IBM SPSS Modeler算法系列--決策樹CHAID算法
談到算法���,大家都覺得挺神秘的,對沒有學過統(tǒng)計學相關(guān)知識的朋友來說����,太多的數(shù)學公式?jīng)]法理解,很多書籍介紹的也比較表象�,看得云里霧里的����,那么今天�,我們將嘗試給大家介紹SPSS Modeler里面所涵蓋的一些算法內(nèi)容�,既不那么地表象��,也不那么地難以理解����。
我們首先從決策樹算法開始����,先介紹CHAID算法���, 它是由Kass在1975年提出的���,全稱是Chi-squaredAutomatic Interaction Detector�,可以翻譯為卡方自動交叉檢驗�,從名稱可以看出�,它的核心是卡方檢驗��,那么我們先來了解下什么是卡方檢驗。
卡方檢驗只針對分類變量,它是統(tǒng)計樣本的實際觀測值與理論推斷值之間的偏離程度���,實際觀測值與理論推斷值之間的偏離程度就決定卡方值的大小,卡方值越大���,偏離程度越大�����;卡方值越小,偏差越小����,若兩個值完全相等時����,卡方值就為0,表明理論值完全符合����。
在CHAID算法中,我們可以結(jié)合下面這個例子來理解卡方檢驗上面這段話�����。
這個例子中�����,我們要分析的目標是女性考慮結(jié)婚與不結(jié)婚的問題(0表示不結(jié)婚����,1表示結(jié)婚),那么影響結(jié)婚不結(jié)婚的因素有很多��,比如男方有沒有房子��,男方收入水平��, 幸福指數(shù)等等���。那么我們先來看看到底是否有房對是否結(jié)婚是否有影響����。
首先�����,我們對數(shù)據(jù)做下統(tǒng)計:
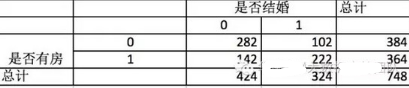
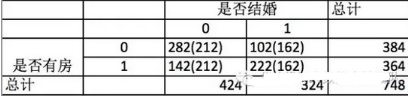
我們先假設是否有房與結(jié)婚沒有關(guān)系�����,那么四個格子應該是括號里的數(shù)(理論值)����,這和實際值(括號外的數(shù))是有差距的,理論和實際的差距說明原假設不成立����。
那么這個差距怎么來評判呢�����?我們就用到卡方的計算公式:
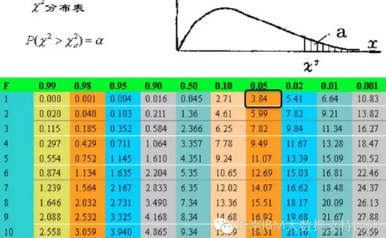
K方的計算公式可以這么描述��, 這四個格子里���,每個格子的(實際值-理論值)^2/理論值��,即K^2 ==(282-212)^2/212+(102-162) ^2/162+(142-212) ^2/212+(222-162) ^2/162=90.6708���,然后我們再去查卡方表,可以看到�����,自由度為1�����,顯著性水平為0.05的卡方臨界值為3.84���。計算得到的卡方值大于3.84,也就是說��,原假設成立的概率小于0.05,即5%,所以我們拒絕原假設�,可以得到是否有房對結(jié)婚是有影響的。從卡方的計算方法中����,可以看到卡方越大,實際值與理論值差異越大��,兩者沒有關(guān)系的原假設就越不成立��。
那么以上就是對卡方檢驗在分析兩者關(guān)系的介紹。
接下來我們回到CHAID算法���,我們在IBM SPSS Modeler構(gòu)建這個模型�,得到的決策樹結(jié)果如下(部分截圖):
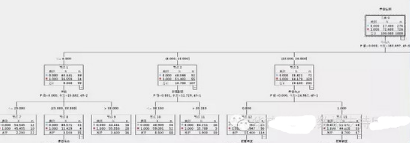
很多人看到這個圖的時候����,一般會有兩個疑惑��,第一個�����,影響的第一個最重要的因素是年收入��,那么年收入?yún)^(qū)間的劃分為什么是 [<=6.000]�、[6.000,13.000]……這個以6.0�����、13.0等為臨界劃分點,是預先設定好的嗎�?當然不是,這是CHAID這個算法的計算邏輯決定的��。第二個疑惑是�����,為什么會以年收入作為第一個分割點����,而不是其它呢?
