7. 相關(guān)性分析
前面的假設(shè)檢驗(yàn)���、方差分析基本上都是圍繞差異性分析�����,不論是單個(gè)總體還是兩個(gè)總體及以上���,總之都是屬于研究“區(qū)別”�����,從本節(jié)開始��,我們關(guān)注“聯(lián)系”�,變量之間的關(guān)系分為 函數(shù)關(guān)系和相關(guān)關(guān)系���。 本節(jié)這里重點(diǎn)探討的是不同類型變量之間的相關(guān)性��,千萬記住一點(diǎn)相關(guān)性不代表因果性���。除表中列出的常用方法外,還有Tetrachoric�、相關(guān)系數(shù)等。
| 變量類型 |
變量類型 |
相關(guān)系數(shù)計(jì)算方法 |
示例 |
| 連續(xù)型變量 |
連續(xù)型變量 |
Pearson(正態(tài))/Spearman(非正態(tài)) |
商品曝光量和購(gòu)買轉(zhuǎn)化率 |
| 二分類變量(無序) |
連續(xù)型變量 |
Point-biserial |
性別和疾病指數(shù) |
| 無序分類變量 |
連續(xù)型變量 |
方差分析 |
不同教育水平的考試成績(jī) |
| 有序分類變量 |
連續(xù)型變量 |
連續(xù)指標(biāo)離散化后當(dāng)做有序分類 |
商品評(píng)分與購(gòu)買轉(zhuǎn)化率 |
| 二分類變量 |
二分類變量 |
數(shù)學(xué)公式: 檢驗(yàn) 聯(lián)合 Cramer's V |
性別和是否吸煙 |
| 二分類變量(有序) |
連續(xù)型變量 |
Biserial |
樂器練習(xí)時(shí)間與考級(jí)是否通過 |
| 無序分類變量 |
無序分類變量 |
數(shù)學(xué)公式: 檢驗(yàn) / Fisher檢驗(yàn) |
手機(jī)品牌和年齡段 |
| 有序分類變量 |
無序分類變量 |
數(shù)學(xué)公式: 檢驗(yàn) |
滿意度和手機(jī)品牌 |
| 有序分類變量 |
有序分類變量 |
Spearman /Kendall Tau相關(guān)系數(shù) |
用戶等級(jí)和活躍程度等級(jí) |
Pearson
Pearson相關(guān)系數(shù)度量了兩個(gè)連續(xù)變量之間的線性相關(guān)程度�;
import random
import numpy as np
import pandas as pd
np.random.seed(10)
df = pd.DataFrame({'商品曝光量':[1233,1333,1330,1323,1323,1142,1231,1312,1233,1123],
'購(gòu)買轉(zhuǎn)化率':[0.033,0.034,0.035,0.033,0.034,0.029,0.032,0.034,0.033,0.031]})
df
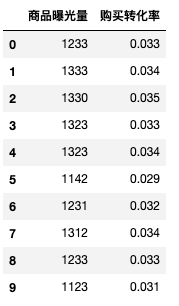
pd.Series.corr(df['商品曝光量'], df['購(gòu)買轉(zhuǎn)化率'],method = 'pearson')
import scipy.stats as stats
X = df['商品曝光量']
Y = df['購(gòu)買轉(zhuǎn)化率']
corr, p_value = stats.pearsonr(X, Y)
print("Pearson相關(guān)系數(shù):", corr)
print("p值:", p_value)
Spearman等級(jí)相關(guān)系數(shù)可以衡量非線性關(guān)系變量間的相關(guān)系數(shù),是一種非參數(shù)的統(tǒng)計(jì)方法�,可以用于定序變量或不滿足正態(tài)分布假設(shè)的等間隔數(shù)據(jù)�;
import random
import numpy as np
import pandas as pd
np.random.seed(10)
df = pd.DataFrame({'品牌知名度排位':[9,4,3,6,5,8,1,7,10,2],
'售后服務(wù)質(zhì)量評(píng)價(jià)排位':[8,2,5,4,7,9,1,6,10,3]})
df

pd.Series.corr(df['品牌知名度排位'], df['售后服務(wù)質(zhì)量評(píng)價(jià)排位'],method = 'spearman')
import scipy.stats as stats
X = df['品牌知名度排位']
Y = df['售后服務(wù)質(zhì)量評(píng)價(jià)排位']
corr, p_value = stats.spearmanr(X, Y)
print("斯皮爾曼相關(guān)系數(shù):", corr)
print("p值:", p_value)
結(jié)論:p = 0.0008<0.05,表明兩變量之間的正向關(guān)系很顯著���。
二分類變量(自然)vs 連續(xù)型變量 :Point-biserial
假設(shè)我們想要研究性別對(duì)于某種疾病是否存在影響����。我們有一個(gè)二元變量“性別”(男、女)和一個(gè)連續(xù)型變量“疾病指數(shù)”�。我們想要計(jì)算性別與疾病指數(shù)之間的相關(guān)系數(shù),就需要用到Point-biserial相關(guān)系數(shù)��。
import scipy.stats as stats
gender = [0, 1, 0, 1, 1, 0]
disease_index = [3.2, 4.5, 2.8, 4.0, 3.9, 3.1]
corr, p_value = stats.pointbiserialr(gender, disease_index)
print("Point-biserial相關(guān)系數(shù):", corr)
print("p值:", p_value)
結(jié)論:p = 0.007<0.05����,表明兩變量之間的正向關(guān)系很顯著。即性別與疾病指數(shù)正相關(guān)
假設(shè)我們想要比較不同教育水平的學(xué)生在CDA考試成績(jī)上是否存在顯著差異���。我們有一個(gè)無序分類變量“教育水平”(高中��、本科�、研究生)和一個(gè)連續(xù)型變量“考試成績(jī)”�����。
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
data = pd.DataFrame({
'教育水平': ['高中', '本科', '本科', '研究生', '高中', '本科', '研究生'],
'考試成績(jī)': [80, 90, 85, 95, 75, 88, 92]
})
model = ols('考試成績(jī) ~ C(教育水平)', data=data).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table

