SPSS操作:輕松實(shí)現(xiàn)1:1傾向性評(píng)分匹配(PSM)
談起臨床研究�����,如何設(shè)立一個(gè)靠譜的對(duì)照,有時(shí)候成為整個(gè)研究成敗的關(guān)鍵����。對(duì)照設(shè)立的一個(gè)非常重要的原則就是可比性,簡(jiǎn)單說(shuō)就是對(duì)照組除了研究因素外����,其他的因素應(yīng)該盡可能和試驗(yàn)組保持一致,這里就不得不提隨機(jī)對(duì)照試驗(yàn)��。眾所周知�����,隨機(jī)對(duì)照試驗(yàn)中研究對(duì)象是否接受干預(yù)是隨機(jī)的��,這就保證了組間其他混雜因素均衡可比��。
但是有些時(shí)候并不能實(shí)現(xiàn)隨機(jī)化��,比如說(shuō)觀察性研究����。這時(shí)候傾向性評(píng)分匹配(propensity score matching, PSM)可以有效降低混雜偏倚,并且在整個(gè)研究設(shè)計(jì)階段,得到類似隨機(jī)對(duì)照研究的效果�����,想看實(shí)例趕快戳:隊(duì)列研究常用的傾向評(píng)分��,到底是個(gè)啥����?。與常規(guī)匹配相比��,傾向性評(píng)分匹配能考慮更多匹配因素�����,提高研究效率��。
這么“高大上”的傾向性評(píng)分匹配���,是不是超級(jí)難學(xué)�?錯(cuò)矣��!今天就帶大家輕松搞定1:1傾向性評(píng)分匹配�。作為“稀罕”大招,并不是在所有版本的SPSS都可以實(shí)現(xiàn)傾向性評(píng)分匹配���,僅在SPSS22及以上自帶簡(jiǎn)易版PSM����,對(duì)于其他版本或者想要體驗(yàn)完整版功能����,就不得不去安裝相應(yīng)的軟件(R軟件、SPSS R插件�、PS matching插件。�。。超級(jí)難安裝�!那是需要運(yùn)氣和耐心的��!感興趣的小伙伴可以私聊~~~)。
本次使用SPSS22為大家演示1:1傾向性評(píng)分匹配。
一�����、問(wèn)題與數(shù)據(jù)
某研究小白想搞明白吸煙和高血壓之間的關(guān)系,準(zhǔn)備利用某項(xiàng)調(diào)查的資料進(jìn)一步隨訪研究吸煙和高血壓的關(guān)聯(lián)���,該項(xiàng)研究包括233名吸煙者��,949 名不吸煙者��。如果全部隨訪���,研究小白感覺(jué)鴨梨山大�����,所以打算從中選取部分可比的個(gè)體進(jìn)行隨訪�。
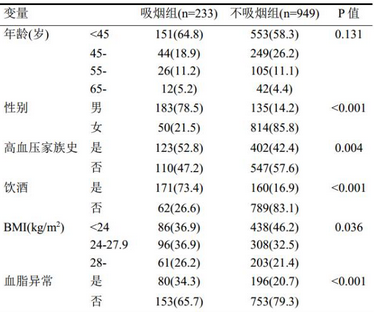
這兩組人群一些主要特征的分布存在顯著差異(見(jiàn)表1)�,現(xiàn)準(zhǔn)備采用PS最鄰近匹配法選取可比的個(gè)體作為隨訪對(duì)象。
表1. 兩組基線情況比較(匹配前)
二、SPSS分析方法
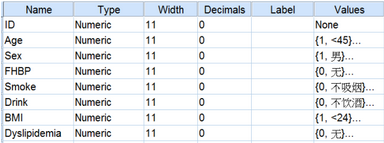
1. 數(shù)據(jù)錄入
(1) 變量視圖
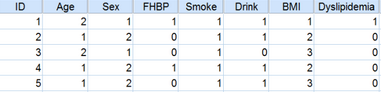
(2) 數(shù)據(jù)視圖
2. 傾向性評(píng)分匹配
選擇Data→Propensity Score Matching����,就進(jìn)入傾向性評(píng)分匹配的主對(duì)話框。
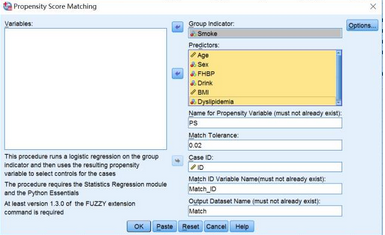
將分組變量Smoke放入Group Indicator中(一般處理組賦值為“1”�����,對(duì)照組賦值為“0”);將需要匹配的變量放入Predictors中���;Name for Propensity Variable為傾向性評(píng)分設(shè)定一個(gè)變量名PS�����;
Match
Tolerance用來(lái)設(shè)置傾向性評(píng)分匹配標(biāo)準(zhǔn)(學(xué)名“卡鉗值”)���,這里設(shè)定為0.02,即吸煙組和不吸煙組按照傾向性評(píng)分±0.02進(jìn)行1:1匹配(當(dāng)然���,卡鉗值設(shè)置的越小�,吸煙組和不吸煙組匹配后可比性越好����,但是凡事有個(gè)度���,太小的卡鉗值也意味著匹配難度會(huì)加大����,成功匹配的對(duì)子數(shù)會(huì)減少�,需要綜合考慮~~~)�����;
