人臉識(shí)別中常用的幾種分類(lèi)器
在人臉識(shí)別中有幾種常用的分類(lèi)器����,一是最鄰近分類(lèi)器;二是線(xiàn)性分類(lèi)器
(1)最鄰近分類(lèi)器
最近鄰分類(lèi)器是模式識(shí)別領(lǐng)域中最常用的分類(lèi)方法之一�,其直觀簡(jiǎn)單�,在通常的應(yīng)用環(huán)境中非常有效。因此在人臉識(shí)別問(wèn)題中有著廣泛的應(yīng)用。最鄰近方法是這樣定義的:
假設(shè)訓(xùn)練樣本(X,Y)={xi,yi | i=1,2,...n},這里xi 代表第i個(gè)樣本的特征向量�,yi是該樣本的類(lèi)別標(biāo)簽�����。對(duì)于一個(gè)新的待分類(lèi)樣本xi���,最鄰近分類(lèi)器預(yù)測(cè)該樣本的標(biāo)簽的方法是,尋找與xi距離度量最近的訓(xùn)練樣本���,然后把該訓(xùn)練樣本的標(biāo)簽作為待測(cè)試樣本xi的標(biāo)簽yi' ,即:
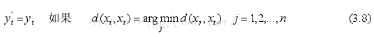
這里d(xi, xi) 代表樣本xi 與樣本xi 之間的距離度量����。
最鄰近的算法非常直觀,也容易被實(shí)現(xiàn)�,他通過(guò)距離測(cè)試樣本最近的訓(xùn)練樣本的標(biāo)簽來(lái)預(yù)測(cè)當(dāng)前測(cè)試樣本的類(lèi)別,可以適用于任何分布的數(shù)據(jù)��,而且已有文獻(xiàn)證明�,在樣本足夠多的情況下,最鄰近分類(lèi)的錯(cuò)誤率是比較理想的�。
距離度量有很多種��,一般采用的室歐氏距離�。除此之外還有相關(guān)度�����,卡方�,直方圖交,Bhattacharyya距離(又名巴氏距離)�。
1)歐氏距離 :是一個(gè)通常采用的距離定義,它是在m維空間中兩個(gè)點(diǎn)之間的真實(shí)距離�����。距離值越小�����,代表兩個(gè)直方圖距離越近���,越相似��,反之中則代表距離越遠(yuǎn)����。
2)相關(guān)度
兩直方圖之間的相關(guān)度定義如下
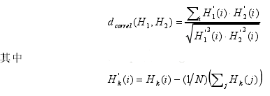
N等于直方圖中bin的個(gè)數(shù),對(duì)于相關(guān)度而言��,數(shù)值越大越匹配����。完全匹配的數(shù)值為1,完全不匹配的是-1��,值為0則表示無(wú)關(guān)聯(lián)����,兩個(gè)直方圖是隨機(jī)組合。
3)卡方Chi-Square
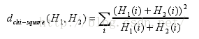
對(duì)于卡方而言����,匹配度越高��,距離越小��,則卡方值越低�����,相反���,匹配值越低��,距離越大�����,卡方值越高����。完全匹配值為0,完全不匹配的值為無(wú)限值�����。
4)直方圖交
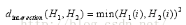
對(duì)于直方圖交����,值越大越匹配,距離越小����,越低分表示越不匹配。如果兩個(gè)直方圖都被歸一化���,那么完全匹配的值為1����,完全不匹配的值為0.
5)Bhattacharyya 距離
Bhattacharyya 距離又被稱(chēng)之為巴氏距離。巴氏距離可用來(lái)對(duì)兩組特征直方圖的相關(guān)性進(jìn)行測(cè)量����,其常用來(lái)作為分類(lèi)器算法。
定義如下: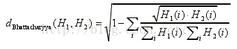
對(duì)于巴氏距離數(shù)值越小表示越匹配����,距離越近,而數(shù)值越大表示越不匹配�,距離越遠(yuǎn)。兩個(gè)直方圖完全匹配值為0��,完全不匹配值為1.
