當評分卡建模的時候用的邏輯回歸�,最好是將連續(xù)變量變成分段變量�,即字符變量�����。把字符變量����,觀測的種類達到10種以上的時候�,建議分下類���,最好每個變量(無論數(shù)值還是字符)控制在3-7段之間�,這是我的建議哈��,要是你領導叫你分8段����,你就千萬就要聽領導的。
然后����,我來說下,我這里的最優(yōu)分段怎么就是最優(yōu)的呢?
01字符變量
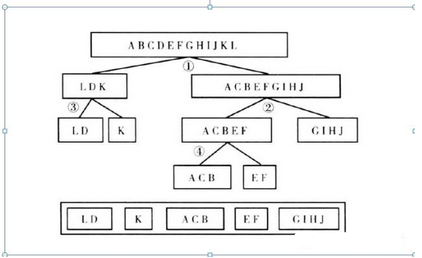
先發(fā)這張圖給粘上來����,然后我就用簡單粗暴的語言解釋最優(yōu)是怎么最優(yōu)的。就是先把每種情況都列出來�,剛開始每一種情況都是一類,然后你還要輸入因變量�,所以1中就是找出最優(yōu)的二元分割方法,把原來的一大群先分兩大類����,然后第2的套路還是跟1一樣的�����,知道分成5份���。你問我二元分割最好的指標是什么,你還記得我之前寫的代碼之前都有帶“基尼系數(shù)”�,“iv值”嗎,就是按照這個指標去分的啦�����。然后這里還要說一點就是����,你要是一個變量,總共就1�����、2�、3�、4種情況,然后還要最優(yōu)分段分五份這不是為難嘛���。假設你覺得4種情況的分層沒有特點�����,想分的有特點一點����,那就可以試著分成3份,2份��。分出來的結(jié)果對比一下iv值����,要是3份的iv值比4份還高或者一樣的話,那就是3份還要好些��,因為我們都知道變量分段越多iv值越高���。
02數(shù)值變量
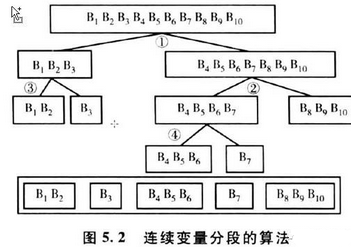
這是數(shù)值變量最優(yōu)分段的圖��,其實套路跟字符變量很像����,但是數(shù)值變量就多了順序,所以還是有點跟字符有點不像��。首先連續(xù)變量被分為大量等距的小分段���,譬如區(qū)間是100的變量���,然后就分成50段,那么就是1-2就是一組�����。那按照跟剛才的字符變量一樣的分法類似����,就是先分兩份,只是對于字符變量多了順序���。但是這里這里要注意一點就是�,你本來1����、2、3代表的是類的話����,在這里就需要把他轉(zhuǎn)成字符,就不要是數(shù)值丟進去分段���。同樣的���,要是你不知道分幾段的時候,試幾次�����,看下iv值����,取一個你覺得最好的iv值。
[賣萌蔬菜動圖特殊用途]
我是分割線
好的�����,兩種變量的分類也就這樣了啦���,好像也沒寫多少字哦���,那就貼代碼吧��。
options mlogic;
options nomlogic;
%macro gvalue(binds,m_value);
proc sql noprint;
%local i j R N;/*生成局部變量*/
select max(bin)into:R from &binds;/**/
select sum(total) into: N from &binds;/**/
%do i=1 %to &R;
%local N_&i._1 N_&i._2 N_&i._s N_s_1 N_s_2;
Select sum(Ni1) into :N_&i._1 from &BinDS where Bin =&i ;
Select sum(Ni2) into :N_&i._2 from &BinDS where Bin =&i ;
Select sum(Total) into :N_&i._s from &BinDS where Bin =&i ;
Select sum(Ni1) into :N_s_1 from &BinDS ;
Select sum(Ni2) into :N_s_2 from &BinDS ;
%end;
quit;
/* 檢查缺失值 */
%do i=1 %to &R;
%do j=1 %to 2;
%local N_&i._&j;
%if (&&N_&i._&j=.) or (&&N_&i._&j=0) %then %do ;
%let &M_Value=.;
%return;
%end;
%end;
%end;
%do i=1 %to &r;
%local E_&i;
%let E_&i=0;
%do j=1 %to 2;
%let E_&i = %sysevalf(&&E_&i - (&&N_&i._&j/&&N_&i._s)*%sysfunc(log(%sysevalf(&&N_&i._&j/&&N_&i._s))) );
%end;
%let E_&i = %sysevalf(&&E_&i/%sysfunc(log(2)));
%end;
%local E;
%let E=0;
%do j=1 %to 2;
%let E=%sysevalf(&E - (&&N_s_&j/&N)*%sysfunc(log(&&N_s_&j/&N)) );
%end;
%let E=%sysevalf(&E / %sysfunc(log(2)));
%local Er;
%let Er=0;
%do i=1 %to &r;
%let Er=%sysevalf(&Er+ &&N_&i._s * &&E_&i / &N);
%end;
%let &M_Value=%sysevalf(1 - &Er/&E);
%return;
%mend;
%macro CalcMerit(BinDS, ix, M_Value);
%local n_11 n_12 n_21 n_22 n_1s n_2s n_s1 n_s2;
proc sql noprint;
select sum(Ni1) into :n_11 from &BinDS where i<=&ix;
select sum(Ni1) into :n_21 from &BinDS where i> &ix;