Case ID確定觀測(cè)對(duì)象的ID;Match ID Variable Name設(shè)定一個(gè)變量,用來(lái)明確對(duì)照組中匹配成功的Match_ID��;Output Dataset Name這里把匹配的觀測(cè)對(duì)象單獨(dú)輸出一個(gè)數(shù)據(jù)集Match。
3. Options設(shè)置
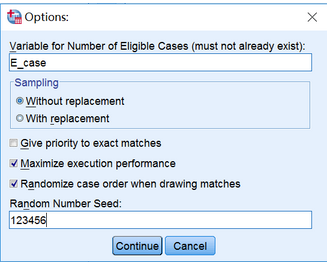
Variable for Number of Eligible Cases設(shè)定一個(gè)變量����,用來(lái)明確病例組中某一個(gè)觀測(cè)對(duì)象����,在對(duì)照組中有多少個(gè)觀測(cè)對(duì)象滿足與其匹配的條件���,比如說(shuō)病例組有一個(gè)觀測(cè)對(duì)象PS=0.611�,對(duì)照組可能有一個(gè)0.610,一個(gè)0.612���。
Sampling默認(rèn)為不放回抽樣。
Give priority to exact matches 優(yōu)先考慮精確匹配����,也就說(shuō)病例組有一個(gè)觀測(cè)對(duì)象PS=0.611��,對(duì)照組也應(yīng)該找到一個(gè)0.611�����。
Maximize execution performance 執(zhí)行最優(yōu)化操作�,即系統(tǒng)會(huì)綜合考慮精確匹配和模糊匹配(基于設(shè)定的卡鉗值范圍內(nèi)匹配),系統(tǒng)默認(rèn)勾選����。
Randomize
case order when drawing
matches整個(gè)匹配過(guò)程中,如果對(duì)照組有多個(gè)滿足匹配條件的觀測(cè)對(duì)象���,那么SPSS會(huì)默認(rèn)隨機(jī)將其與病例組觀測(cè)對(duì)象匹配�。但是因?yàn)镾PSS默認(rèn)每次操作給對(duì)照組的隨機(jī)數(shù)字不同,所以如果不特殊設(shè)定���,每次實(shí)際匹配成功的對(duì)子是不一樣的,也就說(shuō)這一次對(duì)照組A匹配給病例組B�����,下一次就可能匹配給病例組C��。所以需要自行設(shè)置��,并且在Random
Number Seed設(shè)定一個(gè)隨機(jī)數(shù)種子���,確保匹配過(guò)程可以重復(fù)��。
三����、結(jié)果解讀
1. 匹配結(jié)果
表2以吸煙(1=吸煙��;0=不吸煙)為因變量�����,以需要調(diào)整的變量為自變量構(gòu)建logistic回歸模型(表2),求出每個(gè)研究對(duì)象的PS值���。
表2. logistic回歸模型
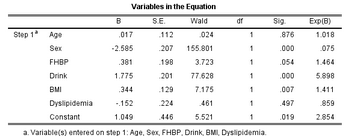
表3顯示����,精確匹配45對(duì)��,模糊匹配114對(duì)����,共計(jì)匹配成功159對(duì)�����。
表3. 匹配結(jié)果

表4主要是匹配過(guò)程�����。首先是精確匹配(即PS完全一致),匹配33663次�����,大約1%匹配成功;其次在精確匹配成功的前提下����,進(jìn)行PS的模糊匹配(PS±0.02�����,即最開(kāi)始設(shè)定的卡鉗值為0.02)����,匹配33618次�����,大約3.3%匹配成功�����。
表4. 匹配容許誤差

2. 匹配后數(shù)據(jù)庫(kù)
輸出的數(shù)據(jù)集Match中出現(xiàn)之前設(shè)定的幾個(gè)新變量:E_case表示對(duì)照組中有幾個(gè)符合匹配條件的觀測(cè)對(duì)象(如圖,吸煙組ID=2�����,有2個(gè)對(duì)照組觀測(cè)對(duì)象符合匹配條件);PS是基于logistic回歸模型計(jì)算出的傾向性評(píng)分�;match_id表示匹配成功的ID。

3. 數(shù)據(jù)庫(kù)整理
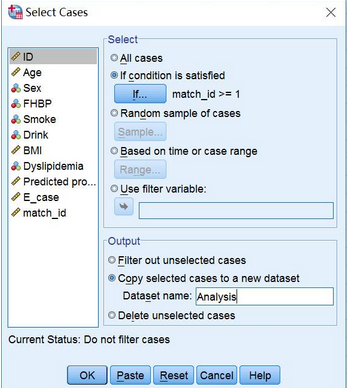
A. 篩選匹配成功的對(duì)子:選擇Data→Select Cases→If condition is satisfied:設(shè)定match_id≥1�����,篩選出匹配成功的對(duì)子→Output中輸出新的數(shù)據(jù)集Analysis�。
B.
