用機(jī)器學(xué)習(xí)構(gòu)建O(N)復(fù)雜度的排序算法���,可在GPU和TPU上加速計(jì)算
排序一直是計(jì)算機(jī)科學(xué)中最為基礎(chǔ)的算法之一��,從簡單的冒泡排序到高效的桶排序���,我們已經(jīng)開發(fā)了非常多的優(yōu)秀方法。但隨著機(jī)器學(xué)習(xí)的興起與大數(shù)據(jù)的應(yīng)用���,簡單的排序方法要求在大規(guī)模場景中有更高的穩(wěn)定性與效率��。中國科技大學(xué)和蘭州大學(xué)等研究者提出了一種基于機(jī)器學(xué)習(xí)的排序算法�����,它能實(shí)現(xiàn)
O(N) 的時(shí)間復(fù)雜度����,且可以在 GPU 和 TPU 上高效地實(shí)現(xiàn)并行計(jì)算。這篇論文在 Reddit
上也有所爭議����,我們也希望機(jī)器學(xué)習(xí)能在更多的基礎(chǔ)算法上展現(xiàn)出更優(yōu)秀的性能。
排序��,作為數(shù)據(jù)上的基礎(chǔ)運(yùn)算��,從計(jì)算伊始就有著極大的吸引力�����。雖然當(dāng)前已有大量的卓越算法����,但基于比較的排序算法對?(N log N)
比較有著根本的需求�,也就是 O(N log N)
時(shí)間復(fù)雜度����。近年來���,隨著大數(shù)據(jù)的興起(甚至萬億字節(jié)的數(shù)據(jù))���,效率對數(shù)據(jù)處理而言愈為重要,研究者們也做了許多努力來提高排序算法的效率�����。
大部分頂尖的排序算法采用并行計(jì)算來處理大數(shù)據(jù)集��,也取得了卓越的成果�。例如,2015 年阿里巴巴開發(fā)的 FuxiSort����,就是在 Apsara
上的分布式排序?qū)崿F(xiàn)。FuxiSort 能夠在隨機(jī)非偏態(tài)(non-skewed)數(shù)據(jù)集上用 377 秒完成 100TB 的 Daytona
GraySort 基準(zhǔn)��,在偏態(tài)數(shù)據(jù)集上的耗時(shí)是 510 秒�����,而在 Indy GraySort 基準(zhǔn)上的耗時(shí)是 329 秒。到了 2016 年��,在
Indy GraySort 基準(zhǔn)上��,Tencent Sort 排序 100TB 數(shù)據(jù)時(shí)達(dá)到了 60.7TB/min
的速度�����,使用的是為超大數(shù)據(jù)中心優(yōu)化過的包含 512 個(gè) OpenPOWER 服務(wù)器集群��。然而�,這些算法仍舊受下邊界復(fù)雜度和網(wǎng)絡(luò)耗時(shí)的限制。
另一方面���,機(jī)器學(xué)習(xí)在近年來發(fā)展迅速�,已經(jīng)在多個(gè)領(lǐng)域中得到廣泛應(yīng)用�。在 2012 年,使用深度卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn) ImageNet
圖像的接近誤差減半的分類是一項(xiàng)重大突破���,并使深度學(xué)習(xí)迅速被計(jì)算機(jī)視覺社區(qū)所接受。在 2016 年 3 月�����,AlphaGo
使用神經(jīng)網(wǎng)絡(luò)在人工智能的重大挑戰(zhàn)即圍棋中打敗了世界冠軍李世石。機(jī)器學(xué)習(xí)的巨大成功表明計(jì)算機(jī) AI
可以在復(fù)雜任務(wù)中超越人類知識(shí)�����,即使是從零開始�。在這之后,機(jī)器學(xué)習(xí)算法被廣泛應(yīng)用到了多種領(lǐng)域例如人類視覺��、自然語言理解����、醫(yī)學(xué)圖像處理等,并取得了很高的成就�����。
由人類大腦結(jié)構(gòu)啟發(fā)而來的神經(jīng)網(wǎng)絡(luò)方法擁有輸入層����、輸出層和隱藏層。隱藏層由多個(gè)鏈接人工神經(jīng)元構(gòu)成�����。這些神經(jīng)元連接強(qiáng)度根據(jù)輸入和輸出數(shù)據(jù)進(jìn)行調(diào)整,以精確地反映數(shù)據(jù)之間的關(guān)聯(lián)���。神經(jīng)網(wǎng)絡(luò)的本質(zhì)是從輸入數(shù)據(jù)到輸出數(shù)據(jù)的映射��。一旦訓(xùn)練階段完成�,我們可以應(yīng)用該神經(jīng)網(wǎng)絡(luò)來對未知數(shù)據(jù)進(jìn)行預(yù)測�。這就是所謂的推理階段。推理階段的精度和效率啟發(fā)研究者應(yīng)用機(jī)器學(xué)習(xí)技術(shù)到排序問題上����。在某種程度上,可以將排序問題看成是從數(shù)據(jù)到其在數(shù)據(jù)集位置的映射��。
在本文中�����,研究者提出了一個(gè)復(fù)雜度為 O(N·M)的使用機(jī)器學(xué)習(xí)的排序算法����,其在大數(shù)據(jù)上表現(xiàn)得尤其好。這里 M
是表示神經(jīng)網(wǎng)絡(luò)隱藏層中的神經(jīng)元數(shù)量的較小常數(shù)���。我們首先使用一個(gè) 3
