針對SAS用戶:Python數(shù)據(jù)分析庫pandas
這篇文章是Randy Betancourt的用于SAS用戶的快速入門中的一章。Randy編寫這本指南�����,讓SAS用戶熟悉Python和Python的各種科學(xué)計算工具���。
本文包括的主題:
導(dǎo)入包
Series
DataFrames
讀.csv文件
檢查
處理缺失數(shù)據(jù)
缺失數(shù)據(jù)監(jiān)測
缺失值替換
資源
pandas簡介
本章介紹pandas庫(或包)���。pandas為 Python開發(fā)者提供高性能、易用的數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)分析工具����。該包基于NumPy(發(fā)音‘numb pie’)中,一個基本的科學(xué)計算包�,提供ndarray,一個用于數(shù)組運(yùn)算的高性能對象����。我們將說明一些有用的NumPy對象來作為說明pandas的方式����。
對于數(shù)據(jù)分析任務(wù)���,我們經(jīng)常需要將不同的數(shù)據(jù)類型組合在一起����。一個例子是使用頻率和計數(shù)的字符串對分類數(shù)據(jù)進(jìn)行分組���,使用int和float作為連續(xù)值�����。此外�,我們希望能夠附加標(biāo)簽到列�、透視數(shù)據(jù)等。
我們從介紹對象Series和DataFrame開始����。可以認(rèn)為Series是一個索引�����、一維數(shù)組、類似一列值����?��?梢哉J(rèn)為DataFrames是包含行和列的二維數(shù)組索引�。好比Excel單元格按行和列位置尋址�����。
換句話說���,DataFrame看起來很像SAS數(shù)據(jù)集(或關(guān)系表)����。下表比較在SAS中發(fā)現(xiàn)的pandas組件��。

第6章���,理解索引中詳細(xì)地介紹DataFrame和Series索引�。
導(dǎo)入包
為了使用pandas對象, 或任何其它Python包的對象��,我們開始按名稱導(dǎo)入庫到命名空間。為了避免重復(fù)鍵入完整地包名�����,對NumPy使用np的標(biāo)準(zhǔn)別名�,對pandas使用pd。
Series
可以認(rèn)為Series是含標(biāo)記的一維數(shù)組�。這個結(jié)構(gòu)包括用于定位數(shù)據(jù)鍵值的標(biāo)簽索引。Series 中的數(shù)據(jù)可以是任何數(shù)據(jù)類型�。pandas數(shù)據(jù)類型的詳情見這里。在SAS例子中����,我們使用Data StepARRAYs類同于Series。
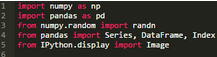
以創(chuàng)建一個含隨機(jī)值的Series開始:
注意:索引從0開始�����。大部分SAS自動變量像_n_使用1作為索引開始位置����。SAS迭代DO loop 0 to 9結(jié)合ARRAY產(chǎn)生一個數(shù)組下標(biāo)超出范圍錯誤。
下面的SAS例子����,DO循環(huán)用于迭代數(shù)組元素來定位目標(biāo)元素�。
SAS中數(shù)組主要用于迭代處理如變量����。SAS/IML更接近的模擬NumPy數(shù)組。但SAS/IML 在這些示例的范圍之外�����。
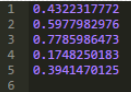
一個Series可以有一個索引標(biāo)簽列表�����。
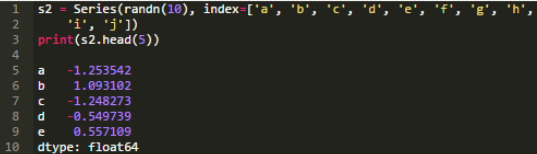
Series由整數(shù)值索引��,并且起始位置是0��。