結(jié)論:p = 0.0102<0.05����,拒絕原假設(shè),表明兩變量之間的正向關(guān)系很顯著。教育水平與考試成績(jī)正相關(guān)
將連續(xù)型變量離散化后當(dāng)做有序分類�����,然后用 有序分類變量 VS 有序分類變量的方法
二分類變量 vs 二分類變量 :檢驗(yàn) 聯(lián)合 Cramer's V
一項(xiàng)研究調(diào)查了不同性別的成年人對(duì)在公眾場(chǎng)合吸煙的態(tài)度�����,結(jié)果如表所示��。那么���,性別與對(duì)待吸煙的態(tài)度之間的相關(guān)程度
| - |
贊同 |
反對(duì) |
| 男 |
15 |
10 |
| 女 |
10 |
26 |
import numpy as np
from scipy.stats import chi2_contingency
observed = np.array([[15, 10],
[10, 26]])
observed
chi2, p, dof, expected = chi2_contingency(observed,correction =False)
chi2, p
結(jié)論:p = 0.0118<0.05�����,拒絕原假設(shè)�,表明兩變量之間的正向關(guān)系很顯著�����。
phi = np.sqrt(chi2/n)
print("phi's V:", phi)
卡方檢驗(yàn)時(shí)有多種指標(biāo)可表示效應(yīng)量��,可結(jié)合數(shù)據(jù)類型及交叉表格類型綜合選擇
- 第一:如果是2*2表格��,建議使用 指標(biāo)
- 第二:如果是33,或 44表格���,建議使用列聯(lián)系數(shù)����;
- 第三:如果是n*n(n>4)表格�,建議使用 校正列聯(lián)系數(shù);
- 第四:如果是m*n(m不等于n)表格���,建議使用 Cramer V指標(biāo)�;
- 第五:如果X或Y中有定序數(shù)據(jù)����,建議使用 指標(biāo);
這里只列出 指標(biāo) 和 Cramer V指標(biāo) 的計(jì)算���,其他計(jì)算方式請(qǐng)讀者自行研究�。
contingency_table = observed
n = contingency_table.sum().sum()
phi_corr = np.sqrt(chi2 / (n * min(contingency_table.shape) - 1))
v = phi_corr / np.sqrt(min(contingency_table.shape) - 1)
print("Cramer's V:", v)
import numpy as np
from scipy.stats import pearsonr
binary_variable = np.random.choice([0, 1], size=100)
continuous_variable = np.random.normal(loc=0, scale=1, size=100)
def biserial_correlation(binary_variable, continuous_variable):
binary_variable_bool = binary_variable.astype(bool)
binary_mean = np.mean(binary_variable_bool)
binary_std = np.std(binary_variable_bool)
binary_variable_norm = (binary_variable_bool - binary_mean) / binary_std
corr, _ = pearsonr(binary_variable_norm, continuous_variable)
biserial_corr = corr * (np.std(continuous_variable) / binary_std)
return biserial_corr
biserial_corr = biserial_correlation(binary_variable, continuous_variable)
print("Biserial相關(guān)系數(shù):", biserial_corr)
Biserial相關(guān)系數(shù): -0.2061772328681707
無序分類變量 vs 無序分類變量
參考 檢驗(yàn)
有序分類變量 vs 無序分類變量
參考 檢驗(yàn)
有序分類變量 vs 有序分類變量
Kendall秩相關(guān)系數(shù)也是一種非參數(shù)的等級(jí)相關(guān)度量����,類似于Spearman等級(jí)相關(guān)系數(shù)���。
import random
import numpy as np
import pandas as pd
np.random.seed(10)
df = pd.DataFrame({'品牌知名度排位':[9,4,3,6,5,8,1,7,10,2],
'售后服務(wù)質(zhì)量評(píng)價(jià)排位':[8,2,5,4,7,9,1,6,10,3]})
df
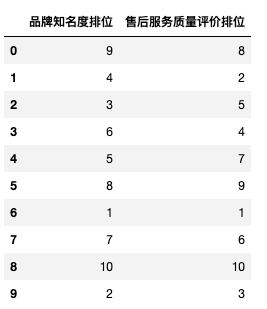
pd.Series.corr(df['品牌知名度排位'], df['售后服務(wù)質(zhì)量評(píng)價(jià)排位'],method = 'kendall')
from scipy.stats import kendalltau
x = df['品牌知名度排位']
y = df['售后服務(wù)質(zhì)量評(píng)價(jià)排位']
correlation, p_value = kendalltau(x, y)
print("Kendall Tau相關(guān)系數(shù):", correlation)
print("p值:", p_value)
浮生皆縱,恍如一夢(mèng)��,讓我們只爭(zhēng)朝夕,不負(fù)韶華��!
下期將為大家?guī)?a href="http://www.3lll3.cn/bigdata/205068.html" style="text-decoration: none; color: #1e6bb8; word-wrap: break-word; font-weight: bold; border-bottom: 1px solid #1e6bb8;">《統(tǒng)計(jì)學(xué)極簡(jiǎn)入門》之 再看t檢驗(yàn)�、F檢驗(yàn)、檢驗(yàn)
推薦學(xué)習(xí)書籍
《CDA一級(jí)教材》適合CDA一級(jí)考生備考����,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我。完整電子版已上線CDA網(wǎng)校���,累計(jì)已有10萬+在讀~

免費(fèi)加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330