我的R語(yǔ)言小白之梯度上升和逐步回歸的結(jié)合使用
我們今天的主題通常在用sas擬合邏輯回歸模型的時(shí)候�,我們會(huì)使用逐步回歸�,最優(yōu)得分統(tǒng)計(jì)模型的等方法去擬合模型。而在接觸機(jī)器學(xué)習(xí)算法用R和python實(shí)踐之后�,我們會(huì)了解到梯度上升算法���,和梯度下降算法�。其實(shí)本質(zhì)上模型在擬合的時(shí)候用的就是最大似然估計(jì)來(lái)確定逐步回歸選出來(lái)的一個(gè)參數(shù)估計(jì)�����,但是這個(gè)過(guò)程你說(shuō)看不到,那么現(xiàn)在假設(shè)你過(guò)程你可以選擇�,就是你來(lái)算這個(gè)最大似然估計(jì)的過(guò)程���。甚至,你可以定義這個(gè)過(guò)程損失函數(shù)����,那么就要使用最大似然估計(jì)����。
逐步回歸法結(jié)合了向前選擇法和向后選擇法的優(yōu)點(diǎn)。一開(kāi)始模型只有截距項(xiàng)���,先使用前向選擇法選入卡方統(tǒng)計(jì)量最大�,符合選入模型P值的變量��,然后使用后向選擇法移除P值最大的變量����,即最不顯著的變量����,不斷重復(fù)以上過(guò)程。所以也可以說(shuō)逐步回歸的每一步都結(jié)合了向前選擇法和向后選擇法����。
要學(xué)習(xí)梯度上升算法和梯度下降算法����,就要先了解梯度的概念���,要了解梯度就離不開(kāi)方向?qū)?shù)�����。學(xué)過(guò)大學(xué)微積分或數(shù)學(xué)分析的同學(xué)都知道�,導(dǎo)數(shù)代表了一個(gè)函數(shù)的變化率���。但當(dāng)一個(gè)函數(shù)包含多個(gè)自變量的時(shí)候����,函數(shù)值的變化不僅取決于自變量的變化�,還取決于使用哪個(gè)自變量。換句話說(shuō)���,函數(shù)值同時(shí)決定于移動(dòng)的距離和移動(dòng)的方向���。
然后��,梯度其實(shí)就是一定最大的方向?qū)?shù)�。在自變量只有一個(gè)的時(shí)候����,一點(diǎn)的導(dǎo)數(shù)其實(shí)是確定的。而到了多個(gè)自變量的時(shí)候���,以一個(gè)三維空間為例(如下圖的高山)����,概括為Y為X1�����,X2的函數(shù)�,那么在高山上的點(diǎn)上升的方向就不唯一,即方向?qū)?shù)不唯一�����,那么在某點(diǎn)上山最快的方向就可以描述為該點(diǎn)的梯度�����。在每爬到一個(gè)地方�����,就不斷調(diào)整上升最快的方向����,最終就可以爬到山頂,成為人生贏家����。在算法上就描述為每達(dá)到一個(gè)移動(dòng)的步長(zhǎng),就計(jì)算該點(diǎn)的梯度���,不斷使Y值增加�����,達(dá)到最大的Y�����,最后可以求得最優(yōu)的X1和X2���。
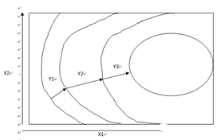
換到梯度下降法�����,就可以把三維圖形想象成一個(gè)碗����,要想到碗底的話�,就應(yīng)該沿下降最快的方向。數(shù)學(xué)上就是沒(méi)一步都求梯度的反方向���,最后目標(biāo)就是求Y的最小值����。
說(shuō)了這么多����,那么梯度上升法和下降法對(duì)邏輯回歸到底有什么用呢?邏輯回歸建模有一個(gè)目標(biāo)就是求解最優(yōu)的系數(shù)使似然函數(shù)最大化�����。而下降法可以用來(lái)是損失函數(shù)最小化�����。先說(shuō)似然函數(shù)最大化��,我們可以令模型的系數(shù)為剛才舉得例子的x1,x2即自變量����,那么我們就可以不斷迭代,找到最后的最大的似然函數(shù)和最佳的一組系數(shù)���。系數(shù)的梯度上升迭代式可以寫為,下面的α就是移動(dòng)的步長(zhǎng)����,所乘的就是梯度。
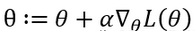
所以�,我們可以發(fā)現(xiàn)����,逐步回歸等算法其實(shí)優(yōu)化模型的入模變量���,梯度上升法是在選定入模變量之后��,求最佳的系數(shù)去優(yōu)化模型��。那么����,在實(shí)踐上我們就可以在sas擬合完模型�,選定變量后,在用R或者python用梯度上升法去求解最優(yōu)的系數(shù),但是需要明確一點(diǎn)嗎���,說(shuō)是最優(yōu)那是基于損失函數(shù)是一個(gè)凸函數(shù)�����,當(dāng)損失函數(shù)不是凸函數(shù)的時(shí)候,只是找到的是局部最優(yōu)����。L()這個(gè)函數(shù)是自己定義的一個(gè)損失函數(shù)組成的一個(gè)類似最大似然估計(jì)的一個(gè)函數(shù)��。
