在文本分類(lèi)����,垃圾郵件過(guò)濾的場(chǎng)景中,我們經(jīng)常會(huì)用到的是樸素貝葉斯算法����,今天小編就具體給大家介紹一下樸素貝葉斯算法
一、樸素貝葉斯算法簡(jiǎn)介
1.樸素貝葉斯算法概念
樸素貝葉斯法是基于貝葉斯定理與特征條件獨(dú)立假設(shè)的分類(lèi)方法����。樸素貝葉斯分類(lèi)器(Naive Bayes Classifier,或 NBC)發(fā)源于古典數(shù)學(xué)理論,有著堅(jiān)實(shí)的數(shù)學(xué)基礎(chǔ)��,以及穩(wěn)定的分類(lèi)效率����。
2.樸素貝葉斯算法優(yōu)缺點(diǎn)
優(yōu)點(diǎn):
(1)樸素貝葉斯模型發(fā)源于古典數(shù)學(xué)理論�����,分類(lèi)效率比較穩(wěn)定。
(2)對(duì)小規(guī)模的數(shù)據(jù)表現(xiàn)很好��,能夠用于多分類(lèi)任務(wù)的處理�,適合增量式訓(xùn)練,尤其是在數(shù)據(jù)量超出內(nèi)存的情況下�,能夠一批批的去增量訓(xùn)練。
(3)算法簡(jiǎn)單���,對(duì)缺失數(shù)據(jù)不太敏感�����。
缺點(diǎn):
(1)理論上�,樸素貝葉斯模型與其他分類(lèi)方法相比具有最小的誤差率�����。但是實(shí)際上并非總是如此�����,這是因?yàn)?a href='/map/pusubeiyesi/' style='color:#000;font-size:inherit;'>樸素貝葉斯模型假設(shè)屬性之間是相互獨(dú)立的,而這個(gè)假設(shè)在實(shí)際應(yīng)用中往往并不成立的���。雖然在屬性相關(guān)性較小時(shí)�����,樸素貝葉斯性能良好���。但是,在屬性個(gè)數(shù)比較多或者屬性之間相關(guān)性較大時(shí)���,分類(lèi)效果并不好��。
(2)需要知道先驗(yàn)概率�,并且先驗(yàn)概率在很多時(shí)候多是取決于假設(shè)�����,假設(shè)的模型可以有多種�����,從而導(dǎo)致在某些時(shí)候會(huì)由于假設(shè)的先驗(yàn)?zāi)P投沟妙A(yù)測(cè)效果不佳�����。
(3)因?yàn)槭峭ㄟ^(guò)先驗(yàn)和數(shù)據(jù)來(lái)決定后驗(yàn)的概率來(lái)決定分類(lèi)的,所以分類(lèi)決策存在一定的錯(cuò)誤率���。
(4)對(duì)輸入數(shù)據(jù)的表達(dá)形式很敏感����。
二�����、貝葉斯定理
既然���,樸素貝葉斯法是基于貝葉斯定理與特征條件獨(dú)立假設(shè)的分類(lèi)方法。那么接下來(lái)我們就來(lái)了解一下貝葉斯定理�����。
貝葉斯算法是英國(guó)數(shù)學(xué)家貝葉斯(約1701-1761)Thomas Bayes�,生前提出為解決“逆概”問(wèn)題而提出的。
條件概率就是事件 A 在另外一個(gè)事件 B 已經(jīng)發(fā)生條件下的發(fā)生概率���。條件概率表示為P(A|B)��,讀作“在 B 發(fā)生的條件下 A 發(fā)生的概率”���。
聯(lián)合概率表示兩個(gè)事件共同發(fā)生(數(shù)學(xué)概念上的交集)的概率�����。A 與 B 的聯(lián)合概率表示為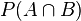
推導(dǎo):
從條件概率的定義推導(dǎo)出貝葉斯定理����。
根據(jù)條件概率的定義�,在事件 B 發(fā)生的條件下事件 A 發(fā)生的概率為:
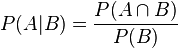
同樣道理,在事件 A 發(fā)生的條件下事件 B 發(fā)生的概率為:
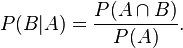
結(jié)合這兩個(gè)方程式�����,能夠得到:
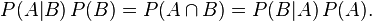
這個(gè)引理有時(shí)稱(chēng)作概率乘法規(guī)則�����。上式兩邊同除以 P(A)����,若P(A)是非零的,就能得到貝葉斯定理:
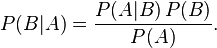
三�、python實(shí)現(xiàn)文本分類(lèi)
# 文本分類(lèi)器
import numpy as np
# 數(shù)據(jù)樣本
def loadDataSet():