select sum(Ni2) into : n_12 from &BinDS where i<=&ix ;
select sum(Ni2) into : n_22 from &binDS where i> &ix ;
select sum(total) into :n_1s from &BinDS where i<=&ix ;
select sum(total) into :n_2s from &BinDS where i> &ix ;
select sum(Ni1) into :n_s1 from &BinDS;
select sum(Ni2) into :n_s2 from &BinDS;
quit;
%local N E1 E2 E Er;
%let N=%eval(&n_1s+&n_2s);
%let E1=%sysevalf(-( (&n_11/&n_1s)*%sysfunc(log(%sysevalf(&n_11/&n_1s))) +
(&n_12/&n_1s)*%sysfunc(log(%sysevalf(&n_12/&n_1s)))) / %sysfunc(log(2)) ) ;
%let E2=%sysevalf(-( (&n_21/&n_2s)*%sysfunc(log(%sysevalf(&n_21/&n_2s))) +
(&n_22/&n_2s)*%sysfunc(log(%sysevalf(&n_22/&n_2s)))) / %sysfunc(log(2)) ) ;
%let E =%sysevalf(-( (&n_s1/&n )*%sysfunc(log(%sysevalf(&n_s1/&n ))) +
(&n_s2/&n )*%sysfunc(log(%sysevalf(&n_s2/&n )))) / %sysfunc(log(2)) ) ;
%let Er=%sysevalf(1-(&n_1s*&E1+&n_2s*&E2)/(&N*&E));
%let &M_value=&Er;
%return;
%mend;
%macro BestSplit(BinDs, BinNo);
%local mb i value BestValue BestI;
proc sql noprint;
select count(*) into: mb from &BinDs where Bin=&BinNo;
quit;
%let BestValue=0;
%let BestI=1;
%do i=1 %to %eval(&mb-1);
%let value=;
%CalcMerit(&BinDS, &i, Value);
%if %sysevalf(&BestValue<&value) %then %do;
%let BestValue=&Value;
%let BestI=&i;
%end;
%end;
data &BinDS;
set &BinDS;
if i<=&BestI then Split=1;
else Split=0;
drop i;
run;
proc sort data=&BinDS;
by Split;
run;
data &BinDS;
retain i 0;
set &BinDs;
by Split;
if first.split then i=1;
else i=i+1;
run;
%mend;
%macro CandSplits(BinDS, NewBins);
proc sort data=&BinDS;
by Bin PDV1;
run;
%local Bmax i value;
proc sql noprint;
select max(bin) into: Bmax from &BinDS;
%do i=1 %to &Bmax;
%local m&i;
create table Temp_BinC&i as select * from &BinDS where Bin=&i;
select count(*) into:m&i from Temp_BinC&i;
%end;
create table temp_allVals (BinToSplit num, DatasetName char(80), Value num);
run;quit;
%do i=1 %to &Bmax;
%if (&&m&i>1) %then %do;
%BestSplit(Temp_BinC&i, &i);
data temp_trysplit&i;
set temp_binC&i;
if split=1 then Bin=%eval(&Bmax+1);
run;
Data temp_main&i;
set &BinDS;
if Bin=&i then delete;
run;
Data Temp_main&i;
set temp_main&i temp_trysplit&i;
run;
%let value=;
%GValue(temp_main&i, Value);
proc sql noprint;
insert into temp_AllVals values(&i, "temp_main&i", &Value);
run;quit;
%end;
%end;
proc sort data=temp_allVals;
by descending value;
run;
data _null_;
set temp_AllVals(obs=1);
call symput("bin", compress(BinToSplit));
run;
Data &NewBins;
set Temp_main&Bin;
drop split;
run;
/* Clean the workspace */
/*proc datasets nodetails nolist library=work;*/
/* delete temp_AllVals %do i=1 %to &Bmax; Temp_BinC&i temp_TrySplit&i temp_Main&i %end; ; */
