數(shù)到數(shù)據(jù)挖掘���,大家肯定會(huì)聯(lián)想到數(shù)據(jù)分析��。數(shù)據(jù)挖掘與數(shù)據(jù)分析兩者各有交叉�����,無須區(qū)分太明顯�����,但兩者側(cè)重點(diǎn)不同����,我們一定要根據(jù)自身特點(diǎn)來選擇數(shù)據(jù)挖掘培訓(xùn)或數(shù)據(jù)分析培訓(xùn)����。不過說到數(shù)據(jù)挖掘培訓(xùn),我們還是要先具備一定的知識(shí)儲(chǔ)備的��,不然一上來老師講課���,你可能連最基礎(chǔ)的計(jì)算機(jī)知識(shí)或統(tǒng)計(jì)學(xué)知識(shí)都一頭霧水���,那你還怎么學(xué)得下去。下面���,根據(jù)數(shù)據(jù)挖掘培訓(xùn)的特點(diǎn)���,小編給大家講講數(shù)據(jù)挖掘的常用方法���、功能及其應(yīng)用實(shí)例,讓大家對數(shù)據(jù)挖掘有個(gè)更加系統(tǒng)專業(yè)的了解�,也看看自己是否真的喜歡數(shù)據(jù)挖掘。
.jpg")
數(shù)據(jù)挖掘的功能
數(shù)據(jù)挖掘通過預(yù)測未來趨勢及行為�,做出前攝的、基于知識(shí)的決策����。數(shù)據(jù)挖掘的目標(biāo)是從數(shù)據(jù)庫中發(fā)現(xiàn)隱含的、有意義的知識(shí)����,主要有以下五類功能。
自動(dòng)預(yù)測趨勢和行為:數(shù)據(jù)挖掘自動(dòng)在大型數(shù)據(jù)庫中尋找預(yù)測性信息�����,以往需要進(jìn)行大量手工分析的問題如今可以迅速直接由數(shù)據(jù)本身得出結(jié)論����。一個(gè)典型的例子是市場預(yù)測問題�����,數(shù)據(jù)挖掘使用過去有關(guān)促銷的數(shù)據(jù)來尋找未來投資中回報(bào)最大的用戶,其它可預(yù)測的問題包括預(yù)報(bào)破產(chǎn)以及認(rèn)定對指定事件最可能做出反應(yīng)的群體�。
關(guān)聯(lián)分析:數(shù)據(jù)關(guān)聯(lián)是數(shù)據(jù)庫中存在的一類重要的可被發(fā)現(xiàn)的知識(shí)。若兩個(gè)或多個(gè)變量的取值之間存在某種規(guī)律性����,就稱為關(guān)聯(lián)。關(guān)聯(lián)可分為簡單關(guān)聯(lián)�、時(shí)序關(guān)聯(lián)、因果關(guān)聯(lián)�����。關(guān)聯(lián)分析的目的是找出數(shù)據(jù)庫中隱藏的關(guān)聯(lián)網(wǎng)��。有時(shí)并不知道數(shù)據(jù)庫中數(shù)據(jù)的關(guān)聯(lián)函數(shù)��,即使知道也是不確定的�,因此關(guān)聯(lián)分析生成的規(guī)則帶有可信度。
聚類:數(shù)據(jù)庫中的記錄可被化分為一系列有意義的子集����,即聚類���。聚類增強(qiáng)了人們對客觀現(xiàn)實(shí)的認(rèn)識(shí),是概念描述和偏差分析的先決條件����。聚類技術(shù)主要包括傳統(tǒng)的模式識(shí)別方法和數(shù)學(xué)分類學(xué)。80年代初�,Michalski提出了概念聚類技術(shù),其要點(diǎn)是�,在劃分對象時(shí)不僅考慮對象之間的距離,還要求劃分出的類具有某種內(nèi)涵描述����,從而避免了傳統(tǒng)技術(shù)的某些片面性。
概念描述:概念描述就是對某類對象的內(nèi)涵進(jìn)行描述����,并概括這類對象的有關(guān)特征。概念描述分為特征性描述和區(qū)別性描述�,前者描述某類對象的共同特征,后者描述不同類對象之間的區(qū)別���。生成一個(gè)類的特征性描述只涉及該類對象中所有對象的共性���。生成區(qū)別性描述的方法很多�,如決策樹方法���、遺傳算法等��。
