機(jī)器學(xué)習(xí)基礎(chǔ)—梯度下降法(Gradient Descent)
梯度下降法���。一開始只是對其做了下簡單的了解��。隨著內(nèi)容的深入��,發(fā)現(xiàn)梯度下降法在很多算法中都用的到,除了之前看到的用來處理線性模型��,還有BP神經(jīng)網(wǎng)絡(luò)等��。于是就有了這篇文章�����。
本文主要講了梯度下降法的兩種迭代思路�,隨機(jī)梯度下降(Stochastic gradient descent)和批量梯度下降(Batch gradient descent)。以及他們在python中的實現(xiàn)����。
梯度下降法
梯度下降是一個最優(yōu)化算法,通俗的來講也就是沿著梯度下降的方向來求出一個函數(shù)的極小值����。那么我們在高等數(shù)學(xué)中學(xué)過,對于一些我們了解的函數(shù)方程��,我們可以對其求一階導(dǎo)和二階導(dǎo),比如說二次函數(shù)��??墒俏覀冊谔幚韱栴}的時候遇到的并不都是我們熟悉的函數(shù),并且既然是機(jī)器學(xué)習(xí)就應(yīng)該讓機(jī)器自己去學(xué)習(xí)如何對其進(jìn)行求解�����,顯然我們需要換一個思路����。因此我們采用梯度下降,不斷迭代����,沿著梯度下降的方向來移動,求出極小值��。
此處我們還是用coursea的機(jī)器學(xué)習(xí)課中的案例�����,假設(shè)我們從中介那里拿到了一個地區(qū)的房屋售價表��,那么在已知房子面積的情況下,如何得知房子的銷售價格�。顯然,這是一個線性模型��,房子面積是自變量x����,銷售價格是因變量y���。我們可以用給出的數(shù)據(jù)畫一張圖���。然后,給出房子的面積�����,就可以從圖中得知房子的售價了�����。
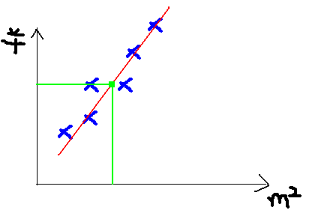
現(xiàn)在我們的問題就是���,針對給出的數(shù)據(jù)���,如何得到一條最擬合的直線�。
對于線性模型���,如下����。
h(x)是需要擬合的函數(shù)����。
J(θ)稱為均方誤差或cost function。用來衡量訓(xùn)練集眾的樣本對線性模式的擬合程度��。
m為訓(xùn)練集眾樣本的個數(shù)��。
θ是我們最終需要通過梯度下降法來求得的參數(shù)�����。
\[h(\theta)=\sum_{j=0}^n \theta_jx_j \\ J(\theta)=\frac1{2m}\sum_{i=0}^m(y^i-h_\theta(x^i))^2\]
接下來的梯度下降法就有兩種不同的迭代思路�。
批量梯度下降(Batch gradient descent)
現(xiàn)在我們就要求出J(θ)取到極小值時的\(θ^T\)向量。之前已經(jīng)說過了��,沿著函數(shù)梯度的方向下降就能最快的找到極小值����。
計算J(θ)關(guān)于\(\theta^T\)的偏導(dǎo)數(shù),也就得到了向量中每一個\(\theta\)的梯度�����。
\[ \begin{align} \frac{\partial J(\theta)}{\partial\theta_j} & = -\frac1m\sum_{i=0}^m(y^i-h_\theta(x^i)) \frac{\partial}{\partial\theta_j}(y^i-h_\theta(x^i)) \\ & = -\frac1m\sum_{i=0}^m(y^i-h_\theta(x^i)) \frac{\partial}{\partial\theta_j}(\sum_{j=0}^n\theta_jx_j^i-y^i) \\ & = -\frac1m\sum_{i=0}^m(y^i-h_\theta(x^i))x^i_j \end{align} \]
沿著梯度的方向更新參數(shù)θ的值
\[ \theta_j := \theta_j + \alpha\frac{\partial J(\theta)}{\partial\theta_j} :=\theta_j - \alpha\frac1m\sum_{i=0}^m(y^i-h_\theta(x^i))x^i_j \]
迭代直到收斂�����。
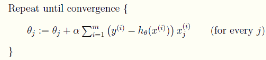
可以看到��,批量梯度下降是用了訓(xùn)練集中的所有樣本。因此在數(shù)據(jù)量很大的時候���,每次迭代都要遍歷訓(xùn)練集一遍��,開銷會很大��,所以在數(shù)據(jù)量大的時候���,可以采用隨機(jī)梯度下降法。
隨機(jī)梯度下降(Stochastic gradient descent)
和批量梯度有所不同的地方在于����,每次迭代只選取一個樣本的數(shù)據(jù),一旦到達(dá)最大的迭代次數(shù)或是滿足預(yù)期的精度,就停止���。
可以得出隨機(jī)梯度下降法的θ更新表達(dá)式��。
\[ \theta_j:=\theta_j - \alpha\frac1m(y^i-h_\theta(x^i))x^i_j \]
迭代直到收斂��。
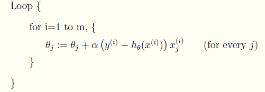
兩種迭代思路的python實現(xiàn)
下面是python的代碼實現(xiàn)�,現(xiàn)在僅僅是用純python的語法(python2.7)來實現(xiàn)的��。隨著學(xué)習(xí)的深入���,屆時還會有基于numpy等一些庫的實現(xiàn)�����,下次補(bǔ)充����。
#encoding:utf-8
#隨機(jī)梯度
def stochastic_gradient_descent(x,y,theta,alpha,m,max_iter):
"""隨機(jī)梯度下降法����,每一次梯度下降只使用一個樣本。
:param x: 訓(xùn)練集種的自變量
:param y: 訓(xùn)練集種的因變量
