Python數(shù)據(jù)挖掘之Kmeans聚類代碼實(shí)現(xiàn)、作業(yè)及優(yōu)化
這篇文章直接給出上次關(guān)于Kmeans聚類的籃球遠(yuǎn)動(dòng)員數(shù)據(jù)分析案例�,同時(shí)介紹這次作業(yè)同學(xué)們完成的圖例,最后介紹Matplotlib包繪圖的優(yōu)化知識(shí)�。
前文推薦:
Python數(shù)據(jù)挖掘之Kmeans聚類數(shù)據(jù)分析及Anaconda介紹
希望這篇文章對(duì)你有所幫助,尤其是剛剛接觸數(shù)據(jù)挖掘以及大數(shù)據(jù)的同學(xué)���,同時(shí)準(zhǔn)備嘗試以案例為主的方式進(jìn)行講解�。如果文章中存在不足或錯(cuò)誤的地方�,還請(qǐng)海涵~
一. 案例實(shí)現(xiàn)
這里不再贅述��,詳見(jiàn)第二篇文章,直接上代碼���,這是我的學(xué)生完成的作業(yè)���。
數(shù)據(jù)集:
下載地址:KEEL-dataset - Basketball data set
籃球運(yùn)動(dòng)員數(shù)據(jù),每分鐘助攻和每分鐘得分?jǐn)?shù)�。通過(guò)該數(shù)據(jù)集判斷一個(gè)籃球運(yùn)動(dòng)員屬于什么位置(控位、分位����、中鋒等)。完整數(shù)據(jù)集包括5個(gè)特征���,每分鐘助攻數(shù)���、運(yùn)動(dòng)員身高、運(yùn)動(dòng)員出場(chǎng)時(shí)間���、運(yùn)動(dòng)員年齡和每分鐘得分?jǐn)?shù)�。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
assists_per_minute height time_played age points_per_minute
0 0.0888 201 36.02 28 0.5885
1 0.1399 198 39.32 30 0.8291
2 0.0747 198 38.80 26 0.4974
3 0.0983 191 40.71 30 0.5772
4 0.1276 196 38.40 28 0.5703
5 0.1671 201 34.10 31 0.5835
6 0.1906 193 36.20 30 0.5276
7 0.1061 191 36.75 27 0.5523
8 0.2446 185 38.43 29 0.4007
9 0.1670 203 33.54 24 0.4770
10 0.2485 188 35.01 27 0.4313
11 0.1227 198 36.67 29 0.4909
12 0.1240 185 33.88 24 0.5668
13 0.1461 191 35.59 30 0.5113
14 0.2315 191 38.01 28 0.3788
15 0.0494 193 32.38 32 0.5590
16 0.1107 196 35.22 25 0.4799
17 0.2521 183 31.73 29 0.5735
18 0.1007 193 28.81 34 0.6318
19 0.1067 196 35.60 23 0.4326
20 0.1956 188 35.28 32 0.4280
完整代碼:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
# -*- coding: utf-8 -*-
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
X = [[0.0888, 0.5885],
[0.1399, 0.8291],
[0.0747, 0.4974],
[0.0983, 0.5772],
[0.1276, 0.5703],
[0.1671, 0.5835],
[0.1906, 0.5276],
[0.1061, 0.5523],
[0.2446, 0.4007],
[0.1670, 0.4770],
[0.2485, 0.4313],
[0.1227, 0.4909],
[0.1240, 0.5668],
[0.1461, 0.5113],
[0.2315, 0.3788],
[0.0494, 0.5590],
[0.1107, 0.4799],
[0.2521, 0.5735],
[0.1007, 0.6318],
[0.1067, 0.4326],
[0.1956, 0.4280]
]
print X
# Kmeans聚類
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
import numpy as np
import matplotlib.pyplot as plt
x = [n[0] for n in X]
print x
y = [n[1] for n in X]
print y
# 可視化操作
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans-Basketball Data")
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
plt.legend(["Rank"])
plt.show()
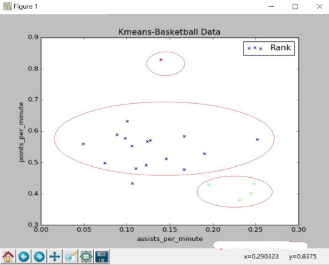
運(yùn)行結(jié)果:
從圖中可以看到聚集成三類���,紅色比較厲害���,得分很高;中間藍(lán)色是一類�����,普通球員�����;右小角綠色是一類��,助攻高得分低�,是控位�。
代碼分析:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
from sklearn.cluster import KMeans
表示在sklearn中處理kmeans聚類問(wèn)題�����,用到 sklearn.cluster.KMeans 這個(gè)類���。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
X = [[164,62],[156,50],...]