我們先來看第一個問題��,劃分的臨界點是怎么確定的���,這個問題�����,其實是該算法中�,對數(shù)據(jù)預處理的部分。 需要注意的是, 卡方檢驗只針對分類變量��,而CHAID算法,是支持數(shù)值變量和分類變量的����,所以��,首先算法的第一步,就是對輸入變量做預處理,分兩種情況,輸入變量是數(shù)值型或者是分類型���,先來介紹輸入變量是數(shù)值型的情況,比如我們例子中的年收入就是數(shù)值型的�����,那么�����,需要先將其離散化成為字符型�,也就是劃分區(qū)間����,這里采用的是ChiMerge分組法����,這個接下來會結(jié)合這個例子的年收入指標來介紹下這個分組法����。
Step1:對年收入值從小到大進行排序1�����、2、3��、4…….
Step2:定義若干初始區(qū)間�,使輸入變量的每個變量值均單獨落入一個區(qū)間內(nèi),像這里的收入都是整數(shù),所以會以1作為組限��,分為[1]�、[2]�、[3]、[4]……等各個區(qū)間;
Step3:計算每個切分好的年收入值的頻次��,得到輸入變量與輸出變量的交叉分組頻數(shù)表�����。
Step4:計算兩兩相臨組的卡方值��。根據(jù)顯著性水平和自由度得到卡方臨界值���。如果卡方值小于臨界值���,說明輸入變量在該相鄰區(qū)間上的劃分��,對輸出變量取值沒有顯著影響�,可以合并;
這里的Step3和Step4,我們這么來理解�,輸入變量是年收入�����,我們已經(jīng)把它劃分為[1]�、[2]……,那么在下面這個表中��,我們先計算了年收入第一位和第二位分別為1和2的人數(shù)(即Step3中的頻次計算)��,得到下面這個交叉表:
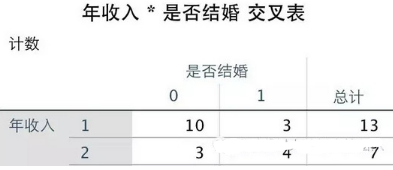
然后開始計算卡方值,卡方值的計算公式為: K^2 = n (ad - bc) ^ 2 / [(a+b)(c+d)(a+c)(b+d)] 其中a���、b、c、d分別對應的值如下圖:(其中n=a+b+c+d為樣本容量)�����。
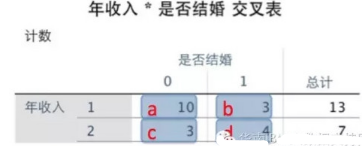
因此計算得到的卡方值=(10+3+3+4)*(10*4-3*3)^2/[(10+3)(3+4)(10+3)(3+4)]=2.321
細心的朋友可能會發(fā)現(xiàn),這個計算公式跟我們上面計算的公式寫法有點不一樣����,其實是經(jīng)過公式變形的,上面是為了更好地理解卡方的含義���,下面這個公式是變形后�,比較好記的公式。
這個時候�,我們查看卡方表如下圖:
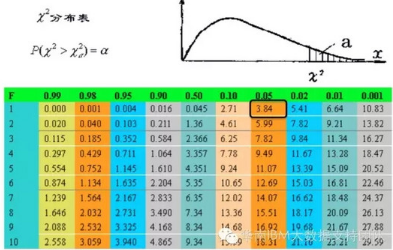
可以看到,自由度為1�����,顯著性水平為0.05的卡方臨界值為3.84�,我們計算得到的卡方2.321小于3.84����,說明年收入為1或者2�����,對結(jié)婚或者不結(jié)婚沒有顯著影響,因此可以合并��,所以會將收入為[1]����、[2]合并為[1,2]���;接下來計算[3]���、[4]的卡方�����,依次類推�。
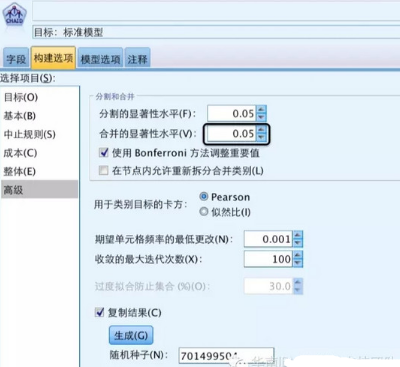