(2)線(xiàn)性分類(lèi)器
線(xiàn)性分類(lèi)器(一定意義上,也可以叫做感知機(jī))
是最簡(jiǎn)單也很有效的分類(lèi)器形式.在一個(gè)線(xiàn)性分類(lèi)器中,可以看到SVM形成的思路,并接觸很多SVM的核心概念.用一個(gè)二維空間里僅有兩類(lèi)樣本的分類(lèi)問(wèn)題來(lái)舉個(gè)小例子�。如圖所示
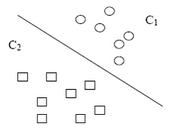
C1和C2是要區(qū)分的兩個(gè)類(lèi)別,在二維平面中它們的樣本如上圖所示���。中間的直線(xiàn)就是一個(gè)分類(lèi)函數(shù),它可以將兩類(lèi)樣本完全分開(kāi)�����。一般的,如果一個(gè)線(xiàn)性函數(shù)能夠?qū)颖就耆_的分開(kāi)�,就稱(chēng)這些數(shù)據(jù)是線(xiàn)性可分的,否則稱(chēng)為非線(xiàn)性可分的����。
LDA:
線(xiàn)性判別式分析(Linear Discriminant
Analysis, LDA),也叫做Fisher線(xiàn)性判別(Fisher Linear Discriminant
,FLD)�����,是模式識(shí)別的經(jīng)典算法�,它是在1996年由Belhumeur引入模式識(shí)別和人工智能領(lǐng)域的。性鑒別分析的基本思想是將高維的模式樣本投影到最佳鑒別矢量空間����,以達(dá)到抽取分類(lèi)信息和壓縮特征空間維數(shù)的效果,投影后保證模式樣本在新的子空間有最大的類(lèi)間距離和最小的類(lèi)內(nèi)距離����,即模式在該空間中有最佳的可分離性。因此��,它是一種有效的特征抽取方法�����。使用這種方法能夠使投影后模式樣本的類(lèi)間散布矩陣最大,并且同時(shí)類(lèi)內(nèi)散布矩陣最小���。就是說(shuō)����,它能夠保證投影后模式樣本在新的空間中有最小的類(lèi)內(nèi)距離和最大的類(lèi)間距離�����,即模式在該空間中有最佳的可分離性�����。
二. 原理簡(jiǎn)述:
LDA的原理是�����,將帶上標(biāo)簽的數(shù)據(jù)(點(diǎn))���,通過(guò)投影的方法投影到維度更低的空間中,使得投影后的點(diǎn)形成按類(lèi)別區(qū)分的情形,即相同類(lèi)別的點(diǎn)���,在投影后的空間中距離較近,不同類(lèi)別的點(diǎn)�,在投影后的空間中距離較遠(yuǎn)����。
要說(shuō)明LDA��,首先得弄明白線(xiàn)性分類(lèi)器(Linear Classifier):因?yàn)長(zhǎng)DA是一種線(xiàn)性分類(lèi)器����。對(duì)于K-分類(lèi)的一個(gè)分類(lèi)問(wèn)題�,會(huì)有K個(gè)線(xiàn)性函數(shù):
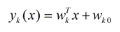
當(dāng)滿(mǎn)足條件:對(duì)于所有的j���,都有Yk > Yj,的時(shí)候�����,我們就說(shuō)x屬于類(lèi)別k�����。對(duì)于每一個(gè)分類(lèi),都會(huì)用一個(gè)公式去計(jì)算一個(gè)得分值�����,所有公式的結(jié)果中得分最高的那個(gè)類(lèi)別�,就是所屬的分類(lèi)了����。
上式實(shí)際上就是一種投影,是將一個(gè)高維的點(diǎn)投影到一條高維的直線(xiàn)上����,LDA最求的目標(biāo)是,給出一個(gè)標(biāo)注了類(lèi)別的數(shù)據(jù)集�,投影到了一條直線(xiàn)之后����,能夠使得點(diǎn)盡量的按類(lèi)別區(qū)分開(kāi)���,當(dāng)k=2即二分類(lèi)問(wèn)題的時(shí)候�,如下圖所示:
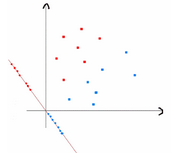
紅色的方形的點(diǎn)為0類(lèi)的原始點(diǎn)、藍(lán)色的方形點(diǎn)為1類(lèi)的原始點(diǎn),經(jīng)過(guò)原點(diǎn)的那條線(xiàn)就是投影的直線(xiàn)��,從圖上可以清楚的看到��,紅色的點(diǎn)和藍(lán)色的點(diǎn)被原點(diǎn)明顯的分開(kāi)了�,這個(gè)數(shù)據(jù)只是隨便畫(huà)的��,如果在高維的情況下���,看起來(lái)會(huì)更好一點(diǎn)。下面我來(lái)推導(dǎo)一下二分類(lèi)LDA問(wèn)題的公式:
假設(shè)用來(lái)區(qū)分二分類(lèi)的直線(xiàn)(投影函數(shù))為:
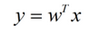
LDA分類(lèi)的一個(gè)目標(biāo)是使得不同類(lèi)別之間的距離越遠(yuǎn)越好��,同一類(lèi)別之中的距離越近越好,所以我們需要定義幾個(gè)關(guān)鍵的值。
