SPSS詳細(xì)操作:碰見有序分類資料��,怎么辦
經(jīng)常聽到有小伙伴剛學(xué)了武林秘籍之卡方檢驗(yàn)����,只要碰到分類資料就一通亂打�����,雖說有時(shí)候能贏幾場�,但是也有被打的鼻青臉腫的��,還自言自語的說�,招數(shù)沒毛病呀?���。渴聦?shí)上毛病大了去了��,與人過招�����,知己知彼����,見招拆招,方能克敵制勝�����!所以我們先來捋捋分類資料的分析��。
常見的分類資料可以分成四類:
老大����,雙向無序分類�����,特點(diǎn)是分組變量和結(jié)局變量均為無序多分類(或二分類),例如比較漢族�、回族和蒙古族ABO血型分布有無差別;
老二�����,單向有序分類���,分組變量或結(jié)局變量為有序變量�����,例如比較35-�、45-����、55-、65-歲組血脂異常的患病率有無差別�����,或者比較A和B兩種藥物對(duì)于疾病預(yù)后 (痊愈、顯著改善���、進(jìn)步���、無效)有無差異;
老三���,雙向有序?qū)傩圆煌姆诸?����,這里既強(qiáng)調(diào)行變量和列變量均為有序分類資料�����,并且屬性不相同(行列變量不一致)����,例如觀察年齡對(duì)疾病預(yù)后有無影響(35-�����、45-、55-���、65-歲組 vs 痊愈��、顯著改善��、進(jìn)步�、無效)����;
老四�,雙向有序?qū)傩韵嗤姆诸悾凶兞亢土凶兞烤鶠橛行蚍诸愘Y料��,并且屬性相同(行列變量一致)����,例如A和B兩種方法對(duì)某種免疫物質(zhì)的檢出情況(--/-/+/++)。
(注:上文提到的“屬性”����,我們后期會(huì)專門推送一篇文章來講解~)
針對(duì)雙向無序分類和雙向有序?qū)傩韵嗤姆诸愘Y料的分析方法,前面幾期有詳細(xì)介紹����,還沒看過的小伙伴戳SPSS詳細(xì)操作:多個(gè)獨(dú)立樣本列聯(lián)表的卡方檢驗(yàn)/SPSS詳細(xì)操作:一致性檢驗(yàn)和配對(duì)卡方檢驗(yàn)�。這次我們一塊兒搞定單向有序分類和雙向有序?qū)傩圆煌姆诸愘Y料的SPSS操作����。
一、單向有序分類
血脂異常的患病率隨著年齡增加而增加嗎��?
某研究小白在利用某項(xiàng)調(diào)查數(shù)據(jù)分析時(shí)����,想研究一下年齡與血脂異常之間的關(guān)系,想起了之前學(xué)過的多個(gè)獨(dú)立樣本的卡方檢驗(yàn)SPSS操作�����,于是照貓畫虎����,分析了一下手里的數(shù)據(jù)。
Analyze→
Descriptive Statistics→ Crosstabs: Row(Age);
Column(Dyslipidemia)→Statistics: Chi-square; Continue→ Cells:
Percentages(勾選Row); Continue→ OK
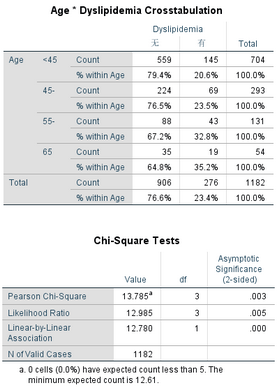
看到分析結(jié)果�,尤其是P=0.003,小白立刻眼睛冒光�,馬上超級(jí)自信地下了結(jié)論:經(jīng)獨(dú)立樣本卡方檢驗(yàn),血脂異常的患病率隨著年齡增加而增加(P=0.003)�,但是剛說完心里又犯嘀咕�,想起之前學(xué)的獨(dú)立樣本卡方檢驗(yàn)�,好像這里只能說明不同年齡組之間血脂異常患病率有統(tǒng)計(jì)學(xué)差異���。嗯�����,沒錯(cuò)����!這里如果只看Pearson