/*run;*/
/*quit;*/
%mend;
%macro BinContVar(DSin, IVVar, DVVar, MMax, Acc, DSVarMap);
%local VarMax VarMin;
proc sql noprint;
select min(&IVVar), max(&IVVar) into :VarMin, :VarMax from &DSin;
quit;
%local Mbins i MinBinSize;
%let Mbins=%sysfunc(int(%sysevalf(1.0/&Acc)));
%let MinBinSize=%sysevalf((&VarMax-&VarMin)/&Mbins);
%do i=1 %to %eval(&Mbins);
%local Lower_&i Upper_&i;
%let Upper_&i = %sysevalf(&VarMin + &i * &MinBinSize);
%let Lower_&i = %sysevalf(&VarMin + (&i-1)*&MinBinSize);
%end;
%let Lower_1 = %sysevalf(&VarMin-0.0001);
%let Upper_&Mbins=%sysevalf(&VarMax+0.0001);
data Temp_DS;
set &DSin;
%do i=1 %to %eval(&Mbins-1);
if &IVVar>=&&Lower_&i and &IVVar < &&Upper_&i Then Bin=&i;
%end;
if &IVVar>=&&Lower_&Mbins and &IVVar <= &&Upper_&MBins Then Bin=&MBins;
keep &IVVar &DVVar Bin;
run;
data temp_blimits;
%do i=1 %to %Eval(&Mbins-1);
Bin_LowerLimit=&&Lower_&i;
Bin_UpperLimit=&&Upper_&i;
Bin=&i;
output;
%end;
Bin_LowerLimit=&&Lower_&Mbins;
Bin_UpperLimit=&&Upper_&Mbins;
Bin=&Mbins;
output;
run;
proc sort data=temp_blimits;
by Bin;
run;
proc freq data=Temp_DS noprint;
table Bin*&DVvar /out=Temp_cross;
table Bin /out=Temp_binTot;
run;
proc sort data=temp_cross;
by Bin;
run;
proc sort data= temp_BinTot;
by Bin;
run;
data temp_cont;
merge Temp_cross(rename=count=Ni2 ) temp_BinTot(rename=Count=total) temp_BLimits ;
by Bin;
Ni1=total-Ni2;
PDV1=bin;
label Ni2= total=;
if Ni1=0 then output;
else if &DVVar=1 then output;
drop percent &DVVar;
run;
data temp_contold;
set temp_cont;
run;
proc sql noprint;
%local mx;
%do i=1 %to &Mbins;
select count(*) into : mx from Temp_cont where Bin=&i;
%if (&mx>0) %then %do;
select Ni1, Ni2, total, bin_lowerlimit, bin_upperlimit into :Ni1,:Ni2,:total, :bin_lower, :bin_upper
from temp_cont where Bin=&i;
%if (&i=&Mbins) %then %do;
select max(bin) into :i1 from temp_cont where Bin<&Mbins;
%end;
%else %do;
select min(bin) into :i1 from temp_cont where Bin>&i;
%end;
%if (&Ni1=0) or (&Ni2=0) or (&total=0) %then %do;
update temp_cont set Ni1=Ni1+&Ni1 ,
Ni2=Ni2+&Ni2 ,
total=total+&Total
where bin=&i1;
%if (&i<&Mbins) %then %do;
update temp_cont set Bin_lowerlimit = &Bin_lower
where bin=&i1;
%end;
%else %do;
update temp_cont set Bin_upperlimit = &Bin_upper
where bin=&i1;
%end;
delete from temp_cont where bin=&i;
%end;
%end;
%end;
quit;
proc sort data=temp_cont;
by pdv1;
run;
%local m;
data temp_cont;
set temp_cont;
i=_N_;
Var=bin;
Bin=1;
call symput("m", compress(_N_));
run;
%local Nbins ;
%let Nbins=1;
%DO %WHILE (&Nbins <&MMax);