類(lèi)別i的原始中心點(diǎn)為:(Di表示屬于類(lèi)別i的點(diǎn))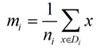
類(lèi)別i投影后的中心點(diǎn)為:
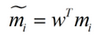
衡量類(lèi)別i投影后���,類(lèi)別點(diǎn)之間的分散程度(方差)為:
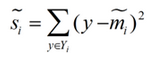
最終我們可以得到一個(gè)下面的公式,表示LDA投影到w后的損失函數(shù):
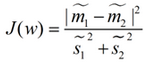
我們分類(lèi)的目標(biāo)是,使得類(lèi)別內(nèi)的點(diǎn)距離越近越好(集中)��,類(lèi)別間的點(diǎn)越遠(yuǎn)越好。分母表示每一個(gè)類(lèi)別內(nèi)的方差之和����,方差越大表示一個(gè)類(lèi)別內(nèi)的點(diǎn)越分散����,分子為兩個(gè)類(lèi)別各自的中心點(diǎn)的距離的平方�,我們最大化J(w)就可以求出最優(yōu)的w了。想要求出最優(yōu)的w����,可以使用拉格朗日乘子法,但是現(xiàn)在我們得到的J(w)里面�,w是不能被單獨(dú)提出來(lái)的,我們就得想辦法將w單獨(dú)提出來(lái)�。
我們定義一個(gè)投影前的各類(lèi)別分散程度的矩陣,這個(gè)矩陣的意思是���,如果某一個(gè)輸入點(diǎn)集Di里面的點(diǎn)距離這個(gè)分類(lèi)的中心點(diǎn)mi越近��,則Si里面元素的值就越小��,如果分類(lèi)的點(diǎn)都緊緊地圍繞著mi���,則Si里面的元素值越更接近0.
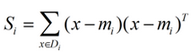
帶入Si,將J(w)分母化為:
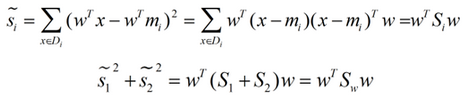

同樣的將J(w)分子化為:
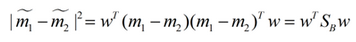
這樣損失函數(shù)可以化成下面的形式����,我們的目標(biāo)是求取它的最大值:
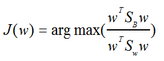
這樣就可以用拉格朗日乘子法了��,但是還有一個(gè)問(wèn)題����,如果分子��、分母是都可以取任意值的��,那就會(huì)使得有無(wú)窮解����,我們將分母限制為長(zhǎng)度為1(這是用拉格朗日乘子法一個(gè)很重要的技巧),并作為拉格朗日乘子法的限制條件�����,帶入得到:
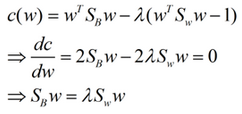
求導(dǎo)公式如下:
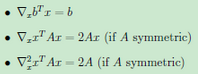
這樣的式子就是一個(gè)求特征值的問(wèn)題了�����。
對(duì)于N(N>2)分類(lèi)的問(wèn)題�,我就直接寫(xiě)出下面的結(jié)論了:
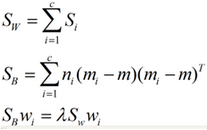
又因?yàn)閣=[w1,w2...wd]����,所以得到:
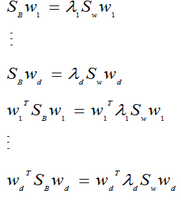
把損失函數(shù)分解可知����,我們要求的是:
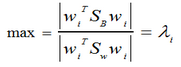
最佳投影矩陣的列向量即為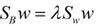 的d個(gè)最大的特征值所對(duì)應(yīng)的特征向量(矩陣
的d個(gè)最大的特征值所對(duì)應(yīng)的特征向量(矩陣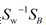 的特征向量)�,且最優(yōu)投影軸的個(gè)數(shù)d<=c-1(c表示類(lèi)的個(gè)數(shù)).
的特征向量)�,且最優(yōu)投影軸的個(gè)數(shù)d<=c-1(c表示類(lèi)的個(gè)數(shù)).
這里想多談?wù)?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征值,特征值在純數(shù)學(xué)��、量子力學(xué)�、固體力學(xué)、計(jì)算機(jī)等等領(lǐng)域都有廣泛的應(yīng)用��,特征值表示的是矩陣的性質(zhì)���,當(dāng)我們?nèi)〉骄仃嚨那癗個(gè)最大的特征值的時(shí)候���,我們可以說(shuō)提取到的矩陣主要的成分(這個(gè)和之后的PCA相關(guān),但是不是完全一樣的概念)����。在機(jī)器學(xué)習(xí)領(lǐng)域,不少的地方都要用到特征值的計(jì)算�����,比如說(shuō)圖像識(shí)別、pagerank��、LDA�����、還有之后將會(huì)提到的PCA等等���。
Fisher線(xiàn)性判別是PCA+LDA����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330