SPSS分析技術(shù):多重線性回歸模型�;極端值與多重共線性的識(shí)別與處理
如果擬合質(zhì)量不好���,可能存在的問題主要有以下兩個(gè)方面:
極端值(強(qiáng)點(diǎn))的影響��。我們都知道����,在線性回歸分析中���,自變量回歸系數(shù)的確定主要采用最小二乘法,而最小二乘法的原理就是兼顧每個(gè)數(shù)據(jù)點(diǎn)的影響�����,使得最后的離差平方和最小��。最小二乘法就好比生活中的老好人�,誰都不得罪,與某些小團(tuán)體內(nèi)的人人或者特別有個(gè)性的離群者都保持相同程度的聯(lián)系��,這時(shí)小團(tuán)體的人很可能因?yàn)榭吹狡渑c離群者的關(guān)系而刻意疏遠(yuǎn)他�����。用最小二乘法擬合得到的多重線性回歸模型同樣如此,會(huì)極大的受到極端值的影響而失去客觀和準(zhǔn)確性����。
自變量間的多重共線性問題。多重共線性指自變量間存在線性相關(guān)關(guān)系���,也就是說自變量間可以互相建立線性回歸方程�����。若自變量間存在多重共線性關(guān)系�,那么得到的多重線性回歸模型也是不準(zhǔn)確和不可用的���。
案例分析
本篇采用的案例依舊是上篇文章:SPSS分析技術(shù):回歸模型的自變量篩選方法�����;全軍出擊OR穩(wěn)扎穩(wěn)打步步為營的內(nèi)容����。下面我們還是以上篇文章的數(shù)據(jù)來判斷和解決極端值和多重共線性問題����。文章的數(shù)據(jù)都已經(jīng)上傳到QQ群中��,大家可以前往QQ群的群文件中下載�,跟隨學(xué)習(xí)�。案例的研究背景是固體垃圾的產(chǎn)生量與城市不同用途土地面積之間的多重線性回歸模型的建立。
極端值檢查過程和結(jié)果
極端值可以用兩種指標(biāo)來檢查:殘差和極端值統(tǒng)計(jì)量�����。SPSS軟件利用殘差進(jìn)行極端值檢查需要在【分析】-【回歸】-【線性】-【統(tǒng)計(jì)】中選擇下圖殘差區(qū)域的個(gè)案診斷��,系統(tǒng)默認(rèn)的離群值為3個(gè)標(biāo)準(zhǔn)差(注意�����,這里將殘差進(jìn)行標(biāo)準(zhǔn)化處理)�。
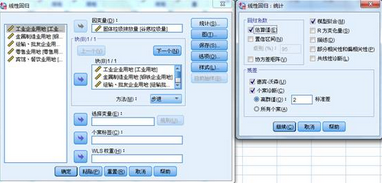
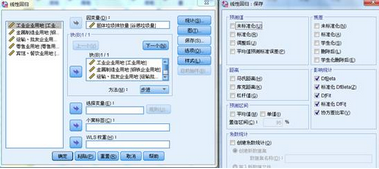
除此之外��,還可以選擇【保存】按鈕�����,在影響統(tǒng)計(jì)中�,將DfBeta�����、標(biāo)準(zhǔn)化DfBeta��、DfFit��、標(biāo)準(zhǔn)化DfFit和協(xié)方差比例選中��。以上這些指標(biāo)的分析邏輯都是比較刪除某個(gè)記錄前后�,偏回歸系數(shù)或殘差的差異情況����,以此來判斷極端值(離群值),值越大���,極端值的可能性越大�。為了便于比較�����,其中兩個(gè)標(biāo)準(zhǔn)差指標(biāo)如果大于2���,可以認(rèn)為是極端值����。
案例的分析結(jié)果
個(gè)案診斷結(jié)果,可以發(fā)現(xiàn)�,第8個(gè)數(shù)據(jù)點(diǎn)的標(biāo)準(zhǔn)化殘差值達(dá)到2.105,大于2�����,可以認(rèn)為該數(shù)據(jù)點(diǎn)是極端值(離群值)�����。結(jié)合第8個(gè)數(shù)據(jù)點(diǎn)的標(biāo)準(zhǔn)化DfFit值1.42�����,雖然小于2�����,但是大于1��。綜合兩個(gè)結(jié)果�,可以認(rèn)為該數(shù)據(jù)點(diǎn)是極端值�����。