PS:這里選擇的顯著性水平為0.05是可以自己設置更改的��,在SPSS Modeler的CHAID算法中可以自己設置���,如下圖位置:
Step5:重復Step3至Step4,直到任何兩個相臨組無法合并��,即卡方值都不小于臨界值為止��。
那么如果輸入變量是分類型的��,與上面的數(shù)值型對比���,就少了一次對數(shù)值離散化的過程���,直接對分類變量中的元素進行卡方檢驗及合并���,最終形成“超類”�����,直至輸入變量的“超類”無法再合并為止����。對于順序型分類輸入變量��,只能合并相鄰的類別���。
對數(shù)據(jù)完成預處理之后���,就要選擇根節(jié)點�,也就是計算輸出變量(是否結(jié)婚)與輸入變量相關(guān)性檢驗的統(tǒng)計量的概率P-值,即卡方值對應的P-值�����,P-值越小��,說明輸入變量與輸出變量的關(guān)系越緊密���,應當作為當前最佳分組變量。當P-值相同時����,應該選擇檢驗統(tǒng)計量觀測值最大的輸入變量�,也就是卡方最大的輸入變量���。
在上面的決策樹圖中���,我們可以看到,每個指標都有計算好的卡方值和P-值����,從分析結(jié)果中�,也可以驗證上面所說的�,P-值越小�,越在樹的頂端���,P-值相同時����,卡方越大�,越在樹的頂端�����。
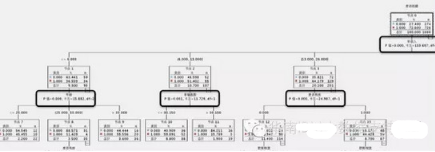
到這里���,就解答了一開始查看決策樹時候的兩個疑惑����。
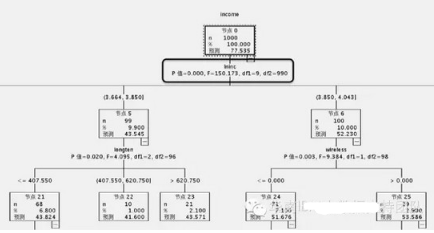
我們這個例子里面呢���,目標變量是否結(jié)婚���,是分類型的變量����,那么�,如果目標變量是數(shù)值型的呢?那么在第一步的數(shù)據(jù)預處理的時候,把采用的卡方值計算改為方差計算����,在第二步選擇最佳分割點的時候���,使用的是方差分析計算得到F統(tǒng)計量的P-值,而不是卡方的P-值����。
這里以Income這個連續(xù)變量作為輸出變量(即目標)為例,得到的決策樹�����,對應的值就是P值以及F統(tǒng)計量�����,如下圖:
針對這個算法�����,有以下幾個特點總結(jié)下:
樣本數(shù)據(jù)必須足夠大���,要求樣本含量應大于40且每個格子中的理論頻數(shù)不應小于5�����。當樣本含量大于40但有1=<理論頻數(shù)<5時�����,卡方值需要校正���,當樣本含量小于40或理論頻數(shù)小于1時只能用確切概率法計算概率�����。
目標變量可以是分類型��,也可以是數(shù)值型��;
輸入變量可以是分類型����,也可以是數(shù)值型��。
在IBM SPSS Modeler里面,針對 CHAID算法�����,以上介紹的內(nèi)容是大概的計算框架�,里面其實還開放出了許多參數(shù)可以影響這個樹的生長,比如不用Pearson 卡方���,而是似然比卡方�����;使用交互樹生長模型來影響樹的生長;中止樹生長的規(guī)則等等��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330