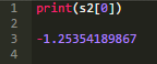
SAS示例使用一個DO循環(huán)做為索引下標(biāo)插入數(shù)組�����。
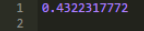
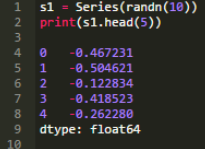
返回Series中的前3個元素��。
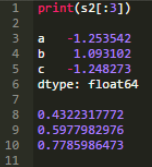
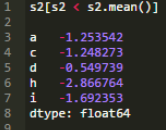
該示例有2個操作����。s2.mean()方法計算平均值,隨后一個布爾測試小于計算出的平均值����。
Series和其它有屬性的對象,它們使用點(.)操作符�����。.name是Series對象很多屬性中的一個���。
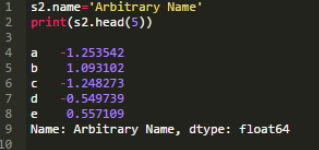
DataFrames
如前所述����,DataFrames是帶有標(biāo)簽的關(guān)系式結(jié)構(gòu)��。此外����,一個單列的DataFrame是一個Series。
像SAS一樣���,DataFrames有不同的方法來創(chuàng)建�。可以通過加載其它Python對象的值創(chuàng)建DataFrames���。數(shù)據(jù)值也可以從一系列非Python輸入資源加載�,包括.csv文件���、DBMS表�����、網(wǎng)絡(luò)API、甚至是SAS數(shù)據(jù)集(.sas7bdat)等等�����。具體細(xì)節(jié)討論見第11章—
pandas Readers��。
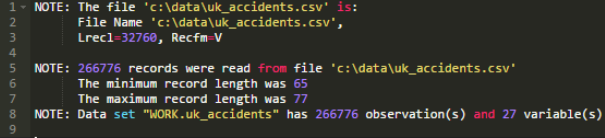
從讀取UK_Accidents.csv文件開始����。該文件包括從2015年1月1日到2015年12月31日香港的車輛事故數(shù)據(jù)。.csv文件位于這里�。
一年中的每一天都有很多報告, 其中的值大多是整數(shù)����。另一個.CSV文件在這里�,將值映射到描述性標(biāo)簽�����。
讀.csv文件
在下面的示例中使用默認(rèn)值�。pandas為許多讀者提供控制缺失值、日期解析���、跳行��、數(shù)據(jù)類型映射等參數(shù)��。這些參數(shù)類似于SAS的INFILE/INPUT處理�。
注意額外的反斜杠\來規(guī)范化Windows路徑名���。

PROC IMPORT用于讀取同一個.csv文件�。它是SAS讀.csv文件的幾個方法之一�。這里我們采用默認(rèn)值。
與SAS不同����,Python解釋器正常執(zhí)行時主要是靜默的�����。調(diào)試時�����,調(diào)用方法和函數(shù)返回有關(guān)這些對象的信息很有用�����。這有點類似于在SAS日志中使用PUT來檢查變量值����。
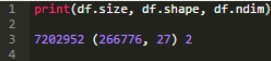
下面顯示了size�����、shape和ndim屬性(分別對應(yīng)于�����,單元格個數(shù)�����、行/列�、維數(shù))。
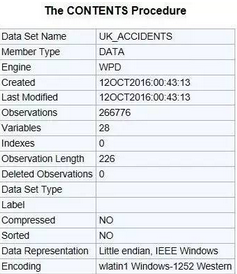
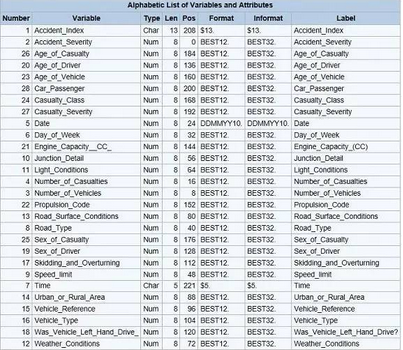
讀校驗
讀取一個文件后��,常常想了解它的內(nèi)容和結(jié)構(gòu)�����。.info()方法返回DataFrame的屬性描述�。
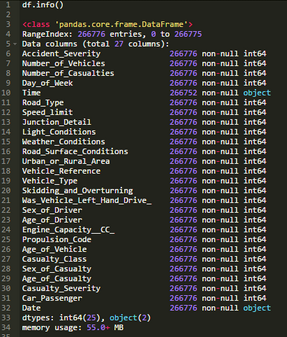
在SASPROC CONTENTS的輸出中,通常會發(fā)現(xiàn)同樣的信息����。
檢查
