教你用Python實現(xiàn)簡單監(jiān)督學習算法
監(jiān)督學習作為運用最廣泛的機器學習方法,一直以來都是從數(shù)據(jù)挖掘信息的重要手段�。即便是在無監(jiān)督學習興起的近日,監(jiān)督學習也依舊是入門機器學習的鑰匙�。
這篇監(jiān)督學習教程適用于剛?cè)腴T機器學習的小白。
當然了����,如果你已經(jīng)熟練掌握監(jiān)督學習�,也不妨快速瀏覽這篇教程���,檢驗一下自己的理解程度~
什么是監(jiān)督學習����?
在監(jiān)督學習中����,我們首先導入包含有訓練屬性和目標屬性的數(shù)據(jù)集。監(jiān)督學習算法會從數(shù)據(jù)集中學習得出訓練樣本和其目標變量之間的關系��,然后將學習到的關系對新樣本(未被標記的樣本)進行分類�����。
為了闡明監(jiān)督學習的工作原理��,我們用根據(jù)學生學習時間預測其考試成績的例子來說明��。
用數(shù)學表示��,即Y = f(X)+ C�����,其中
f表示學生學習時間和考試成績之間的關系
X表示輸入(學習小時數(shù))
Y表示輸出(考試分數(shù))
C表示隨機誤差
監(jiān)督學習算法的終極目標是給出新的輸入X,使得預測結果Y的準確率最大��。有很多方法可以實現(xiàn)有監(jiān)督學習����,我們將探討幾種最常用的方法。
根據(jù)給定的數(shù)據(jù)集�,機器學習可以分為兩大類:分類(Classification)和回歸(Regression)�。如果給定的數(shù)據(jù)集的輸出值是類別,那么待解決是分類問題�。如果給定的數(shù)據(jù)集的輸出值是連續(xù)的,那么該問題是回歸問題���。
舉兩個例子
分類:判斷是貓還是狗��。
回歸:房子的售價是多少��?
分類
考慮這樣一個例子����,醫(yī)學研究員想要分析乳腺癌數(shù)據(jù)�����,用于預測患者使用三種治療方案中的哪一種。該數(shù)據(jù)分析問題就屬于分類問題���,通過建立分類模型來預測類別標簽�,例如“治療方案A”��、“治療方案B”或者“治療方案C”�����。
分類是一個預測類別標簽的預測問題�,這些類別標簽都是離散和無序的。分類包含兩個步驟:學習步驟和分類步驟����。
分類方法和選擇最優(yōu)方法
一些常見的分類算法:
K近鄰
決策樹
樸素貝葉斯
支持向量機
在學習步驟中,分類模型通過分析訓練集數(shù)據(jù)建立一個分類器��。在分類步驟中���,分類器對給定的數(shù)據(jù)進行分類�。用于分析的數(shù)據(jù)集(包含數(shù)據(jù)和其對應的標簽)被劃分為訓練集和測試集��。訓練集從分析用的數(shù)據(jù)集中隨機抽取。剩下的數(shù)據(jù)集構成測試集�。測試集和訓練集相互獨立,即測試集中的數(shù)據(jù)不會被構建于分類器�。
測試集用于評價分類器的預測精度。分類器的精度用測試集中預測正確的百分比表示�����。為了獲得更高的精度����,最好的方法是測試多個不同的算法,同時����,對每個算法嘗試不同的參數(shù)����。可以通過交互檢驗選擇最好的算法和參數(shù)��。
對于給定問題���,在選取算法時��,算法的精度����、訓練時間、線性�、參數(shù)數(shù)目以及特殊情況都要考慮在內(nèi)。
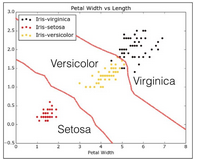
在IRIS數(shù)據(jù)集上實現(xiàn)sklearn中的KNN��,并對給定的輸入進行花卉類型分類���。
首先���,要應用機器學習算法,我們需要了解給定數(shù)據(jù)集的組成�。在這個例子中,我們使用內(nèi)置在sklearn包中的IRIS數(shù)據(jù)集?����,F(xiàn)在讓我們使用代碼查看IRIS數(shù)據(jù)集�����。
請確保你的電腦上成功安裝了Python��。然后,通過PIP安裝下面這些python庫:
pip install pandaspip install matplotlibpip install scikit-learn
在下面這段代碼中��,我們使用pandas中的一些方法查看IRIS數(shù)據(jù)集的一些屬性���。
from sklearn import datasetsimport pandas as pdimport
matplotlib.pyplot as plt# Loading IRIS dataset from scikit-learn object
into iris variable.iris = datasets.load_iris()# Prints the type/type
object of irisprint(type(iris))#
<class'sklearn.datasets.base.Bunch'># prints the dictionary keys
of iris dataprint(iris.keys())# prints the type/type object of given
