R語言使用密度聚類筆法處理數(shù)據(jù)
說明
除了使用距離作為聚類指標(biāo)�����,還可以使用密度指標(biāo)來對(duì)數(shù)據(jù)進(jìn)行聚類處理,將分布稠密的樣本與分布稀疏的樣本分離開���。DBSCAN是最著名的密度聚類算法����。
操作
將使用mlbench包提供的仿真數(shù)據(jù)
library(mlbench)
library(fpc)
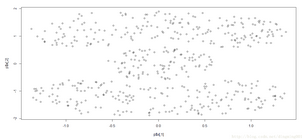
使用mlbench庫繪制Cassini問題圖:
set.seed(2)
p = mlbench.cassini(500)
plot(p$x)
根據(jù)數(shù)據(jù)密度完成聚類:
ds = dbscan(dist(p$x),0.2,2,countmode = NULL,method = "dist")
> ds
dbscan Pts=500 MinPts=2 eps=0.2
1 2 3
seed 200 200 100
total 200 200 100
繪制聚類結(jié)果散點(diǎn)圖��,屬于不同簇的數(shù)據(jù)點(diǎn)選用不的顏色:
plot(ds,p$x)
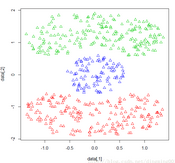
根據(jù)聚簇標(biāo)號(hào)繪制的彩色散點(diǎn)圖
調(diào)用dbscan來預(yù)測數(shù)據(jù)點(diǎn)可能被劃分到那個(gè)簇�,在樣例中,首先在矩陣P中處理三個(gè)輸入值:
生成y矩陣
y = matrix(0,nrow = 3,ncol = 2)
y[1,] = c(0,0)
y[2,] = c(0,-1.5)
y[3,] = c(1,1)
y
[,1] [,2]
[1,] 0 0.0
[2,] 0 -1.5
[3,] 1 1.0
預(yù)測數(shù)據(jù)點(diǎn)屬于那個(gè)簇:
predict(ds,p$x,y)
[1] 3 1 2
原理
基于密度的聚類算法利用了密度可達(dá)以及密度相連的特點(diǎn)����,因而適用于處理非線性聚類問題����。當(dāng)探討密度聚類算法的處理過程前����,我們要知道基于密度的聚類算法通常需要考慮兩個(gè)參數(shù),eps和MinPts�,其中eps為最大領(lǐng)域半徑,MinPts是領(lǐng)域半徑范圍內(nèi)的最小點(diǎn)數(shù)��。
確定好這兩個(gè)參數(shù)后��,如果給定對(duì)象其領(lǐng)域范圍內(nèi)的樣本點(diǎn)個(gè)數(shù)大于MinPts���,則稱該對(duì)象為核心點(diǎn)����。
如果一個(gè)對(duì)象其領(lǐng)域半徑范圍內(nèi)的樣本點(diǎn)個(gè)數(shù)小于MinPts,但緊挨著核心點(diǎn)����,則稱該對(duì)象為邊緣點(diǎn)。
如果P對(duì)象的eps領(lǐng)域范圍內(nèi)樣本點(diǎn)個(gè)數(shù)大于MinPts,則稱該對(duì)象為核心對(duì)象�����。
進(jìn)一步,我們還要定義兩點(diǎn)間密度可達(dá)的概念��,給定兩點(diǎn)p和q,如果p為核心對(duì)象���,且q在p的eps鄰域內(nèi),則稱p直接密度可以達(dá)q�����。如果存在一系列的點(diǎn)����,p1,p2,…,pn。且p1 = q,pn = p,根據(jù)Eps和MinPts的值���,當(dāng)1<=i<=n,pi + 1 直接密度可以達(dá)pi�,則稱p的一般密度可以達(dá)q����。
DBSCAN處理過程:
1.隨機(jī)選擇一個(gè)點(diǎn)p
2.給定Eps和MinPts的條件下,獲得所有p密度可達(dá)的點(diǎn)
3.如果p是核心對(duì)象���,則p和所有p密度可達(dá)的點(diǎn)被標(biāo)記成一個(gè)簇��,如果p是一個(gè)邊緣點(diǎn)����,找不到密度可達(dá)點(diǎn),則將其標(biāo)記為噪聲��。接著處理其它點(diǎn)����。
4.重復(fù)這個(gè)過程,直到所有的點(diǎn)被處理�����。
本例使用dbscan算法聚類Cassini數(shù)據(jù)集��,將可達(dá)距離設(shè)置為0.2��,最小可達(dá)點(diǎn)個(gè)數(shù)設(shè)置為2,計(jì)算進(jìn)度設(shè)為NULL����,使用距離矩陣做為計(jì)算依據(jù)。經(jīng)過算法處理�����,數(shù)據(jù)被劃分成三個(gè)簇,每個(gè)簇的大小分別為200���,200����,100.通過聚簇的結(jié)果示意圖也可以發(fā)現(xiàn)Cassini圖被不同顏色區(qū)分開來�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330