pandas有用于檢查數(shù)據(jù)值的方法。DataFrame的.head()方法默認(rèn)顯示前5行���。.tail()方法默認(rèn)顯示最后5行�。行計數(shù)值可以是任意整數(shù)值����,如:
SAS使用FIRSTOBS和OBS選項按照程序來確定輸入觀察數(shù)。SAS代碼打印uk_accidents數(shù)據(jù)集的最后20個觀察數(shù):
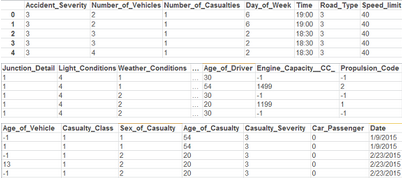
5 rows × 27 columns
OBS=n在SAS中確定用于輸入的觀察數(shù)�。
PROC PRINT的輸出在此處不顯示。
下面的單元格顯示的是范圍按列的輸出����。列列表類似于PROCPRINT中的VAR���。注意此語法的雙方括號。這個例子展示了按列標(biāo)簽切片���。按行切片也可以��。方括號[]是切片操作符���。這里解釋細(xì)節(jié)。
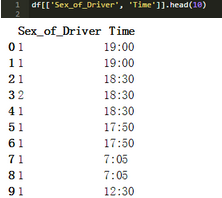
注意DataFrame的默認(rèn)索引(從0增加到9)���。這類似于SAS中的自動變量n�����。隨后����,我們使用DataFram中的其它列作為索引說明這����。
下面是SAS程序打印一個帶Sec_of_Driver和Time變量的數(shù)據(jù)集的前10個觀察數(shù)。
PROC PRINT的輸出在此處不顯示��。
處理缺失數(shù)據(jù)
在分析數(shù)據(jù)之前�����,一項常見的任務(wù)是處理缺失數(shù)據(jù)��。Pandas使用兩種設(shè)計來表示缺失數(shù)據(jù)����,NaN(非數(shù)值)和PythonNone對象。
下面的單元格使用PythonNone對象代表數(shù)組中的缺失值���。相應(yīng)地�,Python推斷出數(shù)組的數(shù)據(jù)類型是對象�����??上У氖牵瑢σ粋€聚合函數(shù)使用PythonNone對象引發(fā)一個異常����。
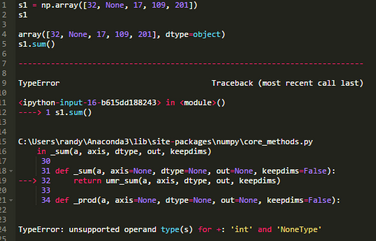
為了減輕上述錯誤的發(fā)生�����,在下面的數(shù)組例子中使用np.nan(缺失數(shù)據(jù)指示符)�。也要注意Python如何為數(shù)組選擇浮點數(shù)(或向上轉(zhuǎn)型)��。
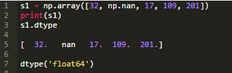
并不是所有使用NaN的算數(shù)運(yùn)算的結(jié)果是NaN��。
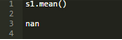
對比上面單元格中的Python程序�,使用SAS計算數(shù)組元素的平均值如下。SAS排除缺失值��,并且利用剩余數(shù)組元素來計算平均值�����。
缺失值的識別
回到DataFrame���,我們需要分析所有列的缺失值�。Pandas提供四種檢測和替換缺失值的方法���。它們是:
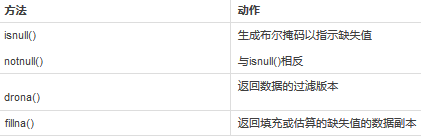
下面我們將詳細(xì)地研究每個方法���。
解決缺失數(shù)據(jù)分析的典型SAS編程方法是,編寫一個程序使用計數(shù)器變量遍歷所有列�,并使用IF/THEN測試缺失值。
這可以沿著下面的輸出單元格中的示例行�。df.columns返回DataFrame中的列名稱序列。
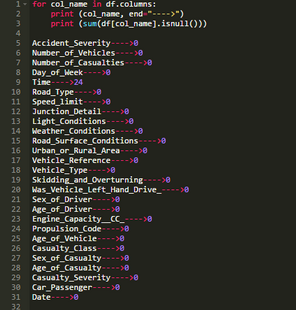
雖然這給出了期望的結(jié)果�����,但是有更好的方法����。
另外,如果你發(fā)現(xiàn)自己想使用迭代處理來解決一個pandas操作(或Python)����,停下來,花一點時間做研究����。可能方法或函數(shù)已經(jīng)存在�!
