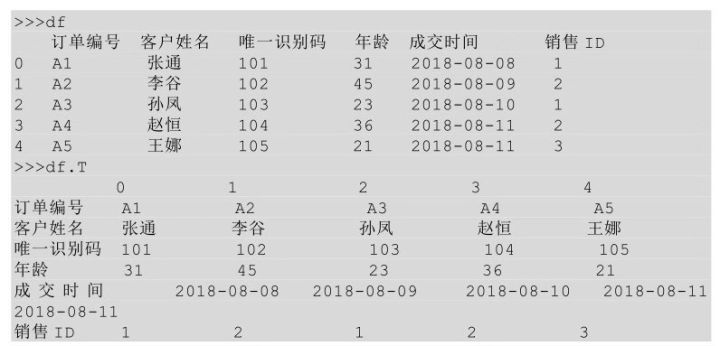
在 Python 中��,我們直接在源數(shù)據(jù)表的基礎(chǔ)上調(diào)用.T 方法即可得到源數(shù)據(jù)表轉(zhuǎn)置后的結(jié)果���。對轉(zhuǎn)置后的結(jié)果再次轉(zhuǎn)置就會回到原來的結(jié)果�。
對表df進行轉(zhuǎn)置���,代碼如下所示����。
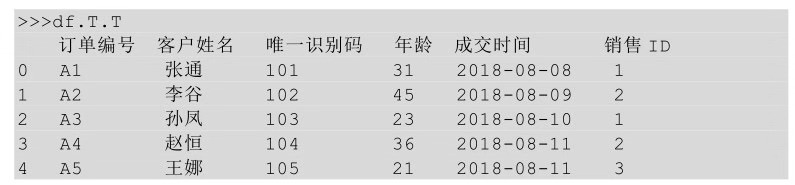
對轉(zhuǎn)后的表再次進行轉(zhuǎn)置�,代碼如下所示�。
十一��、索引重塑
所謂的索引重塑就是將原來的索引進行重新構(gòu)造����。典型的DataFrame結(jié)構(gòu)的表如下表所示。

上面這種表是典型的DataFrame結(jié)構(gòu)���,它用一個行索引和一個列索引來確定一個唯一值�����,比如S1-C1唯一值為1,S2-C3唯一值為6����。這種通過兩個位置確定一個唯一值的方法不僅可以用上述這種表格型結(jié)構(gòu)表示����,而且可以用一種樹形結(jié)構(gòu)來表示,如下圖所示����。
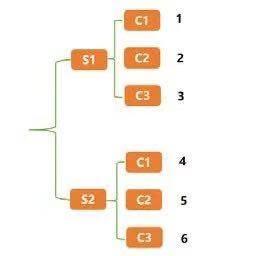
樹形結(jié)構(gòu)其實就是在維持表格型行索引不變的前提下��,把列索引也變成行索引,其實就是給表格型數(shù)據(jù)建立層次化索引�。
我們把數(shù)據(jù)從表格型數(shù)據(jù)轉(zhuǎn)換到樹形數(shù)據(jù)的過程叫重塑,這種操作在Excel中沒有�,在Python用到的方法是stack(),示例代碼如下所示�。

與stack()方法相對應(yīng)的方法是unstack()方法,stack()方法是將表格型數(shù)據(jù)轉(zhuǎn)化為樹形數(shù)據(jù)���,而unstack()方法是將樹形數(shù)據(jù)轉(zhuǎn)為表格型數(shù)據(jù)���,示例代碼如下所示。

十二���、長寬表轉(zhuǎn)換
長寬表轉(zhuǎn)換就是將比較長(很多行)的表轉(zhuǎn)換為比較寬(很多列)的表���,或者將比較寬的表轉(zhuǎn)化為比較長的表。
下表是一個寬表(有很多列)�����。