%CandSplits(temp_cont, Temp_Splits);
Data Temp_Cont;
set Temp_Splits;
run;
%let NBins=%eval(&NBins+1);
%end;
data temp_Map1 ;
set temp_cont(Rename=Var=OldBin);
drop Ni2 PDV1 Ni1 i ;
run;
proc sort data=temp_Map1;
by Bin OldBin ;
run;
data temp_Map2;
retain LL 0 UL 0 BinTotal 0;
set temp_Map1;
by Bin OldBin;
Bintotal=BinTotal+Total;
if first.bin then do;
LL=Bin_LowerLimit;
BinTotal=Total;
End;
if last.bin then do;
UL=Bin_UpperLimit;
output;
end;
drop Bin_lowerLimit Bin_upperLimit Bin OldBin total;
run;
proc sort data=temp_map2;
by LL;
run;
data &DSVarMap;
set temp_map2;
Bin=_N_;
run;
/* Clean the workspace */
/*proc datasets nodetails library=work nolist;*/
/* delete temp_bintot temp_blimits temp_cont temp_contold temp_cross temp_ds temp_map1*/
/* temp_map2 temp_splits;*/
/*run; quit;*/
%mend;
%macro ApplyMap2(DSin, VarX, NewVarX, DSVarMap, DSout);
%local m i;
proc sql noprint;
select count(Bin) into:m from &DSVarMap;
quit;
%do i=1 %to &m;
%local Upper_&i Lower_&i Bin_&i;
%end;
data _null_;
set &DSVarMap;
call symput ("Upper_"||left(_N_), UL);
call symput ("Lower_"||left(_N_), LL);
call symput ("Bin_"||left(_N_), Bin);
run;
Data &DSout;
set &DSin;
IF &VarX < &Upper_1 Then &NewVarX=&Bin_1;
%do i=2 %to %eval(&m-1);
if &VarX >= &&Lower_&i and &VarX < &&Upper_&i Then &NewVarX=&&Bin_&i;
%end;
if &VarX >= &&Lower_&i Then &NewVarX=&&Bin_&i;
DROP &VarX.;
Run;
%mend;
%macro var_namelist(data=,coltype=,tarvar=,dsor=);
%let lib=%upcase(%scan(&data.,1,'.'));
%let dname=%upcase(%scan(&data.,2,'.'));
%global var_list var_num;
proc sql ;
create table &dsor. as
select name
from sashelp.VCOLUMN
where left(libname)="&lib." and left(memname)="&dname." and type="&coltype." and lowcase(name)^=lowcase("&tarvar.") and lowcase(name)^="appl_id";
quit;
%mend;
%macro pub_best(data=,tarvar=,MMax=,ACC=,DSout=);
proc datasets lib=work;
delete _all_;
run;
%var_namelist(data=&data.,coltype=num,tarvar=&tarvar.,dsor=aa);
data _null_;
set aa;
call symput (compress("var"||left(_n_)),compress(name));
call symput(compress("n"),compress(_n_));
run;
%do i=1 %to &n.;
%put &&Var&i.;
%BinContVar(DSin=&data., IVVar=&&Var&i., DVVar=&tarvar.,MMax=&MMax., ACC=&Acc., DSVarMap=AA_1);
%ApplyMap2(DSin=&data., VarX=&&Var&i., NewVarX=N_&&Var&i., DSVarMap=AA_1, DSout=&DSout.);
%END;
%MEND;
[分割線]
這代碼有點長���,你就直接復制到sas里面看吧。
data=填入原始的數(shù)據(jù)集
tarvar=因變量;
MMax=分幾組;
Acc=剛才是分幾組����,譬如你是1-100,那么你設定的是0.01�����,那就是分成100組���,建議acc設定在0.01-0.05之間;
DSout=輸出數(shù)據(jù)集���。
代碼是我調(diào)試好的,可以直接用�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330