SPSS進行逐步回歸分析
在自變量很多時���,其中有的因素可能對應變量的影響不是很大����,而且x之間可能不完全相互獨立的�,可能有種種互作關系���。在這種情況下可用逐步回歸分析�,進行x因子的篩選�����,這樣建立的多元回歸模型預測效果會更較好。
逐步回歸分析����,首先要建立因變量y與自變量x之間的總回歸方程,再對總的方程及每—個自變量進行假設檢驗����。當總的方程不顯著時���,表明該多元回歸方程線性關系不成立��;而當某—個自變量對y影響不顯著時,應該把它剔除�,重新建立不包含該因子的多元回歸方程�。篩選出有顯著影響的因子作為自變量��,并建立“最優(yōu)”回歸方程���。
回歸方程包含的自變量越多�,回歸平方和越大����,剩余的平方和越小���,剩余均方也隨之較小,預測值 的誤差也愈小�,模擬的效果愈好。但是方程中的變量過多�����,預報工作量就會越大���,其中有些相關性不顯著的預報因子會影響預測的效果��。因此在多元回歸模型中���,選擇適宜的變量數(shù)目尤為重要��。
的誤差也愈小�,模擬的效果愈好。但是方程中的變量過多�����,預報工作量就會越大���,其中有些相關性不顯著的預報因子會影響預測的效果��。因此在多元回歸模型中���,選擇適宜的變量數(shù)目尤為重要��。
逐步回歸在病蟲預報中的應用實例:
以陜西省長武地區(qū)1984~1995年的煙蚜傳毒病情資料�、相關蟲情和氣象資料為例(數(shù)據(jù)見DATA6.xls)�,建立蚜傳病毒病情指數(shù)的逐步回歸模型,說明逐步回歸分析的具體步驟�����。影響蚜傳病毒病情指數(shù)的蟲情因子和氣象因子一共有21個��,通過逐步回歸��,從中選出對病情指數(shù)影響顯著的因子�����,從而建立相應的模型。對1984~1995年的病情指數(shù)進行回檢��,然后對1996~1998年的病情進行預報�����,再檢驗預報的效果�。
變量說明如下:
y:歷年病情指數(shù)
x1:前年冬季油菜越冬時的蚜量(頭/株)
x2:前年冬季極端氣溫
x3:5月份最高氣溫
x4:5月份最低氣溫
x5:3~5月份降水量
x6:4~6月份降水量
x7:3~5月份均溫
x8:4~6月份均溫
x9:4月份降水量
x10:4月份均溫
|
x11:5月份均溫
x12:5月份降水量
x13:6月份均溫
x14:6月份降水量
x15:第一次蚜遷高峰期百株煙草有翅蚜量
x16:5月份油菜百株蚜量
x17:7月份降水量
x18:8月份降水量
x19:7月份均溫
x20:8月份均溫
x21:元月均溫
|
1)準備分析數(shù)據(jù)
在SPSS數(shù)據(jù)編輯窗口中,用“File→Open→Data”命令�,打開“DATA6.xls”數(shù)據(jù)文件。數(shù)據(jù)工作區(qū)如下圖3-1顯示����。

圖3-1
2)啟動線性回歸過程
單擊SPSS主菜單的“Analyze”下的“Regression”中“Linear”項���,將打開如圖3-2所示的線性回歸過程窗口�����。

圖3-2 線性回歸對話窗口
3) 設置分析變量
設置因變量:將左邊變量列表中的“y”變量���,選入到“Dependent”因變量顯示欄里�。
設置自變量:將左邊變量列表中的“x1”~“x21”變量����,全部選移到“Independent(S)”自變量欄里。
設置控制變量: 本例子中不使用控制變量��,所以不選擇任何變量�����。
選擇標簽變量: 選擇“年份”為標簽變量��。
選擇加權變量: 本例子沒有加權變量���,因此不作任何設置。
4)回歸方式
在“Method”分析方法框中選中“Stepwise”逐步分析方法�����。該方法是根據(jù)“Options”選擇對話框中顯著性檢驗(F)的設置,在方程中進入或剔除單個變量�����,直到所建立的方程中不再含有可加入或可剔除的變量為止�。設置后的對話窗口如圖3-3。

