回歸預(yù)測(cè)及R語(yǔ)言實(shí)現(xiàn)Part2回歸R語(yǔ)言實(shí)現(xiàn)
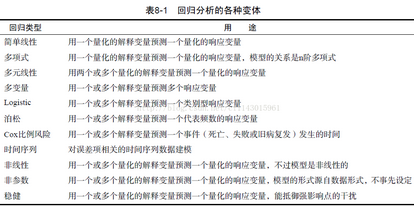
下面是回歸分析的各種變體的簡(jiǎn)單介紹,解釋變量和相應(yīng)變量就是指自變量和因變量����。
常用普通最小二乘(OLS)回歸法來(lái)擬合實(shí)現(xiàn)簡(jiǎn)單線性、多項(xiàng)式和多元線性等回歸模型����。最小二乘法的基本原理前面已經(jīng)說(shuō)明了,使得預(yù)測(cè)值和觀察值之差最小���。
R中實(shí)現(xiàn)擬合線性模型最基本的函數(shù)是lm()���,應(yīng)用格式為:
myfit <- lm(Y~X1+X2+…+Xk,data)
data為觀測(cè)數(shù)據(jù)���,應(yīng)該為一個(gè)data.frame�����,前面是擬合表達(dá)式�����,Y是因變量���,X1-Xk是自變量����,+用來(lái)分隔不同的自變量的�����,還有可能用到的其他符號(hào)的說(shuō)明如下:

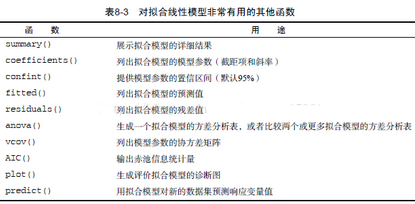
另外�����,對(duì)lm()方法的返回結(jié)果���,還有一系列的分析方法���,如下:
簡(jiǎn)單線性回歸
基礎(chǔ)安裝數(shù)據(jù)women中提供了15個(gè)年齡在30-39歲之前的女性的身高和體重信息,這里用身高來(lái)預(yù)測(cè)體重�����,來(lái)嘗試lm()方法
[plain]view plaincopy
par(ask = TRUE)
opar <- par(no.readonly = TRUE)
fit <- lm(weight ~ height, data = women)
summary(fit)
women$weight
fitted(fit)
residuals(fit)
plot(women$height, women$weight, main = "30-39的女性",xlab = "身高(英尺)", ylab = "體重(鎊)")#觀測(cè)數(shù)據(jù)散點(diǎn)圖
abline(fit)#擬合線
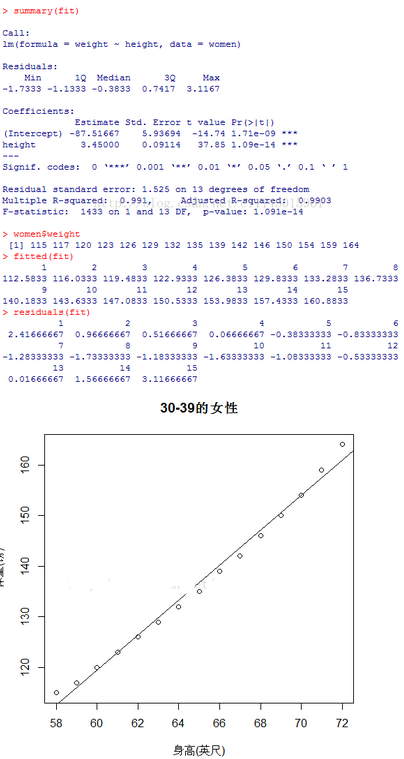
由summary(fit)的結(jié)果coefficients可看出��,預(yù)測(cè)模型為:weight=-81.52+3.45*height����。
因?yàn)樯砀卟豢赡転?�,你沒(méi)必要給截距項(xiàng)一個(gè)物理解釋���,它僅僅是一個(gè)常量調(diào)整項(xiàng)���。在Pr(>|t|)欄,可以看到回歸系數(shù)(3.45)顯著(p<0.001)�,表明身高每增高1英寸,體重將預(yù)期增加3.45磅��?����?蓻Q系數(shù)-R平方項(xiàng)(0.991)表明模型可以解釋體重99.1%的方差����,它也是實(shí)際和預(yù)測(cè)值之間的相關(guān)系數(shù)的平方值����。殘差標(biāo)準(zhǔn)誤差(1.53
lbs)則可認(rèn)為是模型用身高預(yù)測(cè)體重的平均誤差。F統(tǒng)計(jì)量檢驗(yàn)所有的預(yù)測(cè)變量預(yù)測(cè)響應(yīng)變量是否都在某個(gè)幾率水平之上����。由于簡(jiǎn)單回歸只有一個(gè)預(yù)測(cè)變量���,此處F檢驗(yàn)等同于身高回歸系數(shù)的t檢驗(yàn)����。