對(duì)于極端值,我們不能盲目的直接刪除了事���。應(yīng)該找到該值�,考慮是否是錄入錯(cuò)誤或者是某些特殊情況導(dǎo)致該值的離群�����,如果是以上兩種情況導(dǎo)致的��,那么可以修改和刪除該數(shù)據(jù)點(diǎn)����。如果以上兩種情況都不符合,那么需要考慮是否采用加權(quán)最小二乘法進(jìn)行多重線性回歸�����,或者增加樣本量���,看是否是樣本量過小導(dǎo)致該值類似的情況出現(xiàn)較少�,使得該值成為極端值。
多重共線性的檢查與處理
自變量的多重共線性會(huì)導(dǎo)致得到的多重回歸模型存在錯(cuò)誤��,不能顯示自變量與因變量之間真實(shí)的相互關(guān)系情況���。如果自變量間存在多重共線性關(guān)系��,那么在用SPSS進(jìn)行多重線性回歸分析時(shí)�����,可能會(huì)出現(xiàn)以下這些違反邏輯的情況:
整個(gè)回歸模型的假設(shè)檢驗(yàn)是通過的���,但是個(gè)別自變量的檢驗(yàn)卻無法通過。
專業(yè)上認(rèn)為應(yīng)該有統(tǒng)計(jì)學(xué)意義的自變量檢驗(yàn)結(jié)果卻是沒有統(tǒng)計(jì)學(xué)意義���。
有些自變量的回歸系數(shù)大小或符號(hào)與實(shí)際情況相違背�,難以解釋����。
增加或刪除一個(gè)自變量,有些自變量的回歸系數(shù)出現(xiàn)大的變動(dòng)�。
如果多重回歸模型出現(xiàn)以上情況�,那么就應(yīng)該考慮自變量存在多重共線性問題。SPSS對(duì)于多重共線性的判斷指標(biāo)有以下幾種:容忍度(Tolerance)、方差膨脹因子(VIF�����,Variance Inflation Factor)�����、特征根(Eigenvalue)�、條件指數(shù)(Condition Index)和變異構(gòu)成(Variance Proportion)。
容忍度(Tolerance)等于1減去以該自變量為因變量���,其它自變量依舊為自變量的線性回歸模型的決定系數(shù)的剩余值(1-R方)�����。顯然�����,容忍度越小����,共線性越嚴(yán)重����。一般的認(rèn)識(shí)是�����,當(dāng)容忍度小于0.1時(shí)��,存在嚴(yán)重的多重共線性����。
方差膨脹系數(shù)(VIF)等于容忍度的倒數(shù)����。一般情況下,VIF的值不應(yīng)該大于5��,放寬到容忍度的水平�����,就是不應(yīng)該大于10����。
特征根(Eigenvalue)對(duì)模型中常數(shù)項(xiàng)及所有自變量計(jì)算主成分,如果自變量間存在較強(qiáng)的線性相關(guān)關(guān)系�����,則前面的幾個(gè)主成分?jǐn)?shù)值較大��,而后面的幾個(gè)主成分較小�,甚至接近于0。
條件指數(shù)(Condition Index)等于最大的主成分與當(dāng)前主成分的比值的算數(shù)平方根���。第一個(gè)主成分被定義為1��。如果有幾個(gè)條件指數(shù)較大��,那么就提示存在多重共線性關(guān)系��。
