python分治法求二維數(shù)組局部峰值方法
下面小編就為大家分享一篇python分治法求二維數(shù)組局部峰值方法�����,具有很好的參考價(jià)值�����,希望對(duì)大家有所幫助�����。一起跟隨小編過來看看吧
題目的意思大致是在一個(gè)n*m的二維數(shù)組中���,找到一個(gè)局部峰值��。峰值要求大于相鄰的四個(gè)元素(數(shù)組邊界以外視為負(fù)無窮)���,比如最后我們找到峰值A(chǔ)[j][i],則有A[j][i]
> A[j+1][i] && A[j][i] > A[j-1][i] && A[j][i]
> A[j][i+1] && A[j][i] > A[j][i-1]����。返回該峰值的坐標(biāo)和值��。
當(dāng)然�,最簡(jiǎn)單直接的方法就是遍歷所有數(shù)組元素,判斷是否為峰值�,時(shí)間復(fù)雜度為O(n^2)
再優(yōu)化一點(diǎn)求每一行(列)的最大值,再通過二分法找最大值列的峰值(具體方法可見一維數(shù)組求峰值)���,這種算法時(shí)間復(fù)雜度為O(logn)
這里討論的是一種復(fù)雜度為O(n)的算法���,算法思路分為以下幾步:
1�、找“田”字���。包括外圍的四條邊和中間橫豎兩條邊(圖中綠色部分)����,比較其大小�����,找到最大值的位置��。(圖中的7)
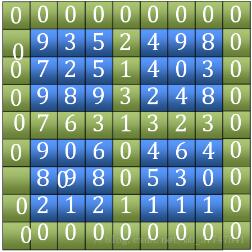
2�、找到田字中最大值后��,判斷它是不是局部峰值��,如果是返回該坐標(biāo)����,如果不是����,記錄找到相鄰四個(gè)點(diǎn)中最大值坐標(biāo)�。通過該坐標(biāo)所在的象限縮小范圍,繼續(xù)比較下一個(gè)田字
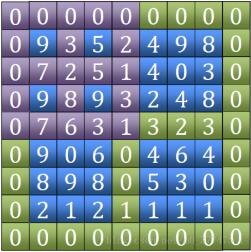
3�����、當(dāng)范圍縮小到3*3時(shí)必定會(huì)找到局部峰值(也可能之前就找到了)
關(guān)于為什么我們選擇的范圍內(nèi)一定存在峰值���,大家可以這樣想�����,首先我們有一個(gè)圈,我們已知有圈內(nèi)至少有一個(gè)元素大于這個(gè)圈所有的元素�����,那么�,是不是這個(gè)圈中一定有一個(gè)最大值?
可能說得有點(diǎn)繞����,但是多想想應(yīng)該能夠理解��,也可以用數(shù)學(xué)的反證法來證明�。
算法我們理解后接下來就是代碼實(shí)現(xiàn)了���,這里我用的語言是python(初學(xué)python�,可能有些用法上不夠簡(jiǎn)潔請(qǐng)見諒)�,先上代碼:
import numpy as np
def max_sit(*n): #返回最大元素的位置
temp = 0
sit = 0
for i in range(len(n)):
if(n[i]>temp):
temp = n[i]
sit = i
return sit
def dp(s1,s2,e1,e2):
m1 = int((e1-s1)/2)+s1 #row
m2 = int((e2-s1)/2)+s2 #col
nub = e1-s1
temp = 0
sit_row = 0
sit_col = 0
for i in range(nub):
t = max_sit(list[s1][s2+i], #第一排
list[m1][s2+i], #中間排
list[e1][s2+i], #最后排
list[s1+i][s2], #第一列
list[s1+i][m2], #中間列
list[s1+i][e2], #最后列
temp)
if(t==6):
pass
elif(t==0):
temp = list[s1][s2+i]
sit_row = s1
sit_col = s2+i
elif(t==1):
temp = list[m1][s2+i]
sit_row = m1
sit_col = s2+i
elif(t==2):
temp = list[e1][s2+i]
sit_row = e1
sit_col = s2+i
elif(t==3):
temp = list[s1+i][s2]
sit_row = s1+i
sit_row = s2
elif(t==4):
temp = list[s1+i][m2]
sit_row = s1+i
sit_col = m2
elif(t==5):
temp = list[s1+i][e2]
sit_row = s1+i
sit_col = m2
t = max_sit(list[sit_row][sit_col], #中
list[sit_row-1][sit_col], #上
list[sit_row+1][sit_col], #下
list[sit_row][sit_col-1], #左
list[sit_row][sit_col+1]) #右
if(t==0):
return [sit_row-1,sit_col-1]
elif(t==1):
sit_row-=1
elif(t==2):
sit_row+=1
elif(t==3):
sit_col-=1
elif(t==4):
sit_col+=1
if(sit_row<m1):
e1 = m1
else:
s1 = m1
if(sit_col<m2):
e2 = m2
else:
s2 = m2
return dp(s1,s2,e1,e2)
f = open("demo.txt","r")
list = f.read()
list = list.split("\n") #對(duì)行進(jìn)行切片
list = ["0 "*len(list)]+list+["0 "*len(list)] #加上下的圍墻
for i in range(len(list)): #對(duì)列進(jìn)行切片
list[i] = list[i].split()
list[i] = ["0"]+list[i]+["0"] #加左右的圍墻
list = np.array(list).astype(np.int32)
row_n = len(list)
col_n = len(list[0])
ans_sit = dp(0,0,row_n-1,col_n-1)
