悉數(shù)那些“巨型”數(shù)據(jù)倉庫
最早的商業(yè)列式數(shù)據(jù)庫是在1995年發(fā)布的Sybase
IQ,但是一直到1999年左右才慢慢穩(wěn)定到能夠投入生產(chǎn)環(huán)境。現(xiàn)在的大多數(shù)分析型數(shù)據(jù)庫都是在2003-2005年從Postgresql
分支出來的���。其中尤其是Vertica
為代表的列數(shù)據(jù)庫已經(jīng)在大規(guī)模數(shù)據(jù)倉庫環(huán)境中證明其特別為數(shù)據(jù)倉庫環(huán)境設(shè)計的思路在一些領(lǐng)域具有競爭優(yōu)勢�。這篇文章解釋介紹列式數(shù)據(jù)庫的幾大特點。
高效的儲存空間利用率
傳統(tǒng)的行式數(shù)據(jù)庫由于每個列的長度不一�����,為了預(yù)防更新的時候不至于出現(xiàn)一行數(shù)據(jù)跳到另一個block 上去, 所以往往會預(yù)留一些空間�����。而面向列的數(shù)據(jù)庫由于一開始就完全為分析而存在��,不需要考慮少量的更新問題�����,所以數(shù)據(jù)完全是密集儲存的��。
行式數(shù)據(jù)庫為了表明行的id 往往會有一個偽列rowid 的存在����。列式數(shù)據(jù)庫一般不會保存rowid.
列式數(shù)據(jù)庫由于其針對不同列的數(shù)據(jù)特征而發(fā)明的不同算法使其往往有比行式數(shù)據(jù)庫高的多的壓縮率,普通的行式數(shù)據(jù)庫一般壓縮率在3:1 到5:1
左右�,而列式數(shù)據(jù)庫的壓縮率一般在8:1到30:1 左右。(InfoBright 在特別應(yīng)用可以達到40:1 , Vertica
在特別應(yīng)用可以達到60:1 , 一般是這么高的壓縮率都是網(wǎng)絡(luò)流量相關(guān)的)
列式數(shù)據(jù)庫由于其特殊的IO 模型所以其數(shù)據(jù)執(zhí)行引擎一般不需要索引來完成大量的數(shù)據(jù)過濾任務(wù)(Sybase IQ 除外) .這又額外的減少了數(shù)據(jù)儲存的空間消耗����。
列式數(shù)據(jù)庫不需要物化視圖,行式數(shù)據(jù)庫為了減少IO
一般會有兩種物化視圖��,常用列的不聚合物化視圖和聚合的物化視圖。列式數(shù)據(jù)庫本身列是分散儲存所以不需要第一種��,而由于其他特性使其極為適合做普通聚合操作����。(另外一種物化視圖是不能實時刷新的,比如排名函數(shù)�,不規(guī)則連接connect
by 等等�,這部分列數(shù)據(jù)庫不包括。)
不可見索引
列式數(shù)據(jù)庫由于其數(shù)據(jù)的每一列都按照選擇性進行排序�����,所以并不需要行式數(shù)據(jù)庫里面的索引來減少IO 和更快的查找值的分布情況�����。如下圖所示:
當數(shù)據(jù)庫執(zhí)行引擎進行where 條件過濾的時候�。只要它發(fā)現(xiàn)任何一列的數(shù)據(jù)不滿足特定條件,整個block
的數(shù)據(jù)就都被丟棄����。最后初步的過濾只會掃描可能滿足條件的數(shù)據(jù)塊。

(from InfoBright : Blazing Queries Using an Open Source Columnar Database for High Performance Analytics and Reporting )
另外在已經(jīng)讀取了可能的數(shù)據(jù)塊之后����,對于類似age < 65 或 job = 'Axx'
的���,列式數(shù)據(jù)庫并不需要掃描完整個block,因為數(shù)據(jù)已經(jīng)排序了。如果讀到第一個age=66 或者 Job = 'Bxx'
的時候就會停止掃描了�。這相當與行式數(shù)據(jù)庫索引里的范圍掃描。[page]
數(shù)據(jù)迭代 (Tuple Iteration)
