用SPSS進(jìn)行單因素方差分析和多重比較
SPSS——單因素方差分析
單因素方差分析
單因素方差分析
也稱作一維方差分析。它檢驗(yàn)由單一因素影響的一個(gè)(或幾個(gè)相互獨(dú)立的)因變量由因素各水平分組的均值之間的差異是否具有統(tǒng)計(jì)意義。還可以對(duì)該因素的若干水
平分組中哪一組與其他各組均值間具有顯著性差異進(jìn)行分析�,即進(jìn)行均值的多重比較��。One-Way
ANOVA過(guò)程要求因變量屬于正態(tài)分布總體�。如果因變量的分布明顯的是非正態(tài),不能使用該過(guò)程��,而應(yīng)該使用非參數(shù)分析過(guò)程�����。如果幾個(gè)因變量之間彼此不獨(dú)立��,應(yīng)該用Repeated
Measure過(guò)程�。 [例子]
調(diào)查不同水稻品種百叢中稻縱卷葉螟幼蟲(chóng)的數(shù)量,數(shù)據(jù)如表1-1所示�����。
表1-1 不同水稻品種百叢中稻縱卷葉螟幼蟲(chóng)數(shù)

圖1-2 單因素方差分析窗口
3)設(shè)置分析變量
因變量: 選擇一個(gè)或多個(gè)因子變量進(jìn)入“Dependent List”框中����。本例選擇“幼蟲(chóng)”��。
因素變量: 選擇一個(gè)因素變量進(jìn)入“Factor”框中��。本例選擇“品種”�����。
4)設(shè)置多項(xiàng)式比較
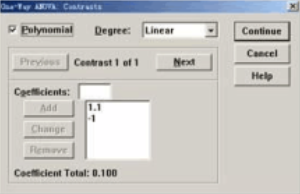
單擊“Contrasts”按鈕,將打開(kāi)如圖1-3所示的對(duì)話框�。該對(duì)話框用于設(shè)置均值的多項(xiàng)式比較。
圖1-3 “Contrasts”對(duì)話框
定義多項(xiàng)式的步驟為:
均值的多項(xiàng)式比較是包括兩個(gè)或更多個(gè)均值的比較����。例如圖1-3中顯示的是要求計(jì)算“1.1×mean1-1×mean2”的值,檢驗(yàn)的假設(shè)H0:第一組均 值的1.1倍與第二組的均值相等�����。單因素方差分析的“0ne-Way ANOVA”過(guò)程允許進(jìn)行高
達(dá)5次的均值多項(xiàng)式比較��。多項(xiàng)式的系數(shù)需要由讀者自己根據(jù)研究的需要輸入��。具體的操作步驟如下:
① 選中“Polynomial”復(fù)選項(xiàng)����,該操作激活其右面的“Degree”參數(shù)框。
②
單擊Degree參數(shù)框右面的向下箭頭展開(kāi)階次菜單���,可以選擇“Linear”線性�、“Quadratic”二次����、“Cubic”三次�、“4th”四次���、“5th”五次多項(xiàng)式����。
③
為多項(xiàng)式指定各組均值的系數(shù)����。方法是在“Coefficients”框中輸入一個(gè)系數(shù),單擊Add按鈕�����,“Coefficients”框中的系數(shù)進(jìn)入下面
的方框中�。依次輸入各組均值的系數(shù),在方形顯示框中形成—列數(shù)值���。因素變量分為幾組�,輸入幾個(gè)系數(shù)�,多出的無(wú)意義����。如果多項(xiàng)式中只包括第一組與第四組的均
值的系數(shù)��,必須把第二個(gè)��、第三個(gè)系數(shù)輸入為0值���。如果只包括第一組與第二組的均值,則只需要輸入前兩個(gè)系數(shù)����,第三、四個(gè)系數(shù)可以不輸入��。
可以同時(shí)建立多個(gè)多項(xiàng)式�����。一個(gè)多項(xiàng)式的一組系數(shù)輸入結(jié)束����,激話“Next”按鈕,單擊該按鈕后“Coefficients”框中清空�����,準(zhǔn)備接受下一組系數(shù)數(shù)據(jù)。
