R語(yǔ)言SQL管理數(shù)據(jù)庫(kù)的方法
SQL��,是結(jié)構(gòu)語(yǔ)言化查詢語(yǔ)言(Structured Query Language)的簡(jiǎn)稱���。SQL語(yǔ)言是一種數(shù)據(jù)庫(kù)查詢和程序設(shè)計(jì)語(yǔ)言,用于存取數(shù)據(jù)以及查詢�����、更新和管理關(guān)系數(shù)據(jù)庫(kù)系統(tǒng)�;同時(shí)也是數(shù)據(jù)庫(kù)腳本文件的擴(kuò)展名。
sqldf程序包是R語(yǔ)言中實(shí)用的數(shù)據(jù)管理輔助工具����,sqldf程序包中比較常用的是sqldf函數(shù)中的select 語(yǔ)句�����。
#使用SQL語(yǔ)句操作數(shù)據(jù)框�����,需要加載的程序包sqldf,tcltk��,使用iris數(shù)據(jù)集以及演示
library(sqldf)
library(tcltk)
head(iris)#了解數(shù)據(jù)集由5各變量組成
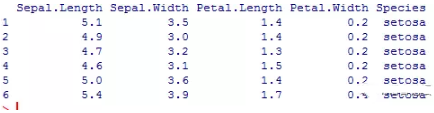
#取出前幾行
a1r <- head(iris,10)#一般方法
a1s <- sqldf("select * from iris limit 10")#取出數(shù)據(jù)框的前六行�,關(guān)鍵詞limit
identical(a1r, a1s)#比較兩個(gè)數(shù)據(jù)框是否相同
#取出子集
a2r <- subset(iris, grepl("^se", Species))#取出物種列中以se開(kāi)頭的數(shù)據(jù)子集
a2s <- sqldf("select * from iris where Species like 'se%'")#取出數(shù)據(jù)的子集��,關(guān)鍵詞like
all.equal(as.data.frame(a2r), a2s)#檢驗(yàn)數(shù)據(jù)是否有差異
#指定某變量值為兩個(gè)以上時(shí)的提取
a3r <- subset(iris, Species %in% c("setosa", "virginica"))#在iris數(shù)據(jù)集中����,選出量物種是setosa和virginica的行
a3s <- sqldf("select * from iris where Species in ('setosa', 'virginica')")#注意單引號(hào)和雙引號(hào)
row.names(a3r) <- NULL#a3r選的是子集,因而行名還是與原數(shù)據(jù)集相同
identical(a3r, a3s)
#指定某變量范圍時(shí)數(shù)據(jù)集的提取
a4r <- subset(iris, Petal.Length >= 0 & Petal.Length <= 2.0)#選取breaks在20到30之間的數(shù)據(jù)
a4s <- sqldf("select * from iris where Petal.Length between 0 and 2.0", row.names = TRUE)#使用row.names=TRUE可以不把行名重命名
iris$Petal.Length
#數(shù)據(jù)合計(jì)
a5r <- aggregate(iris[1:2], iris[5], mean)#計(jì)算出了3個(gè)物種前兩個(gè)變量的平均值
a5s <- sqldf('select Species, avg("Sepal.Length") `Sepal.Length`, avg("Sepal.Width") `Sepal.Width` from iris group by Species')#關(guān)鍵詞group by
all.equal(a5r, a5s)#查看數(shù)據(jù)是否相同
# 提取某變量breaks從小到大排序后的前3行的數(shù)據(jù)��,除數(shù)據(jù)屬性和列名外相同
head(warpbreaks)
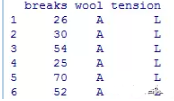
a6r <- head(warpbreaks[order(warpbreaks$breaks), ], 3)
a6s <- sqldf("select * from warpbreaks order by breaks limit 3")
# attributes(a6r) <- attributes(a6s) <- NULL#去除屬性
row.names(a6r) <- NULL#去除列
identical(a6r, a6s)
# 提取某變量breaks從大到小排序后的前3行的數(shù)據(jù)�����,除數(shù)據(jù)屬性和列名外相同
a7r <- head(warpbreaks[order(warpbreaks$breaks, decreasing = TRUE), ], 3)
a7s <- sqldf("select * from warpbreaks order by breaks desc limit 3")#關(guān)鍵詞order by,desc表示降序
row.names(a7r) <- NULL
identical(a7r, a7s)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330