:param theta: 待求的權(quán)值
:param alpha: 學(xué)習(xí)速率
:param m: 樣本總數(shù)
:param max_iter: 最大迭代次數(shù)
"""
deviation = 1
iter = 0
flag = 0
while True:
for i in range(m): #循環(huán)取訓(xùn)練集中的一個
deviation = 0
h = theta[0] * x[i][0] + theta[1] * x[i][1]
theta[0] = theta[0] + alpha * (y[i] - h)*x[i][0]
theta[1] = theta[1] + alpha * (y[i] - h)*x[i][1]
iter = iter + 1
#計算誤差
for i in range(m):
deviation = deviation + (y[i] - (theta[0] * x[i][0] + theta[1] * x[i][1])) ** 2
if deviation <EPS or iter >max_iter:
flag = 1
break
if flag == 1 :
break
return theta, iter
#批量梯度
def batch_gradient_descent(x,y,theta,alpha,m,max_iter):
"""批量梯度下降法��,每一次梯度下降使用訓(xùn)練集中的所有樣本來計算誤差。
:param x: 訓(xùn)練集種的自變量
:param y: 訓(xùn)練集種的因變量
:param theta: 待求的權(quán)值
:param alpha: 學(xué)習(xí)速率
:param m: 樣本總數(shù)
:param max_iter: 最大迭代次數(shù)
"""
deviation = 1
iter = 0
while deviation > EPS and iter < max_iter:
deviation = 0
sigma1 = 0
sigma2 = 0
for i in range(m): #對訓(xùn)練集中的所有數(shù)據(jù)求和迭代
h = theta[0] * x[i][0] + theta[1] * x[i][1]
sigma1 = sigma1 + (y[i] - h)*x[i][0]
sigma2 = sigma2 + (y[i] - h)*x[i][1]
theta[0] = theta[0] + alpha * sigma1 /m
theta[1] = theta[1] + alpha * sigma2 /m
#計算誤差
for i in range(m):
deviation = deviation + (y[i] - (theta[0] * x[i][0] + theta[1] * x[i][1])) ** 2
iter = iter + 1
return theta, iter
#運(yùn)行 為兩種算法設(shè)置不同的參數(shù)
# data and init
matrix_x = [[2.1,1.5],[2.5,2.3],[3.3,3.9],[3.9,5.1],[2.7,2.7]]
matrix_y = [2.5,3.9,6.7,8.8,4.6]
MAX_ITER = 5000
EPS = 0.0001
#隨機(jī)梯度
theta = [2,-1]
ALPHA = 0.05
resultTheta,iters = stochastic_gradient_descent(matrix_x, matrix_y, theta, ALPHA, 5, MAX_ITER)
print 'theta=',resultTheta
print 'iters=',iters
#批量梯度
theta = [2,-1]
ALPHA = 0.05
resultTheta,iters = batch_gradient_descent(matrix_x, matrix_y, theta, ALPHA, 5, MAX_ITER)
print 'theta=',resultTheta
print 'iters=',iters
運(yùn)行結(jié)果
ALPHA = 0.05ALPHA = 0.05
theta= [-0.08445285887795494, 1.7887820818368738]
iters= 1025
theta= [-0.08388979324755381, 1.7885951009289043]
iters= 772
[Finished in 0.5s]
ALPHA = 0.01
theta= [-0.08387216503392847, 1.7885649678753883]
iters= 3566
theta= [-0.08385924864202322, 1.788568071697816]
iters= 3869
[Finished in 0.1s]
ALPHA = 0.1
theta= [588363545.9596066, -664661366.4562845]
iters= 5001
theta= [-0.09199523483489512, 1.7944581778450577]
iters= 516
[Finished in 0.2s]
總結(jié)
梯度下降法是一種最優(yōu)化問題求解的算法��。有批量梯度和隨機(jī)梯度兩種不同的迭代思路���。他們有以下的差異:
批量梯度收斂速度慢�,隨機(jī)梯度收斂速度快�。
批量梯度是在θ更新前對所有樣例匯總誤差,而隨機(jī)梯度下降的權(quán)值是通過考查某個樣本來更新的
批量梯度的開銷大����,隨機(jī)梯度的開銷小。數(shù)據(jù)分析師培訓(xùn)
使用梯度下降法時需要尋找出一個最好的學(xué)習(xí)效率�。這樣可以使得使用最少的迭代次數(shù)達(dá)到我們需要的精度�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330