如果認(rèn)為輸入的幾組系數(shù)中有錯(cuò)誤�,可以分別單擊“Previous”或“Next”按鈕前后翻找出錯(cuò)的一組數(shù)據(jù)。單擊出錯(cuò)的系數(shù)����,該系數(shù)顯示在編輯框中,
可以在此進(jìn)行修改���,修改后單擊“Change”按鈕在系數(shù)顯示框中出現(xiàn)正確的系數(shù)值�����。當(dāng)在系數(shù)顯示框中選中一個(gè)系數(shù)時(shí)�,同時(shí)激話“Remove”按鈕��,單
擊該按鈕將選中的系數(shù)清除���。
④單擊“Previous”或“Next”按鈕顯示輸入的各組系數(shù)檢查無(wú)誤后���,按“Continue”按鈕確認(rèn)輸入的系數(shù)并返回到主對(duì)話框。要取消剛剛的輸入�,單擊“Cancel”按鈕;需要查看系統(tǒng)的幫助信息��,單擊“Help”按鈕���。
本例子不做多項(xiàng)式比較的選擇,選擇缺省值�。
5)設(shè)置多重比較
在主對(duì)話框里單擊“Post
Hoc”按鈕��,將打開(kāi)如圖5-4所示的多重比較對(duì)話框����。該對(duì)話框用于設(shè)置多重比較和配對(duì)比較。方差分析一旦確定各組均值間存在差異顯著����,多重比較檢測(cè)可以
求出均值相等的組;配對(duì)比較可找出和其它組均值有差異的組���,并輸出顯著性水平為0.95的均值比較矩陣���,在矩陣中用星號(hào)表示有差異的組。
圖1-4 “Post Hoc Multiple Comparisons”對(duì)話框
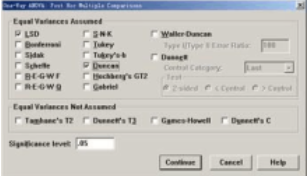
(1)多重比較的選擇項(xiàng):
①方差具有齊次性時(shí)(Equal Variances Assumed)��,該矩形框中有如下方法供選擇:
LSD (Least-significant difference) 最小顯著差數(shù)法��,用t檢驗(yàn)完成各組均值間的配對(duì)比較��。對(duì)多重比較誤差率不進(jìn)行調(diào)整。
Bonferroni (LSDMOD) 用t檢驗(yàn)完成各組間均值的配對(duì)比較�,但通過(guò)設(shè)置每個(gè)檢驗(yàn)的誤差率來(lái)控制整個(gè)誤差率。
Sidak 計(jì)算t統(tǒng)計(jì)量進(jìn)行多重配對(duì)比較��?���?梢哉{(diào)整顯著性水平,比Bofferroni方法的界限要小���。
Scheffe 對(duì)所有可能的組合進(jìn)行同步進(jìn)入的配對(duì)比較����。這些選擇項(xiàng)可以同時(shí)選擇若干個(gè)����。以便比較各種均值比較方法的結(jié)果。
R-E-G-WF (Ryan-Einot-Gabriel-Welsch F) 用F檢驗(yàn)進(jìn)行多重比較檢驗(yàn)�����。 R-E-G-WQ (Ryan-Einot-Gabriel-Welsch range test) 正態(tài)分布范圍進(jìn)行多重配對(duì)比較�����。
S-N-K
(Student-Newmnan-Keuls) 用Student
Range分布進(jìn)行所有各組均值間的配對(duì)比較。如果各組樣本含量相等或者選擇了“Harmonic average of all
groups”即用所有各組樣本含量的調(diào)和平均數(shù)進(jìn)行樣本量估計(jì)時(shí)還用逐步過(guò)程進(jìn)行齊次子集(差異較小的子集)的均值配對(duì)比較��。在該比較過(guò)程中����,各組均值從大到小按順序排列����,最先比較最末端的差異。