多項(xiàng)式回歸
從上面例子最后的圖可以看出���,我們可以為回歸模型增加一個(gè)X平方項(xiàng)來(lái)增加預(yù)測(cè)精確度���。
[plain]view plaincopy
fit2 <- lm(weight ~ height + I(height^2), data = women)
summary(fit2)
plot(women$height, women$weight, main = "30-39的女性",xlab = "身高(英尺)", ylab = "體重(鎊)")#觀測(cè)數(shù)據(jù)散點(diǎn)圖
lines(women$height, fitted(fit2))
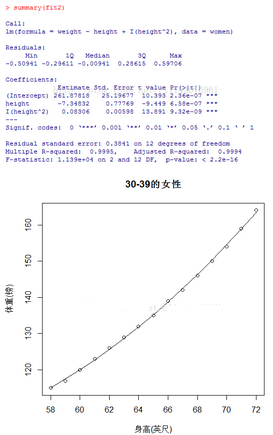
由summary(fit2)的結(jié)果coefficients可看出,預(yù)測(cè)模型為:weight=261.88-7.35*height+0.083*
height* height��。在p<0.001水平下�,回歸系數(shù)都非常顯著。模型的方差解釋率已經(jīng)增加到了99.9%����。二次項(xiàng)的顯著性(t =
13.89,p<0.001)表明包含二次項(xiàng)提高了模型的擬合度�。從圖中也能看出來(lái),預(yù)測(cè)值和觀測(cè)值的擬合程度更好了����。
介紹下car包中的scatterplot()函數(shù)�,它可以很容易���、方便地繪制二元關(guān)系圖����。
[plain]view plaincopy
library(car)
scatterplot(weight ~ height, data = women,spread = FALSE, lty.smooth = 2, pch = 19, main ="30-39的女性", xlab = "身高(英尺)", ylab = "體重(鎊)")
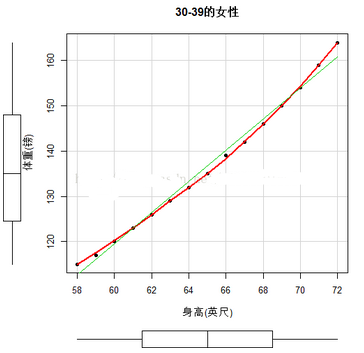
如上�����,是scatterplot()對(duì)women數(shù)據(jù)所繪的身高與體重的散點(diǎn)圖�。直線為線性擬合,虛線為曲線平滑擬合�,邊界為箱線圖。
多元線性回歸
這里以基礎(chǔ)包中的state.x77數(shù)據(jù)集為例���,探究一個(gè)州的犯罪率和其他因素的關(guān)系��,包括人口�、文盲率��、平均收入和結(jié)霜天數(shù)(溫度在冰點(diǎn)以下的平均天數(shù))�。
[plain]view plaincopy
states <- as.data.frame(state.x77[, c("Murder","Population", "Illiteracy", "Income","Frost")])
colnames(states) <- c("謀殺率", "人口","文盲率", "收入水平", "結(jié)霜天數(shù)")
cor(states)
library(car)
scatterplotMatrix(states, spread = FALSE, main = "ScatterplotMatrix")
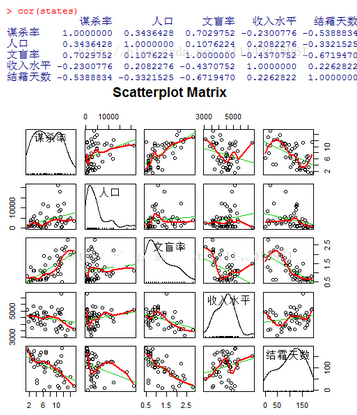
cor()函數(shù)顯示兩個(gè)變量之間的相關(guān)系數(shù),從圖中可以看到�,謀殺率是雙峰的曲線,每個(gè)預(yù)測(cè)變量都一定程度上出現(xiàn)了偏斜����。謀殺率隨著人口和文盲率的增加而增加,隨著收入水平和結(jié)霜天數(shù)增加而下降�����。同時(shí)���,越冷的州文盲率越低���,收入水平越高。