偏差檢測:數(shù)據(jù)庫中的數(shù)據(jù)常有一些異常記錄,從數(shù)據(jù)庫中檢測這些偏差很有意義����。偏差包括很多潛在的知識(shí),如分類中的反常實(shí)例��、不滿足規(guī)則的特例�����、觀測結(jié)果與模型預(yù)測值的偏差��、量值隨時(shí)間的變化等��。偏差檢測的基本方法是�,尋找觀測結(jié)果與參照值之間有意義的差別。
數(shù)據(jù)挖掘的常用方法
利用數(shù)據(jù)挖掘進(jìn)行數(shù)據(jù)分析常用的方法主要有分類����、回歸分析����、聚類���、關(guān)聯(lián)規(guī)則�����、特征����、變化和偏差分析�����、Web頁挖掘等����,它們分別從不同的角度對數(shù)據(jù)進(jìn)行挖掘。
分類��。分類是找出數(shù)據(jù)庫中一組數(shù)據(jù)對象的共同特點(diǎn)并按照分類模式將其劃分為不同的類���,其目的是通過分類模型���,將數(shù)據(jù)庫中的數(shù)據(jù)項(xiàng)映射到某個(gè)給定的類別���。它可以應(yīng)用到客戶的分類、客戶的屬性和特征分析�、客戶滿意度分析、客戶的購買趨勢預(yù)測等�����,如一個(gè)汽車零售商將客戶按照對汽車的喜好劃分成不同的類��,這樣營銷人員就可以將新型汽車的廣告手冊直接郵寄到有這種喜好的客戶手中���,從而大大增加了商業(yè)機(jī)會(huì)。
回歸分析����。回歸分析方法反映的是事務(wù)數(shù)據(jù)庫中屬性值在時(shí)間上的特征,產(chǎn)生一個(gè)將數(shù)據(jù)項(xiàng)映射到一個(gè)實(shí)值預(yù)測變量的函數(shù)�����,發(fā)現(xiàn)變量或?qū)傩蚤g的依賴關(guān)系,其主要研究問題包括數(shù)據(jù)序列的趨勢特征�����、數(shù)據(jù)序列的預(yù)測以及數(shù)據(jù)間的相關(guān)關(guān)系等�����。它可以應(yīng)用到市場營銷的各個(gè)方面���,如客戶尋求���、保持和預(yù)防客戶流失活動(dòng)、產(chǎn)品生命周期分析����、銷售趨勢預(yù)測及有針對性的促銷活動(dòng)等。
聚類����。聚類分析是把一組數(shù)據(jù)按照相似性和差異性分為幾個(gè)類別,其目的是使得屬于同一類別的數(shù)據(jù)間的相似性盡可能大���,不同類別中的數(shù)據(jù)間的相似性盡可能小����。它可以應(yīng)用到客戶群體的分類、客戶背景分析��、客戶購買趨勢預(yù)測�����、市場的細(xì)分等��。

關(guān)聯(lián)規(guī)則��。關(guān)聯(lián)規(guī)則是描述數(shù)據(jù)庫中數(shù)據(jù)項(xiàng)之間所存在的關(guān)系的規(guī)則��,即根據(jù)一個(gè)事務(wù)中某些項(xiàng)的出現(xiàn)可導(dǎo)出另一些項(xiàng)在同一事務(wù)中也出現(xiàn)����,即隱藏在數(shù)據(jù)間的關(guān)聯(lián)或相互關(guān)系��。在客戶關(guān)系管理中��,通過對企業(yè)的客戶數(shù)據(jù)庫里的大量數(shù)據(jù)進(jìn)行挖掘�,可以從大量的記錄中發(fā)現(xiàn)有趣的關(guān)聯(lián)關(guān)系,找出影響市場營銷效果的關(guān)鍵因素���,為產(chǎn)品定位��、定價(jià)與定制客戶群����,客戶尋求、細(xì)分與保持���,市場營銷與推銷��,營銷風(fēng)險(xiǎn)評估和詐騙預(yù)測等決策支持提供參考依據(jù)�。
特征�。特征分析是從數(shù)據(jù)庫中的一組數(shù)據(jù)中提取出關(guān)于這些數(shù)據(jù)的特征式,這些特征式表達(dá)了該數(shù)據(jù)集的總體特征���。如營銷人員通過對客戶流失因素的特征提取��,可以得到導(dǎo)致客戶流失的一系列原因和主要特征���,利用這些特征可以有效地預(yù)防客戶的流失。