變異構(gòu)成(Variance Proportion)是指回歸模型中常數(shù)項(xiàng)和自變量項(xiàng)被主成分解釋的比例��。如果某個(gè)主成分對(duì)兩個(gè)或多個(gè)自變量的解釋的比例都較大��,說明這幾個(gè)自變量間存在一定的共線性����。
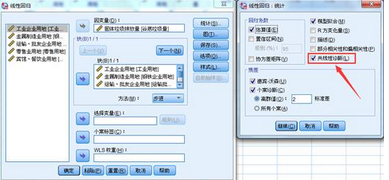
在SPSS中選中【統(tǒng)計(jì)】按鈕中的共線性診斷����,就會(huì)輸出上面的結(jié)果�����。
我們依舊使用上面的例題為例���,介紹各種共線性診斷指標(biāo)的作用。我們首先看容忍度和方差膨脹系數(shù)(VIF)的結(jié)果���?����?梢钥吹皆谌可傻乃膫€(gè)線性回歸模型中�����,只有最后一個(gè)模型的賓館��、餐飲用地和零售業(yè)用地這兩個(gè)自變量的容差小于0.2�����,VIF值大于7��,說明這兩個(gè)自變量間存在共線性關(guān)系��。
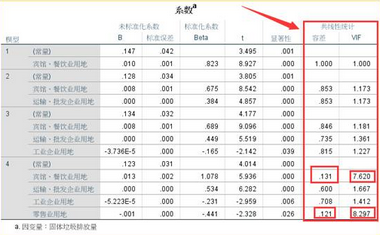
再結(jié)合特征根����、條件指數(shù)和變異構(gòu)成這三個(gè)指標(biāo)。前面三個(gè)模型的特征根差距不大����,第四個(gè)模型的前四個(gè)特征根與最后一個(gè)存在較大的差異�,說明該模型可能存在共線性情況。再看條件指標(biāo)���,第四個(gè)模型的最后一個(gè)公因子的條件指標(biāo)達(dá)到8.642���,同樣說明了這個(gè)可能性。最后看變異構(gòu)成����,最后一個(gè)公因子中,賓館餐飲用地與零售業(yè)用地的公因子方差解釋比例都達(dá)到0.96���,說明它們之間存在共線性�。
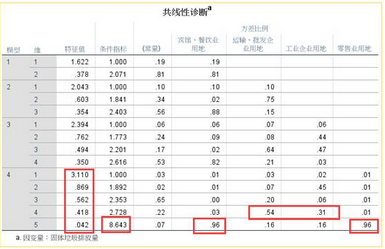
結(jié)合以上五個(gè)因子���,我們可以認(rèn)為賓館餐飲用地與零售業(yè)用地這兩個(gè)自變量間存在共線性情況�����。需要做進(jìn)一步處理�。
除了以上這五個(gè)指標(biāo)以外,還可以使用前面提高過的散點(diǎn)圖舉證和簡單線性相關(guān)系數(shù)矩陣來判斷它們之間是否存在多重共線性關(guān)系��。如果發(fā)現(xiàn)自變量間存在多重共線性時(shí)�,可以采用以下方法解決:
逐步回歸:逐步回歸能夠在一定程度上對(duì)多重共線性的自變量組合進(jìn)行篩選,將對(duì)因變量變異解釋較大的自變量保留����,而將解釋較小的自變量刪除。遺憾的是�����,對(duì)于共線性較為嚴(yán)重時(shí)��,逐步回歸的變量自動(dòng)篩選方法就顯得無力了���。
嶺回歸:嶺回歸是一種專門用于共線性數(shù)據(jù)分析的有偏估計(jì)回歸方法��,它實(shí)際上是一種改良的最下二乘法��,通過放棄最小二乘法的無偏性�����,以損失部分信息���,降低精度為代價(jià)來尋求效果稍差但是回歸系數(shù)更符合實(shí)際的回歸方程�����。
主成分回歸:主成分回歸能夠?qū)Υ嬖诙嘀囟嘀毓簿€性的自變量提取主成分,提取出來的主成分之間是完全互相獨(dú)立的����,然后再用提取出來的主成分與其它的自變量一起進(jìn)行多重線性回歸。
路徑分析:如果自變量之間的聯(lián)系規(guī)律比較清楚���,比如很多實(shí)證研究中的變量情況�。那么可以考慮使用路徑分析模型�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330