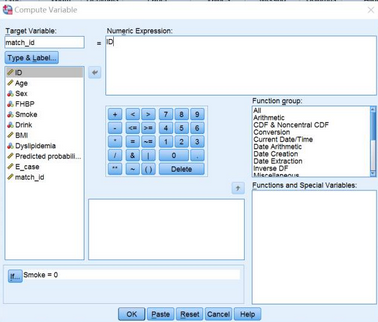
確定匹配成功標(biāo)識(shí):match_id為吸煙組和不吸煙組相互匹配成功的ID,這里將不吸煙組match_id變量轉(zhuǎn)換為ID變量��,這時(shí)候相同的match_id即為匹配成功的對(duì)子�。具體操作:將Analysis數(shù)據(jù)集中,不吸煙組match_id替換成ID編號(hào):Transform→Compute
Variable→if smoke=0, match_id=ID→OK
C. 選擇Data→Sort cases→按照匹配標(biāo)識(shí)match_id排序(相同的match_id即為匹配成功的對(duì)子)→OK→Save(你的鼠標(biāo)手一定要點(diǎn)保存?���。�����。�。?
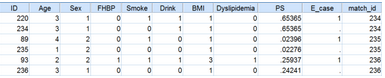
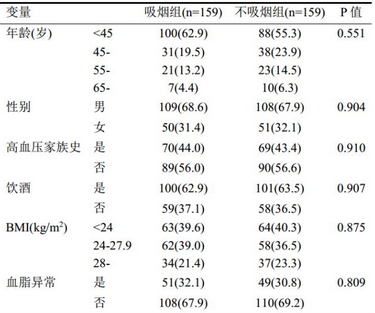
傾向性評(píng)分匹配就搞定了����,再來(lái)看看匹配情況���。表5顯示,原吸煙組233例�����,最后共有159例匹配成功(這次我們限定PS≤0.02���,但可根據(jù)實(shí)際情況選擇合適的限定�,增加匹配成功數(shù)?��。?����,各匹配因素在兩組間都均衡可比����。
表5. 兩組基線情況比較(匹配后)
四���、總結(jié)和拓展
PSM一般分為三種類型:
1���、PS最鄰近匹配:是PSM最基本的方法��,即直接從對(duì)照中尋找一個(gè)或多個(gè)與處理組個(gè)體PS值相同或相近的個(gè)體作為配比對(duì)象�。本次我們就采用的是這個(gè)方法��。
2�、分層PSM:PS最鄰近匹配盡管可以使協(xié)變量總體趨于平衡,但不能保證每個(gè)協(xié)變量分布完全一致�。可以根據(jù)某個(gè)重要變量(如性別)分層后���,分別對(duì)每層人群進(jìn)行PS最鄰近匹配��,然后再將配比人群合并���,這樣就可以保證該重要變量在組間分布完全一致。
3�、與馬氏配比結(jié)合的PSM:PSM與馬氏配比結(jié)合后可以增加個(gè)別重點(diǎn)變量平衡能力,實(shí)現(xiàn)過(guò)程比較復(fù)雜�����。
對(duì)于1:m PS匹配和與馬氏配比結(jié)合的PSM����,目前SPSS22及以上版本自帶的PSM并不能實(shí)現(xiàn),后面會(huì)介紹基于SAS軟件復(fù)雜傾向性評(píng)分匹配���,敬請(qǐng)期待~~~
想深入學(xué)習(xí)統(tǒng)計(jì)學(xué)知識(shí)�����,為數(shù)據(jù)分析筑牢根基���?那快來(lái)看看統(tǒng)計(jì)學(xué)極簡(jiǎn)入門(mén)課程!

學(xué)習(xí)入口:https://edu.cda.cn/goods/show/3386?targetId=5647&preview=0
課程由專業(yè)數(shù)據(jù)分析師打造�,完全免費(fèi),60 天有效期且隨到隨學(xué)�。它用獨(dú)特思路講重點(diǎn),從數(shù)據(jù)種類到統(tǒng)計(jì)學(xué)體系��,內(nèi)容通俗易懂��。學(xué)完它�����,能讓你輕松入門(mén)統(tǒng)計(jì)學(xué)���,還能提升數(shù)據(jù)分析能力����。趕緊點(diǎn)擊鏈接開(kāi)啟學(xué)習(xí),讓自己在數(shù)據(jù)領(lǐng)域更上一層樓�!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330