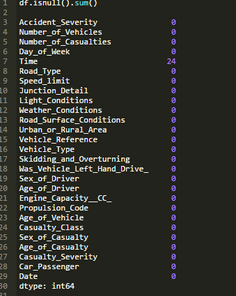
案例如下所示。它將.sum()屬性鏈接到.isnull()屬性來返回DataFrame中列的缺失值的計數(shù)�����。
.isnull()方法對缺失值返回True。通過將.sum()方法鏈接到.isnull()方法����,它會生成每個列的缺失值的計數(shù)。
為了識別缺失值��,下面的SAS示例使用PROC格式來填充缺失和非缺失值�����。缺失值對于數(shù)值默認(rèn)用(.)表示�����,而字符串變量用空白(‘ ‘)表示���。因此��,兩種類型都需要用戶定義的格式�。
PROC FREQ與自變量_CHARACTER_和_NUMERIC_一起使用�����,為每個變量類型生成頻率列表。
由于為每個變量產(chǎn)生單獨的輸出�����,因此僅顯示SAS輸出的一部分����。與上面的Pythonfor循環(huán)示例一樣����,變量time是唯一有缺失值的變量。
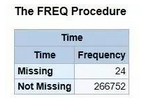
用于檢測缺失值的另一種方法是通過對鏈接屬性.isnull().any()使用axis=1參數(shù)逐列進(jìn)行搜索�。
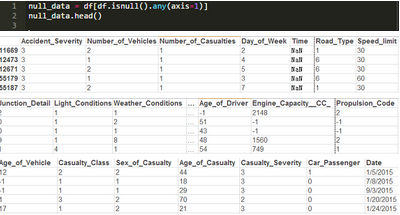
5 rows × 27 columns
缺失值替換
下面的代碼用于并排呈現(xiàn)多個對象。它來自Jake VanderPlas的使用數(shù)據(jù)的基本工具���。它顯示對象更改“前”和“后”的效果����。
為了說明.fillna()方法���,請考慮用以下內(nèi)容來創(chuàng)建DataFrame�。
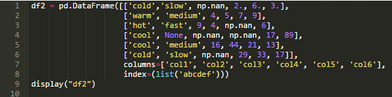
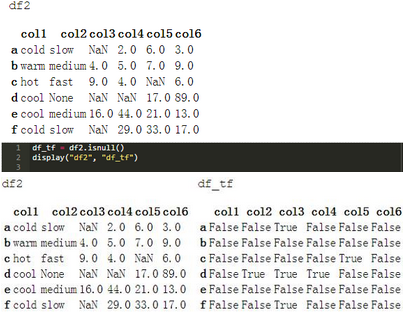
默認(rèn)情況下�����,.dropna()方法刪除其中找到任何空值的整個行或列。
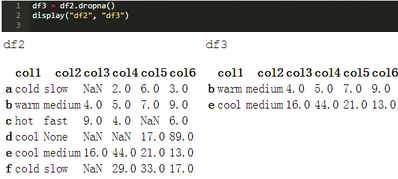
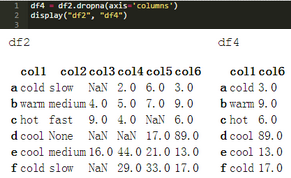
.dropna()方法也適用于列軸����。axis = 1和axis = "columns"是等價的。
顯然�,這會丟棄大量的“好”數(shù)據(jù)。thresh參數(shù)允許您指定要為行或列保留的最小非空值�����。在這種情況下�����,行"d"被刪除��,因為它只包含3個非空值����。
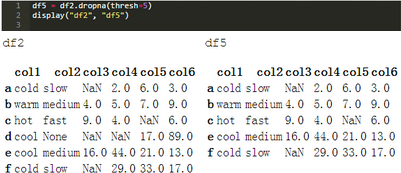
可以插入或替換缺失值,而不是刪除行和列���。.fillna()方法返回替換空值的Series或DataFrame���。下面的示例將所有NaN替換為零����。
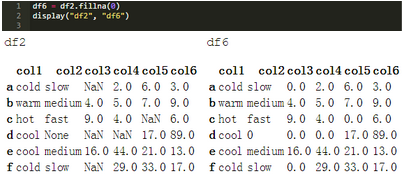
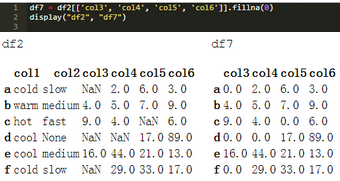
正如你可以從上面的單元格中的示例看到的��,.fillna()函數(shù)應(yīng)用于所有的DataFrame單元格����。我們可能不希望將df["col2"]中的缺失值值替換為零����,因為它們是字符串。該方法應(yīng)用于使用.loc方法的目標(biāo)列列表�����。第05章–了解索引中討論了.loc方法的詳細(xì)信息���。
基于df["col6"]的平均值的填補(bǔ)方法如下所示����。.fillna()方法查找���,然后用此計算值替換所有出現(xiàn)的NaN����。
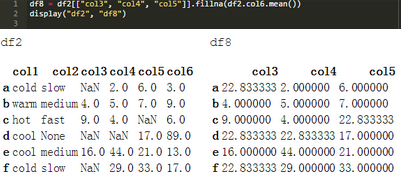