X是數(shù)據(jù)集,包括2列20行�,即20個(gè)球員的助攻數(shù)和得分?jǐn)?shù)。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
clf = KMeans(n_clusters=3)
表示輸出完整Kmeans函數(shù)���,包括很多省略參數(shù)�����,將數(shù)據(jù)集分成類簇?cái)?shù)為3的聚類��。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
y_pred =clf.fit_predict(X)
輸出聚類預(yù)測(cè)結(jié)果�,對(duì)X聚類��,20行數(shù)據(jù)���,每個(gè)y_pred對(duì)應(yīng)X的一行或一個(gè)孩子��,聚成3類�����,類標(biāo)為0���、1���、2。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
print(y_pred)
輸出結(jié)果:[0 2 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1]
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
import matplotlib.pyplot as plt
matplotlib.pyplot是用來(lái)畫圖的方法���,matplotlib是可視化包�。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
x = [n[0] for n in X]
y = [n[1] for n in X]
獲取第1列的值����, 使用for循環(huán)獲取 ,n[0]表示X第一列。
獲取第2列的值����,使用for循環(huán)獲取 ,n[1]表示X第2列。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
plt.scatter(x, y, c=y_pred, marker='o')
繪制散點(diǎn)圖(scatter)���,橫軸為x��,獲取的第1列數(shù)據(jù)�;縱軸為y,獲取的第2列數(shù)據(jù)�;c=y_pred對(duì)聚類的預(yù)測(cè)結(jié)果畫出散點(diǎn)圖,marker='o'說(shuō)明用點(diǎn)表示圖形��。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
plt.title("Kmeans-Basketball Data")
表示圖形的標(biāo)題為Kmeans-heightweight Data�。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
plt.xlabel("assists_per_minute")
表示圖形x軸的標(biāo)題����。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
plt.ylabel("points_per_minute")
表示圖形y軸的標(biāo)題。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
plt.legend(["Rank"])
設(shè)置右上角圖例����。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
plt.show()
表示顯示圖形。
二. 學(xué)生圖例