下面對(duì)states數(shù)據(jù)做多項(xiàng)線性擬合���,看人口�����、文盲率�、收入水平����、結(jié)霜天數(shù)對(duì)謀殺率的影響水平���。
[plain]view plaincopy
colnames(states) <- c("Murder", "Population","Illiteracy", "Income", "Frost")
fit <- lm(Murder ~ Population + Illiteracy + Income + Frost, data= states)
summary(fit)
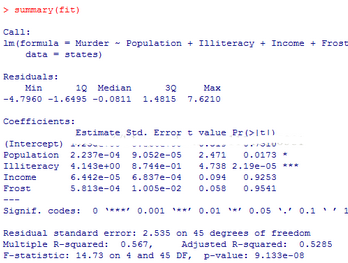
從結(jié)果可以看出,文盲率和人口的系數(shù)是顯著的�,結(jié)霜率和收入水平系數(shù)不顯著,這兩者對(duì)謀殺率的影響不是線性的��。
上面的例子是自變量之間相互獨(dú)立的�,下面看一個(gè)有交互項(xiàng)的多元線性回歸的案例。同樣是R中的基礎(chǔ)安裝數(shù)據(jù)mtcars��,
[plain]view plaincopy
fit <- lm(mpg ~ hp + wt + hp:wt, data = mtcars)
summary(fit)
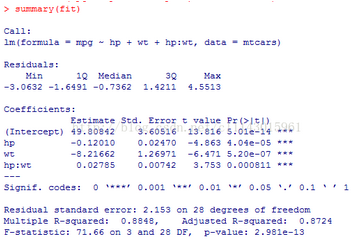
從summary(fit)的Pr(>|t|)欄中能看出�,hp:wt項(xiàng)是顯著的,說(shuō)明汽車(chē)的馬力和車(chē)重不是相互獨(dú)立的���,兩者對(duì)每英里的耗油量的影響也都是顯著的���。
汽車(chē)每英里耗油量mpg的模型為mpg =49.81 + 0.12×hp + 8.22×wt + 0.03×hp×wt。
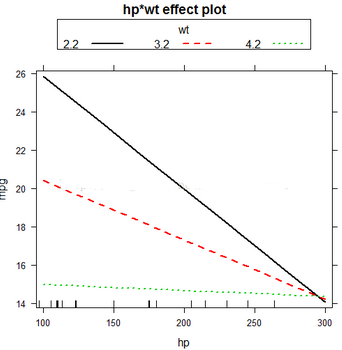
effects包可以用來(lái)分析不同wt下����,mpg與hp之間的線性關(guān)系。如下�����,圖中能看出�,當(dāng)wt分別為2.2,3.2,4.2時(shí)mpg與hp之間的線性關(guān)系,差異還是很明顯的�。
[plain]view plaincopy
library(effects)
plot(effect("hp:wt", fit, xlevels= list(wt = c(2.2, 3.2,4.2))), multiline = TRUE)
回歸診斷
summary()方法能獲取模型的參數(shù)和相關(guān)統(tǒng)計(jì)量,要進(jìn)一步診斷模型是否合適�����,還需要另外的工作����。
R中有許多檢驗(yàn)回歸分析中統(tǒng)計(jì)假設(shè)的方法。plot()方法可以生成評(píng)價(jià)模型擬合情況的四幅圖形���。用women數(shù)據(jù)集的回歸模型為例:
[plain]view plaincopy
fit <- lm(weight ~ height, data = women)
par(mfrow = c(2, 2))
plot(fit)
par(opar)
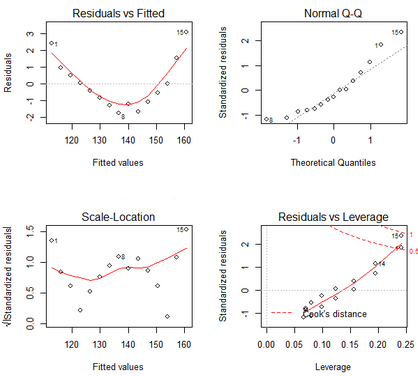
OLS回歸的統(tǒng)計(jì)假設(shè)�。(擔(dān)心我自己的理解有偏誤��,所以這里的解讀全部摘抄自R語(yǔ)言實(shí)戰(zhàn)?����。?