我們要把這個寬表轉(zhuǎn)化為如下表所示的長表���。
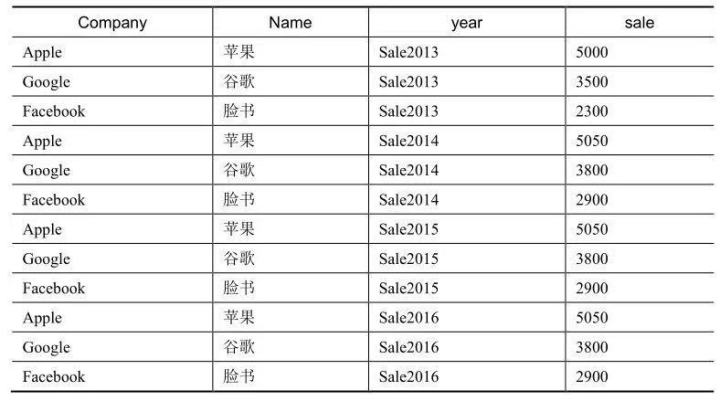
上面這種由很多列轉(zhuǎn)換為很多行的過程�����,就是寬表轉(zhuǎn)換為長表的過程��,這種轉(zhuǎn)換過程是有前提的����,那就是需要有公共列。
1��、寬表轉(zhuǎn)換為長表
寬表轉(zhuǎn)化為長表��,在Excel中一般都用復(fù)制粘貼實現(xiàn)���,我們主要看看在Python中如何實現(xiàn)�����。Python中要實現(xiàn)這種轉(zhuǎn)換有兩種方法��,一種是stack()方法����,另一種是melt()方法。
(1)stack()方法實現(xiàn)
stack()在將表格型數(shù)據(jù)轉(zhuǎn)為樹形數(shù)據(jù)時���,是在保持行索引不變的前提下,將列索引也變成行索引����。
這里將寬表轉(zhuǎn)化為長表首先要在保持 Company 和 Name 不變的前提下,將Sale2013���、Sale2014��、Sale2015���、Sale2016也變成行索引。所以��,需要先將 Company和Nmae先設(shè)置成索引�����,然后調(diào)用stack()方法�����,將列索引也轉(zhuǎn)換成行索引,最后利用reset_index()方法進行索引重置����,示例代碼如下所示。
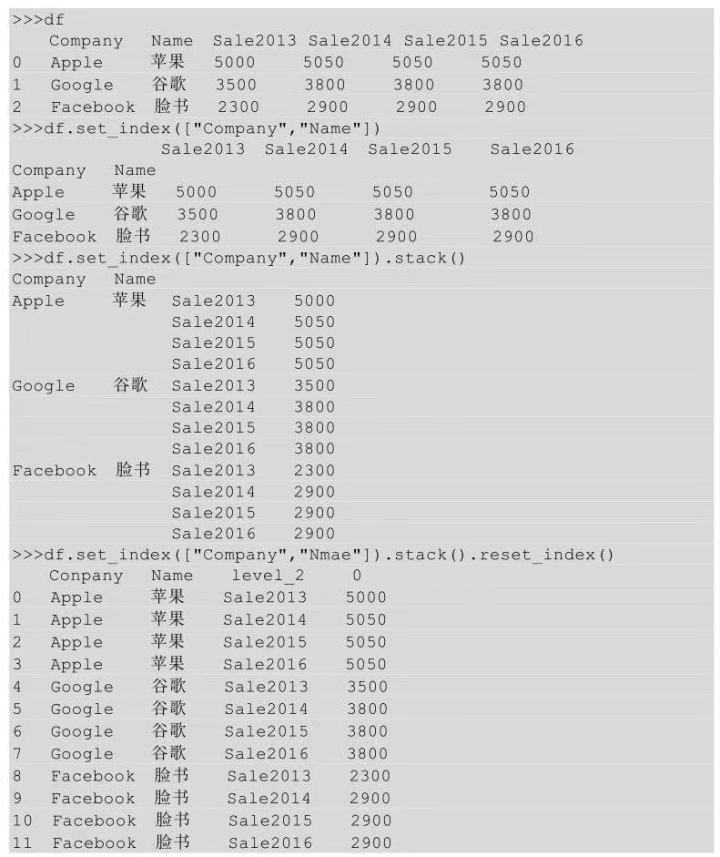
(2)melt()方法實現(xiàn)
用melt()方法實現(xiàn)上述功能�����,代碼如下所示�。
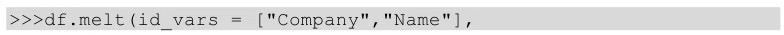
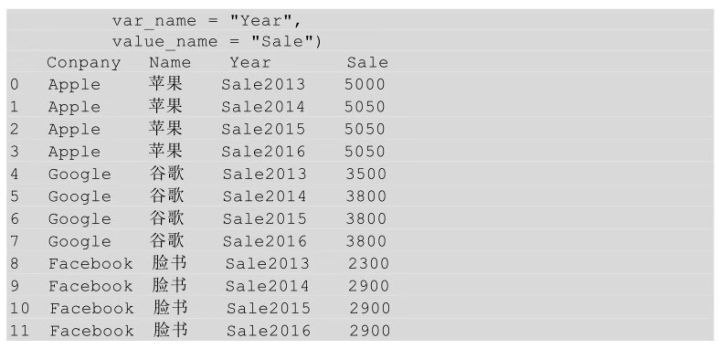
melt中的id_vars參數(shù)用于指明寬表轉(zhuǎn)換到長表時保持不變的列,var_name參數(shù)表示原來的列索引轉(zhuǎn)化為“行索引”以后對應(yīng)的列名�,value_name表示新索引對應(yīng)的值的列名。
注意���,這里的“行索引”是有雙引號的��,它并非實際行索引��,只是類似實際的行索引��。
2��、長表轉(zhuǎn)換為寬表
將長表轉(zhuǎn)化為寬表就是寬表轉(zhuǎn)化為長表的逆過程��。常用的方法就是數(shù)據(jù)透視表����,關(guān)于數(shù)據(jù)透視表的使用我們將在10.2節(jié)進行詳細講解,這里大概了解一下就行��,具體實現(xiàn)如下:
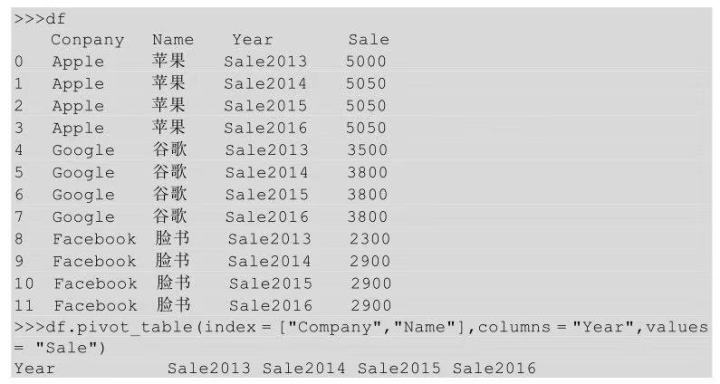

上面的實現(xiàn)過程是把Company和Name設(shè)置成行索引����,Year設(shè)置成列索引�����,Sale為值���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;












 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330