相應(yīng)的SAS程序如下所示。PROC SQL SELECT INTO子句將變量col6的計算平均值存儲到宏變量&col6_mean中�����。這之后是一個數(shù)據(jù)步驟�����,為col3 - col5迭代數(shù)組x �,并用&col6_mean替換缺失值。
SAS/Stat具有用于使用這里描述的一系列方法來估計缺失值的PROC MI�����。PROC MI在這些示例的范圍之外���。
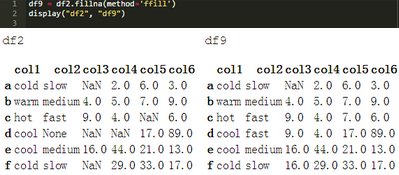
.fillna(method="ffill")是一種“前向”填充方法�����。NaN被上面的“下”列替換為相鄰單元格�。下面的單元格將上面創(chuàng)建的DataFramedf2與使用“前向”填充方法創(chuàng)建的數(shù)據(jù)框架df9進(jìn)行對比。
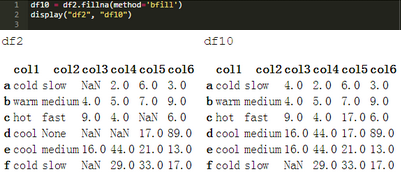
類似地�����,.fillna(bfill)是一種“后向”填充方法����。NaN被上面的“上”列替換為相鄰單元格。下面的單元格將上面創(chuàng)建的DataFramedf2與使用“后向”填充方法創(chuàng)建的數(shù)據(jù)框架df10進(jìn)行對比����。
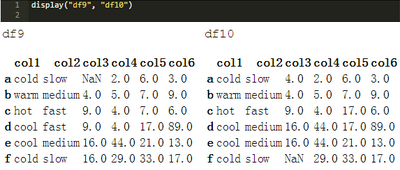
下面我們對比使用‘前向’填充方法創(chuàng)建的DataFramedf9�����,和使用‘后向’填充方法創(chuàng)建的DataFramedf10����。
在刪除缺失行之前,計算在事故DataFrame中丟失的記錄部分�,創(chuàng)建于上面的df。

DataFrame中的24個記錄將被刪除�。記錄刪除部分為0.009%
除了錯誤的情況,.dropna()是函數(shù)是靜默的�����。我們可以在應(yīng)用該方法后驗證DataFrame的shape。
資源
來源于pandas.pydata.org的10 分鐘了解pandas���。
教程, 并且在這個鏈接下面是pandas Cookbook的鏈接��,來自pandas.pydata.org的pandas 0.19.1文檔�����。
pandas Python數(shù)據(jù)分析庫的主頁����。
Python數(shù)據(jù)科學(xué)手冊�����,使用數(shù)據(jù)工作的基本工具�����,作者Jake VanderPlas���。
pandas:Python中的數(shù)據(jù)處理和分析�,來自2013 BYU MCL Bootcamp文檔。
Greg Reda的介紹pandas數(shù)據(jù)結(jié)構(gòu)����。這是一個三部分系列使用Movie Lens數(shù)據(jù)集很好地說明pandas。
備忘單:Mark Graph的pandas DataFrame對象��,并且位于愛達(dá)荷大學(xué)的網(wǎng)站����。
使用pandas 0.19.1文檔處理缺失數(shù)據(jù)。
讀這本書
這篇文章是Randy Betancourt的Python SAS用戶快速入門指南的摘錄����。查看完整的章節(jié)列表。
關(guān)于Randy
Randy
Betancourt曾在SAS研究所和國際分析研究所擔(dān)任過多個客戶和執(zhí)行官角色���。公司執(zhí)行面臨角色度過他的職業(yè)生涯。從技術(shù)架構(gòu)師開始���,最近擔(dān)任顧問�,他建議企業(yè)領(lǐng)導(dǎo)如何培養(yǎng)和成本有效地管理他們的分析資源組合���。最近�����,這些討論和努力集中于現(xiàn)代化戰(zhàn)略����,鑒于行業(yè)創(chuàng)新的增長。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330