具體了解下�����,還是看不懂��,可以復(fù)習(xí)一下導(dǎo)數(shù),偏導(dǎo)數(shù)以及方向?qū)?shù)����。因?yàn)樘荻鹊膬?nèi)容實(shí)在有點(diǎn)多,所以還是希望大家對(duì)于梯度不了解的��,可以上網(wǎng)查詢了解�����。我最初想用這個(gè)的時(shí)候,我是在想一個(gè)問(wèn)題�����,就是假設(shè)我不用最大似然估計(jì)定義的損失函數(shù),假設(shè)我想用其他損失函數(shù)擬合參數(shù)����,那我該怎么辦��,所以才有了今天的分享���,可能我說(shuō)的優(yōu)點(diǎn)亂����,我給出梯度擬合參數(shù)的過(guò)程,你可能會(huì)清晰些:

那么作為R語(yǔ)言小白的我�,要出動(dòng)獻(xiàn)出我的梯度上升的代碼了,還是參考別人的更改�����,這里的數(shù)據(jù)集使用的是你逐步回歸選下來(lái)的變量��。這里這是重新擬合參數(shù)���,不適用你原來(lái)擬合的參數(shù)��,是不是很作,我也覺(jué)得我很作����。鏈接在這:http://blog.csdn.net/yuanhangzhegogo/article/details/40613951��。
D<-F[-which(names(F) %in% c('APPL_ID','APPL_STATUS_1'))]
# 為等下產(chǎn)生的樣本的矩陣做準(zhǔn)備,所以把主鍵還有因變量刪掉
Y=F$APPL_STATUS_1
# 將因變量單獨(dú)拿出來(lái)�����,等下要進(jìn)行運(yùn)算
m<-length(Y)
# 取出y的長(zhǎng)度�����,為的是等下構(gòu)造截距變量����,設(shè)為1
#自變量增加一列構(gòu)造矩陣
x1<-rep(1,m)
# 生成截距變量����,設(shè)為1
Y<-as.matrix(F$APPL_STATUS_1)
# 生成因變量的矩陣等下可以計(jì)算
X<-as.matrix(data.frame(x1,D))
#生成自變量矩陣��,等下計(jì)算
maxiteration=2000
#設(shè)定迭代次數(shù)
theta<-matrix(rep(0,14),ncol=1)
# 設(shè)置初始的系數(shù)
#設(shè)定學(xué)習(xí)速度
alpha=0.0001
pred<-data.frame()
# 生成一個(gè)空表
for ( n in c(1:maxiteration)){
#計(jì)算梯度
p<-1/(1+exp(-X%*%theta))
#計(jì)算通過(guò)填入?yún)?shù)之后的預(yù)測(cè)概率
grad=t(X)%*%(Y-p)
#放入公式計(jì)算
a<-theta
# 把前一個(gè)的參數(shù)矩陣賦給a
theta=theta+alpha*grad
# 計(jì)算梯度上升的一個(gè)參數(shù)
interval<-theta-a
# 計(jì)算之間的差值
dd<-data.frame(interval,sum=sum(interval),theta)
# 合并差值����,差值的累計(jì),以及對(duì)應(yīng)的參數(shù)
pred<-rbind(pred,dd)
# 縱向合并每一次迭代的數(shù)據(jù)
print(n)
# 打印迭代到哪里,好檢查錯(cuò)誤以及進(jìn)度
}
出來(lái)的結(jié)果看數(shù)據(jù)集看pred:
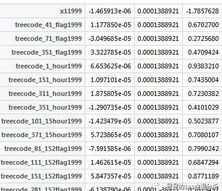
最后一列是參數(shù)估計(jì)�,中間是兩次梯度相減的累加,可以看到迭代了2000次之后�����,他的差距已經(jīng)很小很小的,基本可以斷定快到山頂了��,你要是覺(jué)得這樣子差距還是讓你不滿意,你可以設(shè)置迭代次數(shù)到3000次���。第一列是兩個(gè)梯度的各個(gè)值的相減��,這是為了讓你看到迭代的過(guò)程該變量的權(quán)重的變小了還是變大了�。當(dāng)然你也可以更改我的代碼����,把他改成迭代到兩次相減的數(shù)小于你設(shè)置的數(shù)就停止�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330