# dataset = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
# # ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
# # ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'hime'],
# # ['stop', 'posting', 'stupid', 'worthless', 'garbage'],
# # ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
# # ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
dataset = [['玩', '游', '戲', '吧'],
['玩', 'lol', '吧'],
['我', '要', '學(xué)', '習(xí)'],
['學(xué)', '習(xí)', '使', '我', '快', '了'],
['學(xué)', '習(xí)', '萬(wàn)', '歲'],
['我', '要', '玩', '耍']]
label = [1, 1, 0, 0, 0, 1]
return dataset, label
# 獲取文檔中出現(xiàn)的不重復(fù)詞表
def createVocabList(dataset):
vocaset = set([]) # 用集合結(jié)構(gòu)得到不重復(fù)詞表
for document in dataset:
vocaset = vocaset | set(document) # 兩個(gè)集合的并集
return list(vocaset)
def setword(listvocaset, inputSet):
newVocaset = [0] * len(listvocaset)
for data in inputSet:
if data in listvocaset:
newVocaset[listvocaset.index(data)] = 1 # 如果文檔中的單詞在列表中���,則列表對(duì)應(yīng)索引元素變?yōu)?
return newVocaset
def train(listnewVocaset, label):
label = np.array(label)
numDocument = len(listnewVocaset) # 樣本總數(shù)
numWord = len(listnewVocaset[0]) # 詞表的大小
pInsult = np.sum(label) / float(numDocument)
p0num = np.ones(numWord) # 非侮辱詞匯
p1num = np.ones(numWord) # 侮辱詞匯
p0Denom = 2.0 # 拉普拉斯平滑
p1Denom = 2.0
for i in range(numDocument):
if label[i] == 1:
p1num += listnewVocaset[i]
p1Denom += 1
else:
p0num += listnewVocaset[i]
p0Denom += 1
# 取對(duì)數(shù)是為了防止因?yàn)樾?shù)連乘而造成向下溢出
p0 = np.log(p0num / p0Denom) # 屬于非侮辱性文檔的概率
p1 = np.log(p1num / p1Denom) # 屬于侮辱性文檔的概率
return p0, p1, pInsult
# 分類(lèi)函數(shù)
def classiyyNB(Inputdata, p0, p1, pInsult):
# 因?yàn)槿?duì)數(shù),因此連乘操作就變成了連續(xù)相加
p0vec = np.sum(Inputdata * p0) + np.log(pInsult)
p1vec = np.sum(Inputdata * p1) + np.log(1.0 - pInsult)
if p0vec > p1vec:
return 0
else:
return 1
def testingNB():
dataset, label = loadDataSet()
voast = createVocabList(dataset)
listnewVocaset = []
for listvocaset in dataset:
listnewVocaset.append(setword(voast, listvocaset))
p0, p1, pInsult = train(listnewVocaset, label)
Inputdata = ['玩', '一', '玩']
Inputdata = np.array(Inputdata)
Inputdata = setword(voast, Inputdata)
print("這句話(huà)對(duì)應(yīng)的分類(lèi)是:")
print(classiyyNB(Inputdata, p0, p1, pInsult))
testingNB()
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330