SPSS與Streams的集成實現(xiàn)實時預(yù)測
SPSS Modeler 是一個數(shù)據(jù)挖掘工作臺����,提供了一個可了解數(shù)據(jù)并生成預(yù)測模型的最先進的環(huán)境����。Streams 提供了一個可伸縮的高性能環(huán)境,對不斷變化的數(shù)據(jù)進行實時分析�����,這些數(shù)據(jù)中包括傳統(tǒng)結(jié)構(gòu)的數(shù)據(jù)和半結(jié)構(gòu)化到非結(jié)構(gòu)化數(shù)據(jù)類型��。
在實時處理需要高級分析時��,使用Streams和SPSS集成���,實現(xiàn)實時評分預(yù)測���。實時應(yīng)用預(yù)測分析的用例的示例包括網(wǎng)絡(luò)安全、銀行和信用卡欺詐檢測�、預(yù)測性維護,以及實時營銷產(chǎn)品。
Streams + SPSS Analytics Toolkit 的特點
利用Streams實現(xiàn)高吞吐量����、低延遲的評分
利用SPSS Modeler開發(fā)和建立評分模型
通過SPSSScoring Operator將模型部署到Streams
模型更新而無需暫停Streams
通過SPSS Collaboration and Deployment Services管理模型的生命周期
SPSS Analytics Toolkit for Streams
SPSSScoring operator
SPSSScoring operator實現(xiàn)在Streams應(yīng)用中使用預(yù)定義的SPSS的預(yù)測模型進行評分預(yù)測�����,它假設(shè)預(yù)測模型已經(jīng)在SPSS Moduler定義好并通過SPSS Solution Publisher導(dǎo)出這三個文件:
model.pim
model.par
model.xml
SPSSScoring 代碼例子
stream<DataSchemaPlus> scorer = com.ibm.spss.streams.analytics::SPSSScoring(data)
{parampimfile: getThisToolkitDir() +"/etc/PimParXml/model.pim";
parfile: getThisToolkitDir() +"/etc/PimParXml/model.par";
xmlfile: getThisToolkitDir() +"/etc/PimParXml/model.xml";
modelFields:"sex","income";
streamAttributes: s_sex, baseSalary+bonusSalary;
output
scorer:
income = fromModel("income"),
predLabel = fromModel("$C-beer_beans_pizza"),
confidence = fromModel("$CC-beer_beans_pizza");
}
SPSSPublish operator
SPSSPublish operator 自動“發(fā)布”的一個模型文件的評分分支并總結(jié)所生成的文件�,以便下游的Operator可以通過“分布”操作所創(chuàng)建或更新的PIM��、PAR和XML文件,刷新他們的評分標(biāo)準(zhǔn)實施���。通常情況下����,SPSSPublish operator配合上游的DirectoryScan 或 SPSSRepository operator�,及下游的SPSSScoring operator,即:
DirecoryScan/SPSSRepository -> SPSSPublish -> SPSSScoring
其中DirectoryScan 或 SPSSRepository operator檢測到有新的模型文件可用�����,就將新模型的文件名發(fā)生個SPSSPublish operator�����。SPSSPublish的下游通常是SPSSSoring����。當(dāng)SPSSPublish獲取到新模型��,它就會生成SPSSSoring所需的PIM、PAR和XML文件�����,然后發(fā)生通知給SPSSSoring����,通知也新的模型可用了。SPSSScoring收到通知后會刷新內(nèi)部模型���。
SPSSPublish代碼例子:
stream<rstring strFilePath> strFile = DirectoryScan(){
param
directory : "/tmp";
pattern : "newmodel.str";
ignoreExistingFilesAtStartup : true;
config placement : host(P1);
}
stream<rstring fileName> notifier = com.ibm.spss.streams.analytics::SPSSPublish(strFile){
param
sourceFile: "newmodel.str";
targetPath: "/tmp";
config placement : host(P1);
}
stream<DataSchemaPlus> scorer = com.ibm.spss.streams.analytics::SPSSScoring(data;notifier) {
param
pimfile: getThisToolkitDir() +"/etc/PimParXml/model.pim";
parfile: getThisToolkitDir() +"/etc/PimParXml/model.par";
xmlfile: getThisToolkitDir() +"/etc/PimParXml/model.xml";
modelFields: "sex","income";
streamAttributes: s_sex, baseSalary+bonusSalary;
output
scorer:
income = fromModel("income"),
predLabel = fromModel("$C-beer_beans_pizza"),
confidence = fromModel("$CC-beer_beans_pizza");
config placement : host(P1);
}
SPSSRepository operator
SPSSRepository operator監(jiān)視部署在SPSS Collaboration and Deployment Services庫的對象的變化��。當(dāng)被監(jiān)控的對象發(fā)生變化�����,相關(guān)通知則會發(fā)給所有的Listener�����。收到通知�,SPSSRepostory會從Repostory下載該對象的新版本文件并將文件寫到目標(biāo)目錄�����,這步操作成功之后����,SPSSRepostory再提交描述文件已更新的事件給下游Operator。
Streams + SPSS 的參考架構(gòu)
根據(jù)前面對SPSS Analytics Toolkit的功能描述����,Streams + SPSS的參考架構(gòu)可以由下圖表示:
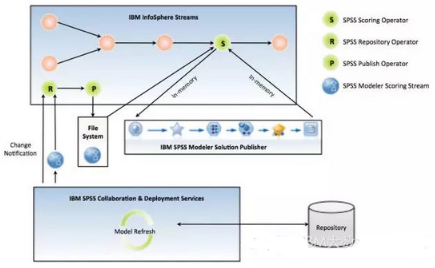
小結(jié)
本文通過對SPSS Analytics Toolkit和這些Toolkit與Streams集成參考架構(gòu)的描述���,為讀者呈現(xiàn)了如何使用業(yè)界最好的數(shù)據(jù)挖掘工具SPSS和流數(shù)據(jù)分析平臺Streams進行實時評分和預(yù)測����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330