Chi-Square的結(jié)果��,會(huì)忽略年齡分組為有序變量這個(gè)信息點(diǎn)�����,損失了信息��,所以這里更好的是看Linear-by-Linear Association的結(jié)果��。
提到趨勢性卡方檢驗(yàn)�,想必大家并不陌生�����,主要用來明確分類變量之間的線性趨勢,比如這里的“血脂異常的患病率隨著年齡增加而增加”�����。趨勢性卡方檢驗(yàn)最常用的方法是Cochran-Armitage trend test�����,很遺憾SPSS并沒有提供這種方法����,而是另一種方法Linear-by-Linear Association,兩個(gè)結(jié)果相近��,所以大家也可以放心使用����。
聽到這里,研究小白馬上修改了結(jié)論:經(jīng)趨勢性卡方檢驗(yàn)�,血脂異常的患病率隨著年齡增加而增加(P<0.001)。
拓展一下���,相信不少小伙伴會(huì)想起Spearman秩相關(guān)�����,感覺這里好像也可以用Spearman秩相關(guān)來分析年齡組和血脂異常的關(guān)系����。事實(shí)上,也是可以滴�����!但是趨勢性卡方檢驗(yàn)和Spearman秩相關(guān)有些不同�。
Analyze →Correlate →Bivariate →Variables: Age, Dyslipidemia; Correlation Coefficients: Spearman(勾選)→OK
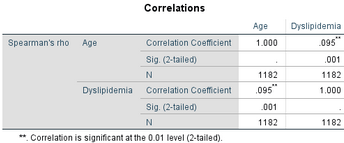
首先,嚴(yán)格地講��,做趨勢性卡方檢驗(yàn)時(shí)����,需要對(duì)分組變量和結(jié)局變量進(jìn)行評(píng)分賦值�����,連續(xù)變量取組中值為等級(jí)評(píng)分�����;如果是等級(jí)資料,給以順序性的評(píng)分���,如1��、2���、3……;分類資料��,陽性或患病等為1�����,陰性或不患病等為0����。這里就涉及到一個(gè)問題,對(duì)于Spearman秩相關(guān)是基于變量秩次進(jìn)行相關(guān)分析的���,比如說上面的例子��,如果去掉55-歲組��,趨勢性卡方檢驗(yàn)中變量評(píng)分為1����、2、4��,而Spearman秩相關(guān)是1�����、2����、3,這就反映兩種分析方法的利用信息能力不一樣����。
其次,兩種方法的檢驗(yàn)效能不同�����,趨勢性卡方檢驗(yàn)屬于參數(shù)檢驗(yàn)�,當(dāng)我們假定存在線性趨勢時(shí),檢驗(yàn)效能更高�;而Spearman秩相關(guān)計(jì)算變量秩次�,損失了信息�,相同條件下����,檢驗(yàn)效能較低,比如這里Spearman秩相關(guān)P=0.001�,趨勢性卡方檢驗(yàn)P<0.001。
最后�����,兩者得到的結(jié)論也有所不同���,趨勢性卡方檢驗(yàn)可以直接得出“血脂異常的患病率隨著年齡增加而增加”����,而Spearman秩相關(guān)因?yàn)槭褂米兞恐却畏治?�,所以?yán)格地講�����,它反映的是兩個(gè)分類變量秩次有相關(guān)����,因?yàn)闆]有考慮變量的具體取值��,更多是一種相對(duì)穩(wěn)定的相關(guān)關(guān)系��。
二����、雙向有序?qū)傩圆煌姆诸?
干活兒越重骨質(zhì)退行越重���?