Tukey
(Tukey's�����,honestly signicant difference)
用Student-Range統(tǒng)計(jì)量進(jìn)行所有組間均值的配對(duì)比較��,用所有配對(duì)比較誤差率作為實(shí)驗(yàn)誤差率�����。 Tukey's-b 用“stndent
Range”分布進(jìn)行組間均值的配對(duì)比較�����。其精確值為前兩種檢驗(yàn)相應(yīng)值的平均值��。
Duncan (Duncan's multiple range test) 新復(fù)極差法(SSR),指定一系列的“Range”值��,逐步進(jìn)行計(jì)算比較得出結(jié)論���。
Hochberg's GT2 用正態(tài)最大系數(shù)進(jìn)行多重比較�����。
Gabriel 用正態(tài)標(biāo)準(zhǔn)系數(shù)進(jìn)行配對(duì)比較���,在單元數(shù)較大時(shí),這種方法較自由�����。
Waller-Dunca 用t統(tǒng)計(jì)量進(jìn)行多重比較檢驗(yàn),使用貝葉斯逼近���。
Dunnett 指定此選擇項(xiàng)����,進(jìn)行各組與對(duì)照組的均值比較����。默認(rèn)的對(duì)照組是最后一組�����。選擇了該項(xiàng)就激活下面的“Control Category”參數(shù)框���。展開(kāi)下拉列表,可以重新選擇對(duì)照組�。
“Test”框中列出了三種區(qū)間分別為:
?
“2-sides” 雙邊檢驗(yàn);
?
? “Conbo1”“右邊檢驗(yàn)��。 ②方差不具有齊次性時(shí)(Equal Varance not assumed)�����,檢驗(yàn)各均數(shù)間是否有差異的方祛有四種可供選擇:
Tamhane's T2, t檢驗(yàn)進(jìn)行配對(duì)比較����。
Dunnett's T3,采用基于學(xué)生氏最大模的成對(duì)比較法�����。
Games-Howell�����,Games-Howell比較,該方法較靈活���。
Dunnett's C�,采用基于學(xué)生氏極值的成對(duì)比較法���。
③ Significance 選擇項(xiàng)�����,各種檢驗(yàn)的顯著性概率臨界值�����,默認(rèn)值為0.05���,可由用戶重新設(shè)定。
本例選擇“LSD”和“Duncan”比較����,檢驗(yàn)的顯著性概率臨界值0.05。
6) 設(shè)置輸出統(tǒng)計(jì)量
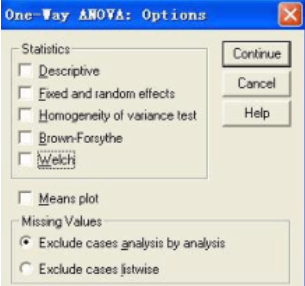
單擊“Options”按鈕��,打開(kāi)“Options”對(duì)話框�,如圖1-5所示���。選擇要求輸出的統(tǒng)計(jì)量。并按要求的方式顯示這些統(tǒng)計(jì)量��。在該對(duì)話框中還可以選擇對(duì)缺失值的處理要求��。各組選擇項(xiàng)的含義如下:
圖1-5輸出統(tǒng)計(jì)量的設(shè)置
“Statistics”欄中選擇輸出統(tǒng)計(jì)量:
Descriptive���,要求輸出描述統(tǒng)計(jì)量�。選擇此項(xiàng)輸出觀測(cè)量數(shù)目���、均值、標(biāo)準(zhǔn)差�����、標(biāo)準(zhǔn)誤��、最小值�、最大值、各組中每個(gè)因變量的95%置信區(qū)間����。 Fixed and random effects, 固定和隨機(jī)描述統(tǒng)計(jì)量