現(xiàn)在的多核CPU 提供的L2 緩存在短時間執(zhí)行同一個函數(shù)很多次的時候能更好的利用CPU 的二級緩存和多核并發(fā)的特性��。而行式數(shù)據(jù)庫由于其數(shù)據(jù)混在一起沒法對一個數(shù)組進行同一個簡單函數(shù)的調(diào)用�����,所以其執(zhí)行效率沒有列式數(shù)據(jù)庫高���。
壓縮算法
列式數(shù)據(jù)庫由于其每一列都是分開儲存的���。所以很容易針對每一列的特征運用不同的壓縮算法。常見的列式數(shù)據(jù)庫壓縮算法有Run
Length Encoding , Data Dictionary , Delta Compression , BitMap Index ,
LZO , Null Compression 等等���。根據(jù)不同的特征進行的壓縮效率從10W:1 到10:1
不等�。而且數(shù)據(jù)越大其壓縮效率的提升越為明顯�。
延遲物化
列式數(shù)據(jù)庫由于其特殊的執(zhí)行引擎,在數(shù)據(jù)中間過程運算的時候一般不需要解壓數(shù)據(jù)而是以指針代替運算,直到最后需要輸出完整的數(shù)據(jù)時��。
(from McKnight : Columnar Database : Data Does the Twist and Analytics Shout)
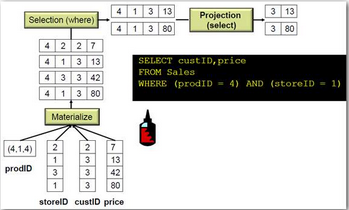
傳統(tǒng)的行式數(shù)據(jù)庫運算�, 在運算的一開始就解壓縮所有數(shù)據(jù),然后執(zhí)行后面的過濾���,投影��,連接��,聚合操作
而列式數(shù)據(jù)庫的執(zhí)行計劃卻是這樣的�。
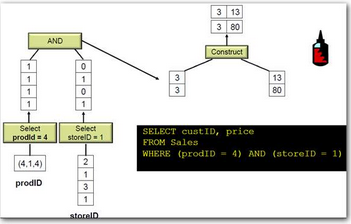
(from McKnight : Columnar Database : Data Does the Twist and Analytics Shout)[page]
在整個計算過程中�, 無論過濾�,投影,連接��,聚合操作�,列式數(shù)據(jù)庫都不解壓數(shù)據(jù)直到最后數(shù)據(jù)才還原原始數(shù)據(jù)值。這樣做的好處有減少CPU 消耗�,減少內(nèi)存消耗,減少網(wǎng)絡(luò)傳輸消耗����,減少最后儲存的需要。
列式數(shù)據(jù)庫優(yōu)缺點
列式數(shù)據(jù)庫從一開始就是面向大數(shù)據(jù)環(huán)境下數(shù)據(jù)倉庫的數(shù)據(jù)分析而產(chǎn)生��,它跟行式數(shù)據(jù)庫相比當然也有一些前提條件和優(yōu)缺點。
列式數(shù)據(jù)庫優(yōu)點:
極高的裝載速度 (最高可以等于所有硬盤IO 的總和��,基本是極限了)
適合大量的數(shù)據(jù)而不是小數(shù)據(jù)
實時加載數(shù)據(jù)僅限于增加(刪除和更新需要解壓縮Block 然后計算然后重新壓縮儲存)
高效的壓縮率�����,不僅節(jié)省儲存空間也節(jié)省計算內(nèi)存和CPU.
非常適合做聚合操作�。
缺點:
不適合掃描小量數(shù)據(jù)
不適合隨機的更新
批量更新情況各異,有的優(yōu)化的比較好的列式數(shù)據(jù)庫(比如Vertica)表現(xiàn)比較好��,有些沒有針對更新的數(shù)據(jù)庫表現(xiàn)比較差��。
不適合做含有刪除和更新的實時操作����。
常見誤區(qū)
一個常見的誤區(qū)認為如果每次掃描較多行或者全列全表掃描的時候,行式數(shù)據(jù)庫比列式數(shù)據(jù)庫更有優(yōu)勢��。事實上這只是行式數(shù)據(jù)庫認識上的一個誤區(qū)����,即認為列式數(shù)據(jù)庫的主要優(yōu)勢在于其列分開儲存,而忽略了列式數(shù)據(jù)庫上面提到的其他幾大特征�����,這個才是列式數(shù)據(jù)庫高性能的核心。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330