有一項(xiàng)旨在探討骨質(zhì)退行性變是否與勞動(dòng)強(qiáng)度有關(guān)��,觀察150名研究對(duì)象��。勞動(dòng)強(qiáng)度分為輕���、中、重度���,骨質(zhì)退行性變?yōu)?�、3���、4度�,兩個(gè)變量都屬于等級(jí)變量,但是屬性不同����。
對(duì)于雙向有序?qū)傩圆煌馁Y料���,有的小伙伴就說啦����,可以用Spearman秩相關(guān)嘛�,有些小伙伴就要很疑惑,為什么不可以用卡方檢驗(yàn)?zāi)兀?
這里和大家一塊兒掰扯掰扯�����。對(duì)于等級(jí)資料相關(guān)分析��,Spearman秩相關(guān)也是可以計(jì)算滴����,但問題關(guān)鍵是,在做秩相關(guān)時(shí)�,需要對(duì)原始數(shù)據(jù)進(jìn)行編秩次,因?yàn)槭堑燃?jí)資料��,所以會(huì)產(chǎn)生大量秩次相等的平均秩次,進(jìn)而低估了變量之間的關(guān)聯(lián)系數(shù)���。
如果是獨(dú)立樣本的卡方檢驗(yàn)?zāi)?���?那就錯(cuò)的比較離譜一些�!卡方檢驗(yàn)的核心是列聯(lián)表中每一個(gè)格子中的理論頻數(shù)和實(shí)際觀測頻數(shù)偏離程度,行和列的位置是不重要的(比如你可以把行列互換��,或者把第一行和第二行互換)�,結(jié)果都是一樣的。問題就來了��,這樣就損失了變量“有序”——這個(gè)非常關(guān)鍵的信息點(diǎn)����,比如這里例子,我們想知道是不是勞動(dòng)強(qiáng)度越重�,骨質(zhì)退行越重。
有小伙伴要著急了��,這也不行����,那也不行���,到底要咋整?給大家?guī)碇亓考?jí)武器——Goodman-Kruskal Gamma方法(簡稱Gamma法)���。Gamma法主要用于有序分類資料的關(guān)聯(lián)性分析���,并且計(jì)算Gamma系數(shù)(類似于Spearman秩相關(guān)rs)���。
Gamma系數(shù)取值在-1到1之間��,G=0表示兩個(gè)變量不相關(guān)�,G>0表示兩個(gè)變量正相關(guān)�,G<0表示兩個(gè)變量負(fù)相關(guān);G的絕對(duì)值越接近1����,表示兩個(gè)變量的關(guān)聯(lián)強(qiáng)度越大,越接近0����,關(guān)聯(lián)程度越小。
下面一起看看SPSS怎么進(jìn)行Gamma����。
Analyze →Descriptive Statistics →Crosstabs: Row(勞動(dòng)強(qiáng)度); Column(骨退變)→Statistics: Gamma; Continue →OK
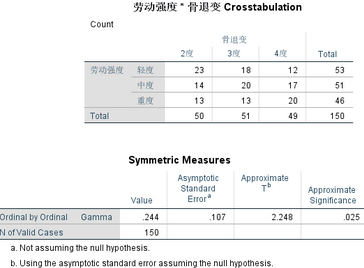
上面的結(jié)果顯示:G=0.244��,P=0.025<0.05�����,勞動(dòng)強(qiáng)度與骨退變之間互相關(guān)聯(lián)��,即隨著勞動(dòng)強(qiáng)度增加��,骨質(zhì)退行越重���,關(guān)聯(lián)系數(shù)為0.244。
再看看Spearman秩相關(guān)的結(jié)果���。
Analyze →Correlate →Bivariate →Variables: 勞動(dòng)強(qiáng)度�����,骨退變; Correlation Coefficients: Spearman(勾選)→OK
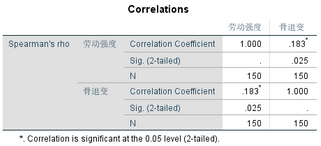
可以看到Spearman秩相關(guān)系數(shù)rs=0.183�,小于G(0.244)����,低估了變量之間的關(guān)聯(lián)強(qiáng)度�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330