圖3-3
5)設置變量檢驗水平
在圖6-15主對話框里單擊“Options”按鈕�,將打開如圖3-4所示的對話框。

圖3-4
“Stepping Method Criteria”框里的設置用于逐步回歸分析的選擇標準�����。
其中“Use probability of
F”選項����,提供設置顯著性F檢驗的概率。如果一個變量的F檢驗概率小于或等于進入“Entry”欄里設置的值��,那么這個變量將被選入回歸方程中�;當回歸方程中變量的F值檢驗概率大于剔除“Removal”欄里設置的值,則該變量將從回歸方程中被剔除���。由此可見�����,設置F檢驗概率時�,應使進入值小于剔除值。
“Ues F
value” 選項�����,提供設置顯著性F檢驗的分布值����。如果一個變量的F值大于所設置的進入值(Entry),那么這個變量將被選入回歸方程中���;當回歸方程中變量的F值小于設置的剔除值(Removal)��,則該變量將從回歸方程中被剔除����。同時����,設置F分布值時���,應該使進入值大于剔除值�����。
本例子使用顯著性F檢驗的概率�����,在進入“Entry”欄里設置為“0.15”��,在剔除“Removal”欄里設置為“0.20”(剔除的概率值應比進入的值大)�,如圖6-17所示。
圖6-17窗口中的其它設置參照一元回歸設置�����。
6)設置輸出統(tǒng)計量
在主對話圖3-2窗口中����,單擊“Statistics”按鈕,將打開如圖6-18所示的對話框�����。該對話框用于設置相關參數(shù)��。其中各項的意義分別為:

圖3-5 “Statistics”對話框
①“Regression Coefficients”回歸系數(shù)選項:
 “Estimates”輸出回歸系數(shù)和相關統(tǒng)計量。
“Estimates”輸出回歸系數(shù)和相關統(tǒng)計量。
 “Confidence interval”回歸系數(shù)的95%置信區(qū)間��。
“Confidence interval”回歸系數(shù)的95%置信區(qū)間��。
“Covariance matrix”回歸系數(shù)的方差-協(xié)方差矩陣�。
本例子選擇“Estimates”輸出回歸系數(shù)和相關統(tǒng)計量。
②“Residuals”殘差選項:
“Durbin-Watson”Durbin-Watson檢驗�。
“Casewise diagnostic”輸出滿足選擇條件的觀測量的相關信息。選擇該項�����,下面兩項處于可選狀態(tài):
 “Outliers outside standard deviations”選擇標準化殘差的絕對值大于輸入值的觀測量��;
“Outliers outside standard deviations”選擇標準化殘差的絕對值大于輸入值的觀測量��;
 “All cases”選擇所有觀測量�。
“All cases”選擇所有觀測量�。
本例子都不選。
③ 其它輸入選項
“Model fit”輸出相關系數(shù)��、相關系數(shù)平方���、調整系數(shù)���、估計標準誤、ANOVA表���。
“R squared change”輸出由于加入和剔除變量而引起的復相關系數(shù)平方的變化。
“Descriptives”輸出變量矩陣、標準差和相關系數(shù)單側顯著性水平矩陣��。
“Part and partial correlation”相關系數(shù)和偏相關系數(shù)��。
“Collinearity diagnostics”顯示單個變量和共線性分析的公差�。
本例子選擇“Model fit”項。
7)繪圖選項
在主對話框單擊“Plots”按鈕�����,將打開如圖3-6所示的對話框窗口�。該對話框用于設置要繪制的圖形的參數(shù)。圖中的“X”和“Y”框用于選擇X軸和Y軸相應的變量�����。

圖3-6“Plots”繪圖對話框窗口
左上框中各項的意義分別為:
-
“DEPENDNT”因變量�。
-
“ZPRED”標準化預測值。
-
“ZRESID”標準化殘差�。
-
“DRESID”刪除殘差。
-
“ADJPRED”調節(jié)預測值���。
-
“SRESID”學生氏化殘差�����。
-
“SDRESID”學生氏化刪除殘差�����。
“Standardized Residual Plots”設置各變量的標準化殘差圖形輸出�����。其中共包含兩個選項:
“Histogram”用直方圖顯示標準化殘差�。
“Normal probability plots”比較標準化殘差與正態(tài)殘差的分布示意圖。
“Produce all partial plot”偏殘差圖�。對每一個自變量生成其殘差對因變量殘差的散點圖。
本例子不作繪圖�,不選擇。
8) 保存分析數(shù)據(jù)的選項
在主對話框里單擊“Save”按鈕�����,將打開如圖3-7所示的對話框���。