變化和偏差分析�。偏差包括很大一類潛在有趣的知識(shí),如分類中的反常實(shí)例�,模式的例外����,觀察結(jié)果對期望的偏差等��,其目的是尋找觀察結(jié)果與參照量之間有意義的差別����。在企業(yè)危機(jī)管理及其預(yù)警中,管理者更感興趣的是那些意外規(guī)則��。意外規(guī)則的挖掘可以應(yīng)用到各種異常信息的發(fā)現(xiàn)�����、分析����、識(shí)別、評價(jià)和預(yù)警等方面���。
Web頁挖掘。隨著Internet的迅速發(fā)展及Web 的全球普及����, 使得Web上的信息量無比豐富�,通過對Web的挖掘����,可以利用Web 的海量數(shù)據(jù)進(jìn)行分析,收集政治���、經(jīng)濟(jì)����、政策���、科技��、金融�、各種市場��、競爭對手�����、供求信息��、客戶等有關(guān)的信息�����,集中精力分析和處理那些對企業(yè)有重大或潛在重大影響的外部環(huán)境信息和內(nèi)部經(jīng)營信息,并根據(jù)分析結(jié)果找出企業(yè)管理過程中出現(xiàn)的各種問題和可能引起危機(jī)的先兆���,對這些信息進(jìn)行分析和處理�,以便識(shí)別���、分析���、評價(jià)和管理危機(jī)。
數(shù)據(jù)挖掘的應(yīng)用實(shí)例:聚類分析應(yīng)用之市場細(xì)分
聚類是將數(shù)據(jù)分類到不同的類或者簇這樣的一個(gè)過程�,所以同一個(gè)簇中的對象有很大的相似性,而不同簇間的對象有很大的相異性���。
從統(tǒng)計(jì)學(xué)的觀點(diǎn)看���,聚類分析是通過數(shù)據(jù)建模簡化數(shù)據(jù)的一種方法。傳統(tǒng)的統(tǒng)計(jì)聚類分析方法包括系統(tǒng)聚類法�����、分解法��、加入法�����、動(dòng)態(tài)聚類法��、有序樣品聚類��、有重疊聚類和模糊聚類等�����。
從機(jī)器學(xué)習(xí)的角度講���,簇相當(dāng)于隱藏模式����。聚類是搜索簇的無監(jiān)督學(xué)習(xí)過程����。與分類不同,無監(jiān)督學(xué)習(xí)不依賴預(yù)先定義的類或帶類標(biāo)記的訓(xùn)練實(shí)例����,需要由聚類學(xué)習(xí)算法自動(dòng)確定標(biāo)記����,而分類學(xué)習(xí)的實(shí)例或數(shù)據(jù)對象有類別標(biāo)記�。聚類是觀察式學(xué)習(xí),而不是示例式的學(xué)習(xí)�。
從實(shí)際應(yīng)用的角度看,聚類分析是數(shù)據(jù)挖掘的主要任務(wù)之一��。而且聚類能夠作為一個(gè)獨(dú)立的工具獲得數(shù)據(jù)的分布狀況�����,觀察每一簇?cái)?shù)據(jù)的特征���,集中對特定的聚簇集合作進(jìn)一步地分析��。聚類分析還可以作為其他算法(如分類和定性歸納算法)的預(yù)處理步驟���。
聚類分析的核心思想就是物以類聚,人以群分�。在市場細(xì)分領(lǐng)域,消費(fèi)同一種類的商品或服務(wù)時(shí)����,不同的客戶有不同的消費(fèi)特點(diǎn)�����,通過研究這些特點(diǎn),企業(yè)可以制定出不同的營銷組合���,從而獲取最大的消費(fèi)者剩余�����,這就是客戶細(xì)分的主要目的���。在銷售片區(qū)劃分中,只有合理地將企業(yè)所擁有的子市場歸成幾個(gè)大的片區(qū)�����,才能有效地制定符合片區(qū)特點(diǎn)的市場營銷戰(zhàn)略和策略��。金融領(lǐng)域����,對基金或者股票進(jìn)行分類,以選擇分類投資風(fēng)險(xiǎn)。
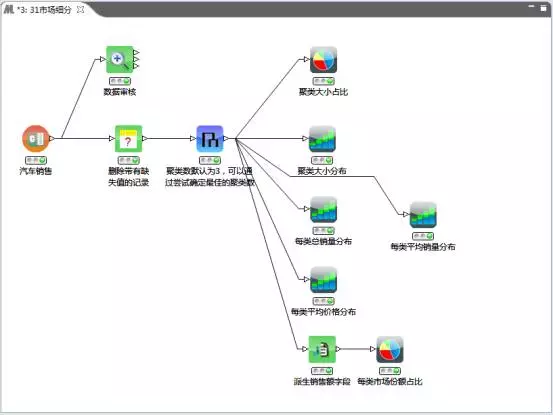
下面以一個(gè)汽車銷售的案例來介紹聚類分析在市場細(xì)分中的應(yīng)用�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330