機器學(xué)習(xí)故事匯-決策樹算法
【咱們的目標】系列算法講解旨在用最簡單易懂的故事情節(jié)幫助大家掌握晦澀無趣的機器學(xué)習(xí)��,適合對數(shù)學(xué)很頭疼的同學(xué)們���,小板凳走起�!
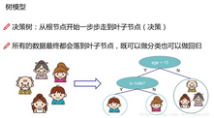
決策樹模型是機器學(xué)習(xí)中最經(jīng)典的算法之一啦���,用途之廣泛我就不多吹啦���,其實很多機器學(xué)習(xí)算法都是以樹模型為基礎(chǔ)的����,比如隨機森林,Xgboost等一聽起來就是很牛逼的算法(其實用起來也很牛逼)�����。
首先我們來看一下在上面的例子中我想根據(jù)人的年齡和性別(兩個特征)對5個人(樣本數(shù)據(jù))進行決策���,看看他們喜不喜歡玩電腦游戲����。首先根據(jù)年齡(根節(jié)點)進行了一次分支決策��,又對左節(jié)點根據(jù)性別進行了一次分支決策����,這樣所有的樣本都落到了最終的葉子節(jié)點,可以把每一個葉子節(jié)點當(dāng)成我們最終的決策結(jié)果(比如Y代表喜歡玩游戲����,N代表不喜歡玩游戲)。這樣我們就通過決策樹完成了非常簡單的分類任務(wù)�!
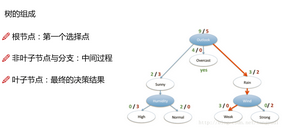
再來看一下樹的組成�,主要結(jié)構(gòu)有根節(jié)點(數(shù)據(jù)來了之后首先進行判斷的特征)���,非葉子節(jié)點(中間的一系列過程)���,葉子節(jié)點(最終的結(jié)果)��,這些都是我們要建立的模塊�!

在決策中樹中,我們剛才的喜歡玩電腦游戲的任務(wù)看起來很簡單嘛���,從上往下去走不就OK了嗎����!但是難點在于我們該如何構(gòu)造這棵決策樹(節(jié)點的選擇以及切分)�����,這個看起來就有些難了�����,因為當(dāng)我們手里的數(shù)據(jù)特征比較多的時候就該猶豫了�����,到底拿誰當(dāng)成是根節(jié)點呢?

這個就是我們最主要的問題啦�����,節(jié)點究竟該怎么選呢��?不同的位置又有什么影響���?怎么對特征進行切分呢�?一些到這�����,我突然想起來一個段子�,咱們來樂呵樂呵!

武林外傳中這個段子夠我笑一年的�����,其實咱們在推導(dǎo)機器學(xué)習(xí)算法的時候�����,也需要這么去想想,只有每一步都是有意義的我們才會選擇去使用它��?��;貧w正題����,我們選擇的根節(jié)點其實意味著它的重要程度是最大的��,相當(dāng)于大當(dāng)家了��,因為它會對數(shù)據(jù)進行第一次切分���,我們需要把最重要的用在最關(guān)鍵的位置,在決策樹算法中���,為了使得算法能夠高效的進行����,那么一開始就應(yīng)當(dāng)使用最有價值的特征��。

接下來咱們就得嘮嘮如何選擇大當(dāng)家了����,我們提出了一個概念叫做熵(不是我提出的���。。����。穿山甲說的),這里并不打算說的那么復(fù)雜���,一句話解釋一下�,熵代表你經(jīng)過一次分支之后分類的效果的好壞�����,如果一次分支決策后都屬于一個類別(理想情況下��,也是我們的目標)這時候我們認為效果很好嘛�,那熵值就很低。如果分支決策后效果很差�,什么類別都有,那么熵值就會很高�,公式已經(jīng)給出,log函數(shù)推薦大家自己畫一下�����,然后看看概率[0,1]上的時候log函數(shù)值的大小(你會豁然開朗的)����。

不確定性什么時候最大呢?模棱兩可的的時候(就是你猶豫不決的時候)這個時候熵是最大的��,因為什么類別出現(xiàn)的可能性都有�。那么我們該怎么選大當(dāng)家呢?(根節(jié)點的特征)當(dāng)然是希望經(jīng)過大當(dāng)家決策后����,熵值能夠下降(意味著類別更純凈了�,不那么混亂了)。在這里我們提出了一個詞叫做信息增益(就當(dāng)是我提出的吧����。。�����。)���,信息增益表示經(jīng)過一次決策后整個分類后的數(shù)據(jù)的熵值下降的大小����,我們希望下降越多越好,理想情況下最純凈的熵是等于零的�����。