下面簡(jiǎn)單展示學(xué)生做的作業(yè)及分析�����,感覺(jué)還是不錯(cuò)���,畢竟才上幾節(jié)課而且第一次作業(yè)����,希望后面的作業(yè)更加精彩吧。因?yàn)閷W(xué)生的專業(yè)分布不同���,所以盡量讓學(xué)生設(shè)計(jì)他們專業(yè)的內(nèi)容�����。
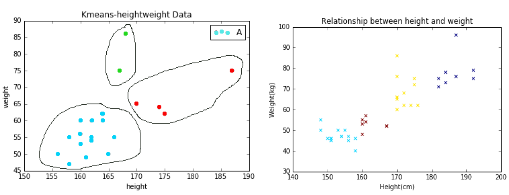
eg 遺傳學(xué)身高體重?cái)?shù)據(jù)
第一列表示孩子的身高�,單位cm����;第二列表示孩子的體重,單位kg�。從上圖可以看出,數(shù)據(jù)集被分為了三類�����。綠色為一類����、藍(lán)色為一類,紅色為一類��。
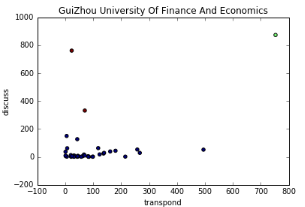
eg 微博數(shù)據(jù)集
第一列代表微博中某條信息的轉(zhuǎn)發(fā)量,第二列代表微博中某條信息的評(píng)論數(shù)��。從上圖可以看出���,總共分為3類�����,共三種顏色��,綠色一層說(shuō)明該信息轉(zhuǎn)發(fā)量與評(píng)論數(shù)都很高�。
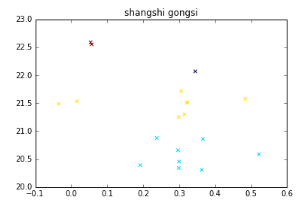
eg 上市公司財(cái)務(wù)報(bào)表
第一列表示公司利潤(rùn)率�����;第二列表示公司資產(chǎn)規(guī)模��。從上圖可以看出����,總共分為4類���,共四種顏色�����。暗紅色為資產(chǎn)規(guī)模最大�,依次至藍(lán)色資產(chǎn)規(guī)模減小。
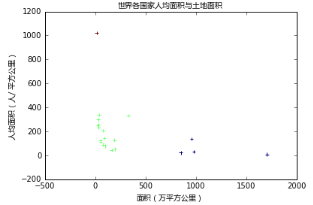
eg 世界各國(guó)家人均面積與土地面積
第一列表示各國(guó)家的人均面積(人/ 平方公里)����;第二列表示各國(guó)家的土地面積(萬(wàn)平方公里)。從上圖可以看出���,總共分為3類����,共三種顏色�����。紅色表示的國(guó)家相對(duì)來(lái)說(shuō)最擁擠��,可能是孟加拉這樣土地面積少且人口眾多的國(guó)家��;藍(lán)色就是地廣人稀的代表�����,比如俄羅斯、美國(guó)����、、墨西哥����、巴西;綠色表示人口密度分布比較平均的國(guó)家���。
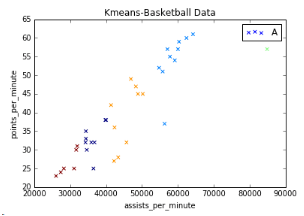
eg employee salaries數(shù)據(jù)集
第一列表示員工工資�;第二列表示員工年齡數(shù)�。從上圖可以看出,總共分為5類�����,共5種顏色����?����?傮w呈現(xiàn)正相關(guān)性,年齡越大��,工資越高��;除個(gè)別外��,總體正線性關(guān)系�。
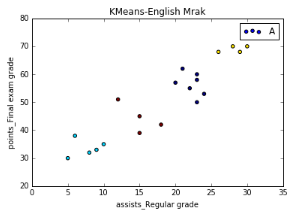
eg 學(xué)生英語(yǔ)成績(jī)數(shù)據(jù)集
第一列表示學(xué)生英語(yǔ)平時(shí)成績(jī);第二列表示學(xué)生英語(yǔ)期末成績(jī)��。從上圖可以看出�,總共分為4類,共四種顏色�����。黃色一層�����,平時(shí)成績(jī)和末考成績(jī)都很高�,屬于“學(xué)霸”級(jí)別的人物;其次��,藍(lán)色一層和紅色一層�����;最后,天藍(lán)色一層�,暫且稱之為“學(xué)渣”。
三. Matplotlib繪圖優(yōu)化
Matplotlib代碼的優(yōu)化:
1.第一部分代碼是定義X數(shù)組���,實(shí)際中是讀取文件進(jìn)行的��,如何實(shí)現(xiàn)讀取文件中數(shù)據(jù)再轉(zhuǎn)換為矩陣進(jìn)行聚類呢�?