attributesprint(type(iris.data), type(iris.target))# prints the no of
rows and columns in the datasetprint(iris.data.shape)# prints the target
set of the dataprint(iris.target_names)# Load iris training datasetX =
iris.data# Load iris target setY = iris.target# Convert datasets' type
into dataframedf = pd.DataFrame(X, columns=iris.feature_names)# Print
the first five tuples of dataframe.print(df.head())
輸出:
<class ‘sklearn.datasets.base.Bunch’>dict_keys([‘data’,
‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’])]<class
‘numpy.ndarray’> <class ‘numpy.ndarray’>(150, 4)[‘setosa’
‘versicolor’ ‘virginica’]sepal length(cm) sepal width(cm) petal
length(cm) petal width(cm)0 5.1 3.5 1.4 0.21 4.9 3.0 1.4 0.22 4.7 3.2
1.3 0.23 4.6 3.1 1.5 0.24 5.0 3.6 1.4 0.2
Sklearn中的K最近鄰算法
如果一個算法僅存儲訓練集數(shù)據(jù)����,并等待測試集數(shù)據(jù)的給出�����,那么這個算法便可認為是一個“懶惰學習法”���。直到給定測試集數(shù)據(jù)�����,它才會根據(jù)它與存儲的訓練集樣本的相似性來對新樣本進行分類。
K近鄰分類器就是一個懶惰學習法�����。
K近鄰基于類比學習����,比較一個測試樣本和與之相似訓練集數(shù)據(jù)���。訓練集有n個屬性表征。每個樣本由n維空間中的一個點表示�。這樣,訓練集中的所有樣本都儲存在n維模式空間中��。當給定一個未知的樣本���,K近鄰分類器在模式空間中搜尋和未知樣本最接近的k個訓練樣本����。這k個訓練樣本就是未知樣本的k個近鄰��。
“接近度”用距離來度量��,例如歐幾里得距離��。較好的K值可以通過實驗確定��。
在下面這段代碼中�,我們導入KNN分類器,將之應用到我們的輸入數(shù)據(jù)中�����,然后對花卉進行分類。
from sklearn import datasetsfrom sklearn.neighbors import
KNeighborsClassifier# Load iris dataset from sklearniris =
datasets.load_iris()# Declare an of the KNN classifier class with the
value with neighbors.knn = KNeighborsClassifier(n_neighbors=6)# Fit the
model with training data and target valuesknn.fit(iris['data'],
iris['target'])# Provide data whose class labels are to be predictedX = [
[5.9, 1.0, 5.1, 1.8], [3.4, 2.0, 1.1, 4.8],]# Prints the data
providedprint(X)# Store predicted class labels of Xprediction =
knn.predict(X)# Prints the predicted class labels of Xprint(prediction)
輸出:
[11]
其中���,0����,1�����,2分別代表不同的花��。在該例子中���,對于給定的輸入�,KNN分類器將它們都預測成為1這個類別的花���。
KNN對IRIS數(shù)據(jù)集分類的直觀可視化
回歸
回歸通常被定義為確定兩個或多個變量之間的相關關系�。例如���,你要通過給定的數(shù)據(jù)X預測一個人的收入�����。這里���,目標變量是指該變量是我們關心以及想要預測的未知變量,而連續(xù)是指Y的取值沒有間隔���。
預測收入是一個經(jīng)典的回歸問題�����。你的輸入應當包含所有與收入相關的個人信息(比如特征)��,這些信息可以預測收入����,例如工作時長����、教育經(jīng)歷、職稱以及他的曾住地等��。
回歸模型
一些常見的回歸模型有
線性回歸
邏輯回歸
多項式回歸
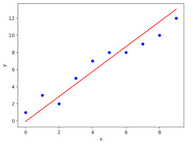
線性回歸通過擬合一條直線(回歸線)來建立因變量(Y)與一個或多個自變量(X)之間關系。
用數(shù)學公示表示�����,即h(xi) = βo + β1 * xi + e����,其中