Homogeneity-of-variance�����,要求進(jìn)行方差齊次性檢驗(yàn)�,并輸出檢驗(yàn)結(jié)果����。用“Levene lest ”檢驗(yàn),即計(jì)算每個(gè)觀測(cè)量與其組均值之差����,然后對(duì)這些差值進(jìn)行一維方差分析。
Brown-Forsythe 布朗檢驗(yàn)
Welch,韋爾奇檢驗(yàn)
Means plot�����,即均數(shù)分布圖����,根據(jù)各組均數(shù)描繪出因變量的分布情況。 “Missing Values”欄中�����,選擇缺失值處理方法。
Exclude cases analysis by analysis選項(xiàng)��,被選擇參與分析的變量含缺失值的觀測(cè)量�,從分析中剔除。
Exclude cases listwise選項(xiàng)���,對(duì)含有缺失值的觀測(cè)量����,從所有分析中剔除����。
以上選擇項(xiàng)選擇完成后,按“Continue”按鈕確認(rèn)選擇并返回上一級(jí)對(duì)話框�����;單擊“Cancel”按鈕作廢本次選擇�����;單擊“Help”按鈕����,顯示有關(guān)的幫助信息。 本例子選擇要求輸出描述統(tǒng)計(jì)量和進(jìn)行方差齊次性檢驗(yàn)�,缺失值處理方法選系統(tǒng)缺省設(shè)置。
6)提交執(zhí)行
設(shè)置完成后�����,在單因素方差分析窗口框中點(diǎn)擊“OK”按鈕��,SPSS就會(huì)根據(jù)設(shè)置進(jìn)行運(yùn)算���,并將結(jié)算結(jié)果輸出到SPSS結(jié)果輸出窗口中����。
7) 結(jié)果與分析
輸出結(jié)果:
表5-2描述統(tǒng)計(jì)量�,給出了水稻品種分組的樣本含量N、平均數(shù)Mean���、標(biāo)準(zhǔn)差Std.Deviation���、標(biāo)準(zhǔn)誤Std.Error、95%的置信區(qū)間�、最小值和最大值。
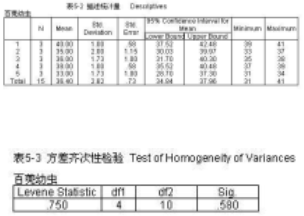
表5-3為方差齊次性檢驗(yàn)結(jié)果���,從顯著性慨率看��,p>0.05����,說(shuō)明各組的方差在a=0.05水平上沒(méi)有顯著性差異,即方差具有齊次性���。這個(gè)結(jié)論在選擇多重比較方法時(shí)作為一個(gè)條件����。
表5-4方差分析表:第1欄是方差來(lái)源���,包括組間變差“Between
Groups”����;組內(nèi)變差“Within Groups”和總變差“Total”��。第2欄是離差平方和“Sum of
Squares”��,組間離差平方和87.600�,組內(nèi)離差平方和為24.000��,總離差平方和為111.600,是組間離差平方和與組內(nèi)離差平方和相加之
和�����。第3欄是自由度df�,組間自由度為4,組內(nèi)自由度為10����;總自由度為14。第4欄是均方“Mean
Square”�,是第2欄與第3欄之比;組間均方為21.900���,組內(nèi)均方為2.400��。第5欄是F值9.125(組間均方與組內(nèi)均方之比)��。第6欄:F
值對(duì)應(yīng)的概率值��,針對(duì)假設(shè)H0:組間均值無(wú)顯著性差異(即5種品種蟲(chóng)數(shù)的平均值無(wú)顯著性差異)����。

計(jì)算的F值9.125����,對(duì)應(yīng)的概率值為0.002�。
表5-5