2.第二部分是繪制圖形�����,希望繪制不同的顏色及類型��,使用legend()繪制圖標(biāo)�����。
假設(shè)存在數(shù)據(jù)集如下圖所示:data.txt
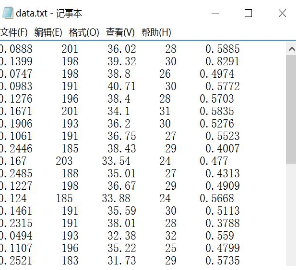
數(shù)據(jù)集包括96個(gè)運(yùn)動(dòng)員的數(shù)據(jù)����,源自:KEEL-dataset - Basketball data set
現(xiàn)需要獲取第一列每分鐘助攻數(shù)����、第五列每分鐘得分?jǐn)?shù)存于矩陣中���。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
0.0888 201 36.02 28 0.5885
0.1399 198 39.32 30 0.8291
0.0747 198 38.8 26 0.4974
0.0983 191 40.71 30 0.5772
0.1276 196 38.4 28 0.5703
0.1671 201 34.1 31 0.5835
0.1906 193 36.2 30 0.5276
0.1061 191 36.75 27 0.5523
0.2446 185 38.43 29 0.4007
0.167 203 33.54 24 0.477
0.2485 188 35.01 27 0.4313
0.1227 198 36.67 29 0.4909
0.124 185 33.88 24 0.5668
0.1461 191 35.59 30 0.5113
0.2315 191 38.01 28 0.3788
0.0494 193 32.38 32 0.559
0.1107 196 35.22 25 0.4799
0.2521 183 31.73 29 0.5735
0.1007 193 28.81 34 0.6318
0.1067 196 35.6 23 0.4326
0.1956 188 35.28 32 0.428
0.1828 191 29.54 28 0.4401
0.1627 196 31.35 28 0.5581
0.1403 198 33.5 23 0.4866
0.1563 193 34.56 32 0.5267
0.2681 183 39.53 27 0.5439
0.1236 196 26.7 34 0.4419
0.13 188 30.77 26 0.3998
0.0896 198 25.67 30 0.4325
0.2071 178 36.22 30 0.4086
0.2244 185 36.55 23 0.4624
0.3437 185 34.91 31 0.4325
0.1058 191 28.35 28 0.4903
0.2326 185 33.53 27 0.4802
0.1577 193 31.07 25 0.4345
0.2327 185 36.52 32 0.4819
0.1256 196 27.87 29 0.6244
0.107 198 24.31 34 0.3991
0.1343 193 31.26 28 0.4414
0.0586 196 22.18 23 0.4013
0.2383 185 35.25 26 0.3801
0.1006 198 22.87 30 0.3498
0.2164 193 24.49 32 0.3185
0.1485 198 23.57 27 0.3097
0.227 191 31.72 27 0.4319
0.1649 188 27.9 25 0.3799
0.1188 191 22.74 24 0.4091
0.194 193 20.62 27 0.3588
0.2495 185 30.46 25 0.4727
0.2378 185 32.38 27 0.3212
0.1592 191 25.75 31 0.3418
0.2069 170 33.84 30 0.4285
0.2084 185 27.83 25 0.3917
0.0877 193 21.67 26 0.5769
0.101 193 21.79 24 0.4773
0.0942 201 20.17 26 0.4512
0.055 193 29.07 31 0.3096
0.1071 196 24.28 24 0.3089
0.0728 193 19.24 27 0.4573
0.2771 180 27.07 28 0.3214
0.0528 196 18.95 22 0.5437
0.213 188 21.59 30 0.4121
0.1356 193 13.27 31 0.2185
0.1043 196 16.3 23 0.3313
0.113 191 23.01 25 0.3302
0.1477 196 20.31 31 0.4677
0.1317 188 17.46 33 0.2406
0.2187 191 21.95 28 0.3007
0.2127 188 14.57 37 0.2471
0.2547 160 34.55 28 0.2894
0.1591 191 22.0 24 0.3682
0.0898 196 13.37 34 0.389
0.2146 188 20.51 24 0.512
0.1871 183 19.78 28 0.4449