正態(tài)性當(dāng)預(yù)測(cè)變量值固定時(shí)��,因變量成正態(tài)分布,則殘差值也應(yīng)該是一個(gè)均值為0的正態(tài)分布���。正態(tài)Q-Q圖(Normal
Q-Q���,右上)是在正態(tài)分布對(duì)應(yīng)的值下,標(biāo)準(zhǔn)化殘差的概率圖��。若滿足正態(tài)假設(shè)�,那么圖上的點(diǎn)應(yīng)該落在呈45度角的直線上;若不是如此�,那么就違反了正態(tài)性的假設(shè)。
獨(dú)立性你無(wú)法從這些圖中分辨出因變量值是否相互獨(dú)立�,只能從收集的數(shù)據(jù)中來(lái)驗(yàn)證。上面的例子中��,沒(méi)有任何先驗(yàn)的理由去相信一位女性的體重會(huì)影響另外一位女性的體重�。假若你發(fā)現(xiàn)數(shù)據(jù)是從一個(gè)家庭抽樣得來(lái)的,那么可能必須要調(diào)整模型獨(dú)立性的假設(shè)�����。
線性若因變量與自變量線性相關(guān)��,那么殘差值與預(yù)測(cè)(擬合)值就沒(méi)有任何系統(tǒng)關(guān)聯(lián)��。換句話說(shuō),除了白噪聲�����,模型應(yīng)該包含數(shù)據(jù)中所有的系統(tǒng)方差��。在“殘差圖與擬合圖”(Residuals
vs Fitted���,左上)中可以清楚的看到一個(gè)曲線關(guān)系,這暗示著你可能需要對(duì)回歸模型加上一個(gè)二次項(xiàng)��。
同方差性若滿足不變方差假設(shè)�,那么在位置尺度圖(Scale-Location Graph,左下)中�����,水平線周?chē)狞c(diǎn)應(yīng)該隨機(jī)分布����。該圖似乎滿足此假設(shè)。
最后一幅“殘差與杠桿圖”(Residualsvs Leverage����,右下)提供了你可能需要關(guān)注的單個(gè)觀測(cè)點(diǎn)的信息����。從圖形可以鑒別出離群點(diǎn)�、高杠桿值點(diǎn)和強(qiáng)影響點(diǎn)。
一個(gè)觀測(cè)點(diǎn)是離群點(diǎn)�,表明擬合回歸模型對(duì)其預(yù)測(cè)效果不佳(產(chǎn)生了巨大的或正或負(fù)的殘差)。
一個(gè)觀測(cè)點(diǎn)有很高的杠桿值���,表明它是一個(gè)異常的預(yù)測(cè)變量值的組合���。也就是說(shuō),在預(yù)測(cè)變量空間中���,它是一個(gè)離群點(diǎn)����。因變量值不參與計(jì)算一個(gè)觀測(cè)點(diǎn)的杠桿值��。
一個(gè)觀測(cè)點(diǎn)是強(qiáng)影響點(diǎn)(influentialobservation)�����,表明它對(duì)模型參數(shù)的估計(jì)產(chǎn)生的影響過(guò)大�,非常不成比例��。強(qiáng)影響點(diǎn)可以通過(guò)Cook距離即Cook’s D統(tǒng)計(jì)量來(lái)鑒別��。
再來(lái)看二次擬合的診斷圖�。
[plain]view plaincopy
newfit <- lm(weight ~ height + I(height^2), data = women)
par(mfrow = c(2, 2))
plot(newfit)
par(opar)
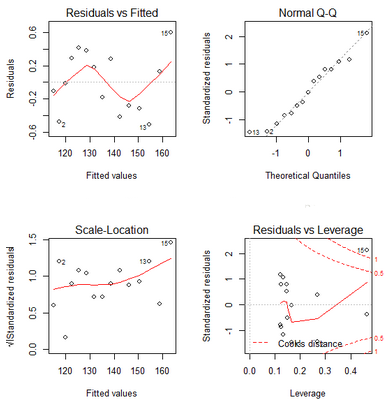
圖中有兩個(gè)比較明顯的離群點(diǎn)��,12和15���,可以刪除這兩個(gè)點(diǎn)后再做回歸�,效果會(huì)更好���。
[plain]view plaincopy
newfit <- lm(weight ~ height + I(height^2), data = women[-c(13,15),])
par(mfrow = c(2, 2))
plot(newfit)
par(opar)
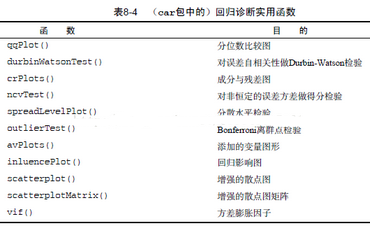
另外car包中提供了許多方法可以增強(qiáng)擬合和評(píng)價(jià)回歸模型的能力,如下圖�,不再細(xì)說(shuō):
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330