print("找到峰值點(diǎn)位于:",ans_sit)
print("該峰值點(diǎn)大小為:",list[ans_sit[0]+1,ans_sit[1]+1])
f.close()
首先我的輸入寫在txt文本文件里,通過字符串轉(zhuǎn)換變?yōu)槎S數(shù)組�,具體轉(zhuǎn)換過程可以看我上一篇博客——python中字符串轉(zhuǎn)換為二維數(shù)組。(需要注意的是如果在windows環(huán)境中split后的列表沒有空尾巴�,所以不用加list.pop()這句話)。有的變動(dòng)是我在二維數(shù)組四周加了“0”的圍墻����。加圍墻可以再我們判斷峰值的時(shí)候不用考慮邊界問題。
max_sit(*n)函數(shù)用于找到多個(gè)值中最大值的位置����,返回其位置,python的內(nèi)構(gòu)的max函數(shù)只能返回最大值��,所以還是需要自己寫�����,*n表示不定長(zhǎng)參數(shù),因?yàn)槲倚枰诒容^田和十(判斷峰值)都用到這個(gè)函數(shù)
def max_sit(*n): #返回最大元素的位置
temp = 0
sit = 0
for i in range(len(n)):
if(n[i]>temp):
temp = n[i]
sit = i
return sit
dp(s1,s2,e1,e2)函數(shù)中四個(gè)參數(shù)的分別可看為startx����,starty,endx����,endy。即我們查找范圍左上角和右下角的坐標(biāo)值�����。
m1,m2分別是row 和col的中間值�,也就是田字的中間。
def dp(s1,s2,e1,e2):
m1 = int((e1-s1)/2)+s1 #row
m2 = int((e2-s1)/2)+s2 #col
依次比較3行3列中的值找到最大值����,注意這里要求二維數(shù)組為正方形,如果為矩形需要做調(diào)整
for i in range(nub):
t = max_sit(list[s1][s2+i], #第一排
list[m1][s2+i], #中間排
list[e1][s2+i], #最后排
list[s1+i][s2], #第一列
list[s1+i][m2], #中間列
list[s1+i][e2], #最后列
temp)
if(t==6):
pass
elif(t==0):
temp = list[s1][s2+i]
sit_row = s1
sit_col = s2+i
elif(t==1):
temp = list[m1][s2+i]
sit_row = m1
sit_col = s2+i
elif(t==2):
temp = list[e1][s2+i]
sit_row = e1
sit_col = s2+i
elif(t==3):
temp = list[s1+i][s2]
sit_row = s1+i
sit_row = s2
elif(t==4):
temp = list[s1+i][m2]
sit_row = s1+i
sit_row = m2
elif(t==5):
temp = list[s1+i][e2]
sit_row = s1+i
sit_row = m2
判斷田字中最大值是不是峰值�����,并找不出相鄰最大值
t = max_sit(list[sit_row][sit_col], #中
list[sit_row-1][sit_col], #上
list[sit_row+1][sit_col], #下
list[sit_row][sit_col-1], #左
list[sit_row][sit_col+1]) #右
if(t==0):
return [sit_row-1,sit_col-1]
elif(t==1):
sit_row-=1
elif(t==2):
sit_row+=1
elif(t==3):
sit_col-=1
elif(t==4):
sit_col+=1
縮小范圍��,遞歸求解
if(sit_row<m1):
e1 = m1
else:
s1 = m1
if(sit_col<m2):
e2 = m2
else:
s2 = m2
return dp(s1,s2,e1,e2)
好了����,到這里代碼基本分析完了。如果還有不清楚的地方歡迎下方留言��。
除了這種算法外��,我也寫一種貪心算法來求解這道題�,只可惜最壞的情況下算法復(fù)雜度還是O(n^2),QAQ。
大體的思路就是從中間位置起找相鄰4個(gè)點(diǎn)中最大的點(diǎn)���,繼續(xù)把該點(diǎn)來找相鄰最大點(diǎn)����,最后一定會(huì)找到一個(gè)峰值點(diǎn)����,有興趣的可以看一下,上代碼:
#!/usr/bin/python3
def dp(n):
temp = (str[n],str[n-9],str[n-1],str[n+1],str[n+9]) #中 上 左 右 下
sit = temp.index(max(temp))
if(sit==0):
return str[n]
elif(sit==1):
return dp(n-9)
elif(sit==2):
return dp(n-1)
elif(sit==3):
return dp(n+1)
else:
return dp(n+9)
f = open("/home/nancy/桌面/demo.txt","r")
list = f.read()
list = list.replace(" ","").split() #轉(zhuǎn)換為列表
row = len(list)
col = len(list[0])
str="0"*(col+3)
for x in list: #加圍墻 二維變一維
str+=x+"00"
str+="0"*(col+1)
mid = int(len(str)/2)
print(str,mid)
p = dp(mid)
print (p)
f.close()
以上這篇python分治法求二維數(shù)組局部峰值方法就是小編分享給大家的全部?jī)?nèi)容了��,希望能給大家一個(gè)參考
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330