0.1528 191 16.36 33 0.4035
0.156 191 16.03 23 0.2683
0.2348 188 24.27 26 0.2719
0.1623 180 18.49 28 0.3408
0.1239 180 17.76 26 0.4393
0.2178 185 13.31 25 0.3004
0.1608 185 17.41 26 0.3503
0.0805 193 13.67 25 0.4388
0.1776 193 17.46 27 0.2578
0.1668 185 14.38 35 0.2989
0.1072 188 12.12 31 0.4455
0.1821 185 12.63 25 0.3087
0.188 180 12.24 30 0.3678
0.1167 196 12.0 24 0.3667
0.2617 185 24.46 27 0.3189
0.1994 188 20.06 27 0.4187
0.1706 170 17.0 25 0.5059
0.1554 183 11.58 24 0.3195
0.2282 185 10.08 24 0.2381
0.1778 185 18.56 23 0.2802
0.1863 185 11.81 23 0.381
0.1014 193 13.81 32 0.1593
代碼如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
# -*- coding: utf-8 -*-
"""
By: Eastmount CSDN 2016-10-12
該部分講數(shù)據(jù)集讀取,然后賦值給X變量
讀取文件data.txt 保存結(jié)果為X
"""
import os
data = []
for line in open("data.txt", "r").readlines():
line = line.rstrip() #刪除換行
#刪除多余空格���,保存一個(gè)空格連接
result = ' '.join(line.split())
#獲取每行五個(gè)值 '0 0.0888 201 36.02 28 0.5885' 注意:字符串轉(zhuǎn)換為浮點(diǎn)型數(shù)
s = [float(x) for x in result.strip().split(' ')]
#輸出結(jié)果:['0', '0.0888', '201', '36.02', '28', '0.5885']
print s
#數(shù)據(jù)存儲(chǔ)至data
data.append(s)
#輸出完整數(shù)據(jù)集
print u'完整數(shù)據(jù)集'
print data
print type(data)
'''''
現(xiàn)在輸出數(shù)據(jù)集:
['0 0.0888 201 36.02 28 0.5885',
'1 0.1399 198 39.32 30 0.8291',
'2 0.0747 198 38.80 26 0.4974',
'3 0.0983 191 40.71 30 0.5772',
'4 0.1276 196 38.40 28 0.5703'
]
'''
print u'第一列 第五列數(shù)據(jù)'
L2 = [n[0] for n in data]
print L2
L5 = [n[4] for n in data]
print L5
'''''
X表示二維矩陣數(shù)據(jù)�����,籃球運(yùn)動(dòng)員比賽數(shù)據(jù)
總共96行��,每行獲取兩列數(shù)據(jù)
第一列表示球員每分鐘助攻數(shù):assists_per_minute
第五列表示球員每分鐘得分?jǐn)?shù):points_per_minute
'''
#兩列數(shù)據(jù)生成二維數(shù)據(jù)
print u'兩列數(shù)據(jù)合并成二維矩陣'
T = dict(zip(L2,L5))
type(T)
#dict類型轉(zhuǎn)換為list
print u'List'
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
print X
print type(X)
"""
KMeans聚類
clf = KMeans(n_clusters=3) 表示類簇?cái)?shù)為3��,聚成3類數(shù)據(jù)����,clf即賦值為KMeans
y_pred = clf.fit_predict(X) 載入數(shù)據(jù)集X����,并且將聚類的結(jié)果賦值給y_pred
"""
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
#輸出聚類預(yù)測(cè)結(jié)果,96行數(shù)據(jù)�,每個(gè)y_pred對(duì)應(yīng)X一行或一個(gè)球員,聚成3類����,類標(biāo)為0����、1�����、2
print(y_pred)
"""
可視化繪圖
Python導(dǎo)入Matplotlib包���,專門用于繪圖
import matplotlib.pyplot as plt 此處as相當(dāng)于重命名�,plt用于顯示圖像