βo是截距
β1是斜率
e是誤差項
用圖表示,即
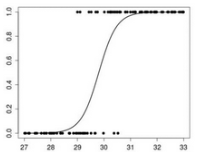
邏輯回歸是一種預測類別的算法��,用于找出特征和特定輸出概率之間關系�����。
當然了���,我們也可以把邏輯回歸歸類為分類算法�����,但就像我們剛才所說����,邏輯回歸的輸出其實是目標對象屬于某一類別的概率���。既然概率是連續(xù)的�,我們依舊把邏輯回歸算作回歸算法���。
用數(shù)學公式表示:p(X) = βo + β1 * X�����,其中p(x) = p(y = 1 | x)
圖形表示為
多項式回歸是一種將自變量x與因變量y的關系擬合為x的n階多項式的回歸算法����。
解決線性回歸問題
我們有數(shù)據(jù)集X��,以及對應的目標值Y�,我們使用普通最小二乘法通過最小化預測誤差來擬合線性模型
給定的數(shù)據(jù)集同樣劃分為訓練集和測試集。訓練集由已知標簽的樣本組成�����,因此算法能夠通過這些已知標簽的樣本來學習��。測試集樣本不包含標簽��,你并不知道你試圖預測樣本的標簽值�。
我們將選擇一個需要訓練的特征����,應用線性回歸方法擬合訓練數(shù)據(jù)����,然后預測測試集的輸出。
用Sklearn實現(xiàn)線性回歸
from sklearn import datasets, linear_modelimport matplotlib.pyplot as
pltimport numpy as np# Load the diabetes datasetdiabetes =
datasets.load_diabetes()# Use only one feature for trainingdiabetes_X =
diabetes.data[:, np.newaxis, 2]# Split the data into training/testing
setsdiabetes_X_train = diabetes_X[:-20]diabetes_X_test =
diabetes_X[-20:]# Split the targets into training/testing
setsdiabetes_y_train = diabetes.target[:-20]diabetes_y_test =
diabetes.target[-20:]# Create linear regression objectregr =
linear_model.LinearRegression()# Train the model using the training
setsregr.fit(diabetes_X_train, diabetes_y_train)# Input dataprint('Input
Values')print(diabetes_X_test)# Make predictions using the testing
setdiabetes_y_pred = regr.predict(diabetes_X_test)# Predicted
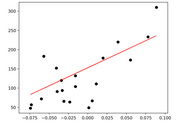
Dataprint("Predicted Output Values")print(diabetes_y_pred)# Plot
outputsplt.scatter(diabetes_X_test, diabetes_y_test,
color='black')plt.plot(diabetes_X_test, diabetes_y_pred, color='red',
linewidth=1)plt.show()
輸入
輸入值:
[ [ 0.07786339] [-0.03961813] [ 0.01103904] [-0.04069594]
[-0.03422907] [ 0.00564998] [ 0.08864151] [-0.03315126] [-0.05686312]
[-0.03099563] [ 0.05522933] [-0.06009656] [ 0.00133873] [-0.02345095]
[-0.07410811] [ 0.01966154] [-0.01590626] [-0.01590626] [ 0.03906215]
[-0.0730303 ] ]
預測的輸出值:
[
225.9732401115.74763374163.27610621114.73638965
120.80385422158.21988574236.08568105121.8150983299.56772822123.83758651204.7371141196.53399594154.17490936130.9162951783.3878227171.36605897137.99500384137.99500384189.5684526884.3990668
]
結語
提一下常用的監(jiān)督學習的python庫
Scikit-Learn
Tensorflow
Pytorch
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330