LSD法進(jìn)行多重比較表���,從表5-4結(jié)論已知該例子的方差具有其次性��,因此LSD方法適用���。第1欄的第1列“[i]品種”為比較基準(zhǔn)品種,第2列“[j]
品種”是比較品種�。第2欄是比較基準(zhǔn)品種平均數(shù)減去比較品種平均數(shù)的差值(Mean
Difference),均值之間具有0.05水平(可圖5-4對(duì)話框里設(shè)置)上有顯著性差異��,在平均數(shù)差值上用“*”號(hào)表明�。第3欄是差值的標(biāo)準(zhǔn)誤。第
4欄是
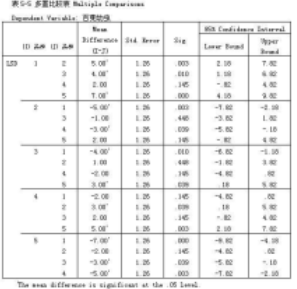
差值檢驗(yàn)的顯著性水平�。第5欄是差值的95%置信范圍的下限和上限。
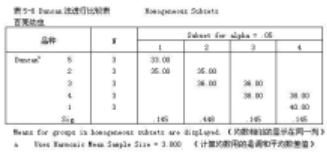
表5-6 是多重比較的Duncan法進(jìn)行比較的結(jié)果����。第1欄為品種,按均數(shù)由小到大排列�。第2欄列出計(jì)算均數(shù)用的樣本數(shù)。第3欄列出了在顯著水平0.05上的比較結(jié)果�,表的最后一行是均數(shù)方差齊次性檢驗(yàn)慨率水平����,p>0.05說(shuō)明各組方差具有齊次性��。
多重比較比較表顯著性差異差異的判讀:在
同一列的平均數(shù)表示沒(méi)有顯著性差異���,反之則具有顯著性的差異。例如�����,品種3橫向看���,平均數(shù)顯示在第3列“2”小列�,與它同列顯示的有品種2的平均數(shù)�,說(shuō)明
與品種2差異不顯著(0.05水平),再往右看����,平均數(shù)顯示在第3列“3”小列,與它同列顯示的有品種4的平均數(shù)�����,說(shuō)明與品種4差異不顯著(0.05水
平)。則品種3與品種5和品種1具有顯著性的差異(0.05水平)���。
品種3和品種4都顯示有平均數(shù)值�����。
結(jié)果分析:
根據(jù)方差分析表輸出的p值為0.002可以看出��,無(wú)論臨界值取0.05�����,還是取0.01����,p值均小于臨界值����。因此否定Ho假設(shè),水稻品種對(duì)稻縱卷葉螟幼蟲(chóng)抗
蟲(chóng)性有顯著性意義���,結(jié)論是稻縱卷葉螟幼蟲(chóng)數(shù)量的在不同品種間有明顯的不同���。根據(jù)該結(jié)論選擇抗稻縱卷葉螟幼蟲(chóng)水稻品種�����,犯錯(cuò)誤的概率幾乎為0.008�����。
只有在方差分析中F檢驗(yàn)存在差異顯著性時(shí),才有比較的統(tǒng)計(jì)意義�。
LSD法多重比較表明:
品種1與品種2、品種3和品種5之間存在顯著性差異�;
品種2與品種1和品種4之間存在顯著性差異;
品種3與品種1和品種5之間存在顯著性差異����;
品種4與品種2和品種5之間存在顯著性差異;
品種5與品種1����、品種3和品種4之間存在顯著性差異。
Duncan法多重比較表明:
品種5與品種3�����、品種4和品種1之間存在顯著性差異�����。 品種2與品種4和品種1之間存在顯著性差異; 品種3與品種5和品種1之間存在顯著性差異���;
品種4與品種5和品種2之間存在顯著性差異�;
品種1與品種5��、品種2和品種3之間存在顯著性差異�;
兩種方法比較結(jié)果一致。
推薦學(xué)習(xí)書(shū)籍
《CDA一級(jí)教材》適合CDA一級(jí)考生備考�����,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我�。完整電子版已上線CDA網(wǎng)校,累計(jì)已有10萬(wàn)+在讀~

免費(fèi)加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330