一個栗子:準備一天一個哥們打球的時候��,包括了4個特征(都是環(huán)境因素)以及他最終有木有去打球的數(shù)據(jù)��。
第一個問題:大當(dāng)家該怎么選�?也就是我們的根節(jié)點用哪個特征呢��?
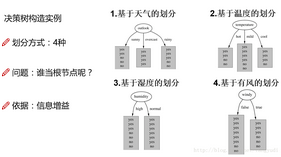
一共有4個特征���,看起來好像用誰都可以呀�����,這個時候就該比試比試了,看看誰的能力強(使得熵值能夠下降的最多)

在歷史數(shù)據(jù)中����,首先我們可以算出來當(dāng)前的熵值�,計算公式同上等于0.940���,大當(dāng)家的競選我們逐一來分析�����,先看outlook這個特征���,上圖給出了基于天氣的劃分之后的熵值,計算方式依舊同上��,比如outlook=sunny時���,yes有2個,no有三個這個時候熵就直接將2/5和3/5帶入公式就好啦���。最終算出來了3種情況下的熵值����。

再繼續(xù)來看!outlook取不同情況的概率也是不一樣的���,這個是可以計算出來的相當(dāng)于先驗概率了�����,直接可以統(tǒng)計出來的���,這個也需要考慮進來的�����。然后outlook競選大當(dāng)家的分值就出來啦(就是信息增益)等于0.247�。同樣的方法其余3個特征的信息增益照樣都可以計算出來��,誰的信息增益多我們就認為誰是我們的大當(dāng)家���,這樣就完成了根節(jié)點的選擇�����,接下來二當(dāng)家以此類推就可以了�����!

我們剛才給大家講解的是經(jīng)典的ID3算法���,基于熵值來構(gòu)造決策樹���,現(xiàn)在已經(jīng)有很多改進,比如信息增益率和CART樹��。簡單來說一下信息增益率吧��,我們再來考慮另外一個因素����,如果把數(shù)據(jù)的樣本編號當(dāng)成一個特征,那么這個特征必然會使得所有數(shù)據(jù)完全分的開��,因為一個樣本只對應(yīng)于一個ID��,這樣的熵值都是等于零的����,所以為了解決這類特征引入了信息增益率,不光要考慮信息增益還要考慮特征自身的熵值����。說白了就是用
信息增益/自身的熵值 來當(dāng)做信息增益率����。
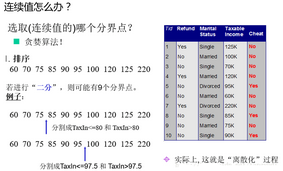
我們剛才討論的例子中使用的是離散型的數(shù)據(jù)��,那連續(xù)值的數(shù)據(jù)咋辦呢���?通常我們都用二分法來逐一遍歷來找到最合適的切分點!

下面再來嘮一嘮決策樹中的剪枝任務(wù)����,為啥要剪枝呢?樹不是好好的嗎��,剪個毛線?�?����!這個就是機器學(xué)習(xí)中老生常談的一個問題了���,過擬合的風(fēng)險��,說白了就是如果一個樹足夠龐大���,那么所有葉子節(jié)點可能只是一個數(shù)據(jù)點(無限制的切分下去)�����,這樣會使得我們的模型泛化能力很差���,在測試集上沒辦法表現(xiàn)出應(yīng)有的水平,所以我們要限制決策樹的大小���,不能讓枝葉太龐大了����。
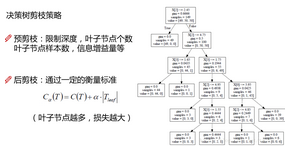
最常用的剪枝策略有兩種:
(1)預(yù)剪枝:邊建立決策樹邊開始剪枝的操作
(2)后剪枝:建立完之后根據(jù)一定的策略來修建
這些就是我們的決策樹算法啦�,其實還蠻好的理解的,從上到下基于一種選擇標準(熵���,GINI系數(shù))來找到最合適的當(dāng)家的就可以啦�����!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330