圖3-7“Save”對話框
①“Predicted Values”預測值欄選項:
Unstandardized 非標準化預測值��。就會在當前數(shù)據(jù)文件中新添加一個以字符“PRE_”開頭命名的變量�,存放根據(jù)回
歸模型擬合的預測值��。
Standardized 標準化預測值��。
Adjusted 調整后預測值�。
S.E. of mean predictions 預測值的標準誤�����。
本例選中“Unstandardized”非標準化預測值��。
②“Distances”距離欄選項:
Mahalanobis: 距離���。
Cook’s”: Cook距離���。
Leverage values: 杠桿值。
③“Prediction Intervals”預測區(qū)間選項:
Mean: 區(qū)間的中心位置�����。
Individual: 觀測量上限和下限的預測區(qū)間��。在當前數(shù)據(jù)文件中新添加一個以字符“LICI_”開頭命名的變量�,存放
預測區(qū)間下限值�;以字符“UICI_”開頭命名的變量�����,存放預測區(qū)間上限值。
Confidence Interval:置信度�。
本例不選����。
④“Save to New File”保存為新文件:
選中“Coefficient statistics”項將回歸系數(shù)保存到指定的文件中���。本例不選�����。
⑤ “Export model information to XML file” 導出統(tǒng)計過程中的回歸模型信息到指定文件���。本例不選。
⑥“Residuals” 保存殘差選項:
“Unstandardized”非標準化殘差����。
“Standardized”標準化殘差。
“Studentized”學生氏化殘差����。
“Deleted”刪除殘差。
“Studentized deleted”學生氏化刪除殘差���。
本例不選����。
⑦“Influence Statistics” 統(tǒng)計量的影響��。
“DfBeta(s)”刪除一個特定的觀測值所引起的回歸系數(shù)的變化�。
“Standardized DfBeta(s)”標準化的DfBeta值�����。
“DiFit” 刪除一個特定的觀測值所引起的預測值的變化����。
“Standardized DiFit”標準化的DiFit值。
“Covariance ratio”刪除一個觀測值后的協(xié)方差矩隈的行列式和帶有全部觀測值的協(xié)方差矩陣的行列式的比率�����。
本例子不保存任何分析變量��,不選擇。
9)提交執(zhí)行
在主對話框里單擊“OK”����,提交執(zhí)行,結果將顯示在輸出窗口中�����。主要結果見表6-10至表6-13�����。
10) 結果分析
主要結果:

表6-10 是逐步回歸每一步進入或剔除回歸模型中的變量情況���。

表6-11 是逐步回歸每一步的回歸模型的統(tǒng)計量:R 是相關系數(shù)�;R Square
相關系數(shù)的平方���,又稱判定系數(shù)����,判定線性回歸的擬合程度:用來說明用自變量解釋因變量變異的程度(所占比例)�;Adjusted R Square
調整后的判定系數(shù);Std. Error of the Estimate 估計標準誤差。

表6-12 是逐步回歸每一步的回歸模型的方差分析��,F(xiàn)值為10.930�����,顯著性概率是0.001�����,表明回歸極顯著���。
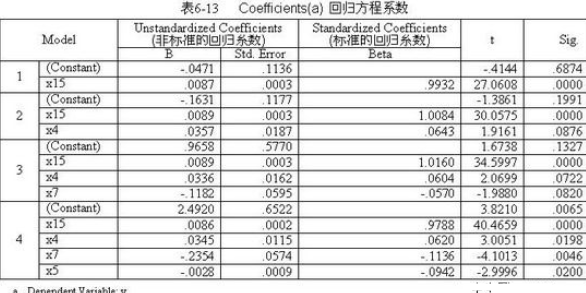
表6-13 是逐步回歸每一步的回歸方程系數(shù)表。
分析:
建立回歸模型:
根據(jù)多元回歸模型:
從6-13中看出�����,過程一共運行了四步�,最后一步以就是表中的第4步的計算結果得知:21個變量中只進入了4個變量x15、x4�、x7 和 x5。
把表6-13中“非標準化回歸系數(shù)”欄目中的“B”列數(shù)據(jù)代入多元回歸模型得到預報方程:

預測值的標準差可用剩余標準差估計:
回歸方程的顯著性檢驗:
從表6-12方差分析表第4模型中得知:F統(tǒng)計量為622.72���,系統(tǒng)自動檢驗的顯著性水平為0.0000(非常?�。?����。
F(0.00001,4,7)值為70.00�����。因此回歸方程相關非常非常顯著���。
由回歸方程式可以看出���,在陜西長武煙草蚜傳病毒病8月份的病情指數(shù)(y)與x4(5月份最低氣溫)、x15(第一次蚜遷高峰期百株煙草有翅蚜量)呈顯著正相關����,而與x5(3~5月份降水量)和x7 (3~5月份均溫)呈顯著負相關。
通過大田調查結果表明��,煙草蚜傳病毒病發(fā)生與蚜蟲的遷飛有密切的關系��。遷入煙田的有翅蚜有兩次高峰期�,呈雙峰曲線。第一高峰期出現(xiàn)在5月中旬至6月初�,此次遷飛的高峰期與大田發(fā)病率呈顯著正相關。第二高峰期在6月上旬末至6月中旬,此次遷飛高峰期與大田發(fā)病率關系不大��。5月份的最低氣溫(x4)和3~5月份均溫(x7 )通過影響傳媒介體蚜蟲的活動來影響田間發(fā)病��。而第一次蚜遷高峰期百株煙草有翅蚜量(x15)是影響煙草蚜傳病毒病病情指數(shù)(y)的重要因子�。3~5月份降水量(x5)通過影響田間蚜蟲傳病毒病發(fā)病植株的癥狀表現(xiàn)影響大田發(fā)病程度。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330