"""
import numpy as np
import matplotlib.pyplot as plt
#獲取第一列和第二列數(shù)據(jù) 使用for循環(huán)獲取 n[0]表示X第一列
x = [n[0] for n in X]
print x
y = [n[1] for n in X]
print y
#繪制散點(diǎn)圖 參數(shù):x橫軸 y縱軸 c=y_pred聚類預(yù)測(cè)結(jié)果 marker類型 o表示圓點(diǎn) *表示星型 x表示點(diǎn)
#plt.scatter(x, y, c=y_pred, marker='x')
#坐標(biāo)
x1 = []
y1 = []
x2 = []
y2 = []
x3 = []
y3 = []
#分布獲取類標(biāo)為0����、1、2的數(shù)據(jù) 賦值給(x1,y1) (x2,y2) (x3,y3)
i = 0
while i < len(X):
if y_pred[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_pred[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_pred[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
#四種顏色 紅 綠 藍(lán) 黑
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
#繪制標(biāo)題
plt.title("Kmeans-Basketball Data")
#繪制x軸和y軸坐標(biāo)
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
#設(shè)置右上角圖例
plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10)
plt.show()
輸出結(jié)果如下圖所示:三個(gè)層次很明顯��,而且右上角也標(biāo)注����。
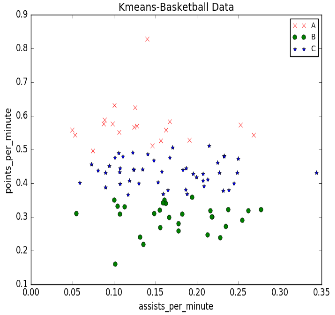
可視化部分強(qiáng)烈推薦資料:
數(shù)字的可視化:python畫圖之散點(diǎn)圖sactter函數(shù)詳解 - hefei_cyp
python 科學(xué)計(jì)算(一) - bovine
Matplotlib scatter plot with legend - stackoverflow
Python數(shù)據(jù)可視化——散點(diǎn)圖 Rachel-Zhang(按評(píng)論修改代碼)
四. Spyder常見(jiàn)問(wèn)題
下面是常見(jiàn)遇到的幾個(gè)問(wèn)題:
1.Spyder軟件如果Editor編輯框不在,如何調(diào)出來(lái)���。
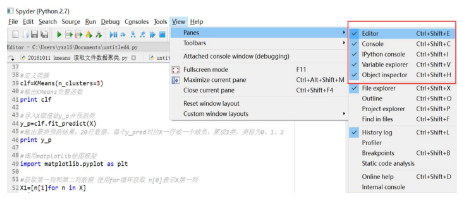
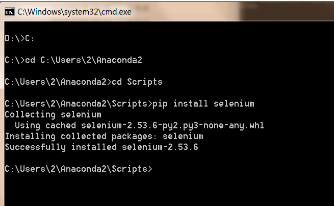
2.會(huì)缺少一些第三方包��,如lda���,如何導(dǎo)入。使用cd ..去到C盤根目錄����,cd去到Anaconda的Scripts目錄下,輸入"pip install selenium"安裝selenium相應(yīng)的包��,"pip install lda"安裝lda包����。
學(xué)生告訴我另一個(gè)更方便的方法:
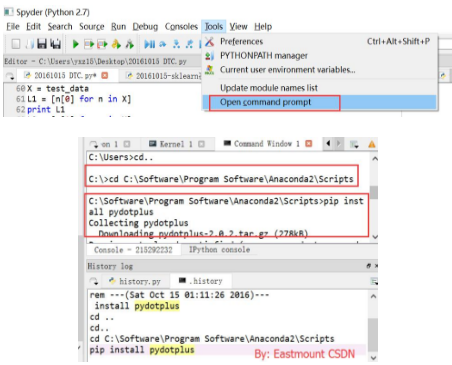
3.運(yùn)行時(shí)報(bào)錯(cuò),缺少Console����,點(diǎn)擊如下。
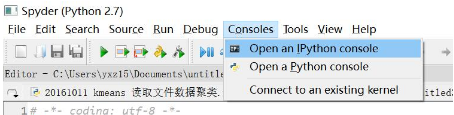
4.如果Spyder安裝點(diǎn)擊沒(méi)有反應(yīng)��,重新安裝也沒(méi)有反應(yīng)����,建議在運(yùn)行下試試。
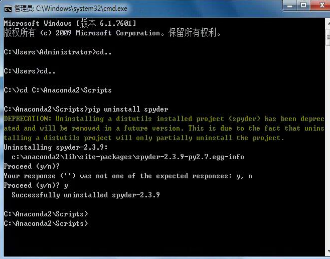
實(shí)在不行卸載再重裝:pip uninstall spyder
pip install spyder
5.Spyder如何顯示繪制Matplotlib中文��。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="C:\Windows\Fonts/msyh.ttf", size=10)
#繪制標(biāo)題 fontproperties表示字體類型,用于顯示中文字符���,下同
plt.title(u'世界各國(guó)家人均面積與土地面積',fontproperties=font)
#繪制x軸和y軸坐標(biāo)
plt.ylabel(u'人均面積(人/ 平方公里)',fontproperties=font)
plt.xlabel(u'面積(萬(wàn)平方公里)',fontproperties=font)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330