層神經(jīng)網(wǎng)絡(luò)在一個(gè)小規(guī)模訓(xùn)練數(shù)據(jù)集上訓(xùn)練來逼近大規(guī)模數(shù)據(jù)集的分布�����。然后使用該網(wǎng)絡(luò)來評(píng)估每個(gè)位置數(shù)據(jù)在未來排序序列中的位置�。在推理階段�����,我們不需要對兩個(gè)數(shù)據(jù)之間進(jìn)行比較運(yùn)算�,因?yàn)槲覀円呀?jīng)有了近似分布。在推理階段完成之后����,我們得到了幾乎排序好的序列。因此��,我們僅需要應(yīng)用
O(N) 時(shí)間復(fù)雜度的運(yùn)算來得到完全排序的數(shù)據(jù)序列�。此外,該算法還可以應(yīng)用到稀疏哈希表上��。
算法
若假定我們有一個(gè)實(shí)數(shù)序列 S��,它的長度為 N���、上邊界和下邊界分別為 x_max 和 x_min����。對于一個(gè)有效的排序算法,我們需要交換 x_i
的位置來確保新的序列 S' 是經(jīng)過排序的����。假設(shè)一個(gè)實(shí)數(shù) x_i 在序列 S' 中的位置為 r_i,那么我們可以將排序問題視為一個(gè)雙映射函數(shù)
G(x_i)=r_i�����。如果我們可以預(yù)先求得這個(gè)函數(shù)��,那么排序算法的復(fù)雜度就為 O(N)�����。實(shí)際上��,如果序列 S 中所有的實(shí)數(shù)都來自同一分布
f(x)���,且當(dāng) N 足夠大時(shí)�����,那么 x_i 在新序列 S' 中的排位 r_i 將近似等于:
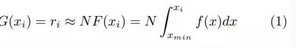
其中 F 為數(shù)據(jù)的概率分布函數(shù)���,且當(dāng) N 趨向于無窮大時(shí)����,表達(dá)式左右兩邊取等號(hào)����。
這樣形式化排序問題的困難時(shí)函數(shù) G(x) 通常是很難推導(dǎo)的�����,概率密度函數(shù) f(x) 同樣也如此�。然而當(dāng)我們處理大數(shù)據(jù)序列時(shí),N
會(huì)足夠大以令序列保持一些統(tǒng)計(jì)屬性�。因此如果我們能推出概率密度函數(shù) f(x),那么就有機(jī)會(huì)根據(jù)上面所示的方程 1 降低排序算法的復(fù)雜度到
O(N)����。
在這一篇論文中,作者們應(yīng)用了廣義支持向量機(jī)(General Vector Machine�����,GVM)來逼近概率密度函數(shù) f(x)���。這種 GVM
是帶有一個(gè)隱藏層的三層神經(jīng)網(wǎng)絡(luò)�����,且它的結(jié)構(gòu)展示在以下圖 1 中����。GVM 的學(xué)習(xí)過程基于蒙特卡洛算法而不是反向傳播,作者們也發(fā)現(xiàn) GVM
非常適合擬合函數(shù)�����。
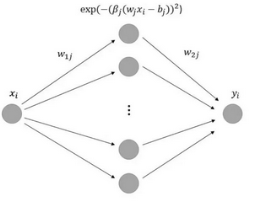
圖 1:GVM 的簡單圖示�����。研究者在每個(gè)實(shí)驗(yàn)中固定 M 為 100 個(gè)隱藏層神經(jīng)元��。
在該神經(jīng)網(wǎng)絡(luò)中���,輸入層僅有一個(gè)神經(jīng)元且輸入是用于擬合函數(shù)的 x_i����,輸出層也只有一個(gè)神經(jīng)元,輸出為 y_i�。研究者修改了隱藏層的神經(jīng)元數(shù)量為
M=100。實(shí)際在某種程度上��,隱藏層的神經(jīng)元越多擬合的精度就越大����,但同時(shí)也伴隨著過擬合問題,以及計(jì)算效率降低的問題�。
N 個(gè)實(shí)數(shù)的排序估計(jì)過程僅需要 O(N·M) 的時(shí)間�。M 與 N 是互相獨(dú)立的,且在理論分析上 M
是沒有下界的�。例如如果數(shù)據(jù)序列服從高斯分布且我們只使用一個(gè)隱藏神經(jīng)元,那么計(jì)算復(fù)雜度就為
log(N)��。特別地��,我們也可以用多個(gè)神經(jīng)元擬合高斯分布�,神經(jīng)元的數(shù)量依賴于機(jī)器學(xué)習(xí)方法。
在預(yù)測過程中���,這種算法不需要比較和交換運(yùn)算���,并且每個(gè)數(shù)據(jù)的排序估計(jì)都是互相獨(dú)立的,這使得并行計(jì)算變得高效且網(wǎng)絡(luò)負(fù)載小。除了高效并行計(jì)算之外��,由于機(jī)器學(xué)習(xí)需要矩陣運(yùn)算��,它還適用于在 GPU 或 TPU 上工作以實(shí)現(xiàn)加速 [19]����。
實(shí)驗(yàn)
如圖 2 所示,我們選擇兩種分布進(jìn)行實(shí)驗(yàn):均勻分布和截尾正態(tài)分布��。
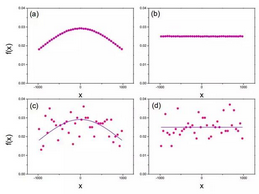
圖 2:數(shù)據(jù)分布���。(a)截尾正態(tài)分布和(b)均勻分布的 107 個(gè)數(shù)據(jù)點(diǎn)�����。(c)截尾正態(tài)分布和(d)均勻分布的訓(xùn)練序列分布的 103 個(gè)數(shù)據(jù)點(diǎn)�����。紫色實(shí)線是解析分布�,粉色點(diǎn)線是實(shí)驗(yàn)數(shù)據(jù)�。
圖 3 對比了 Tim Sorting 和 Machine Learning Sorting 的運(yùn)行時(shí)間。
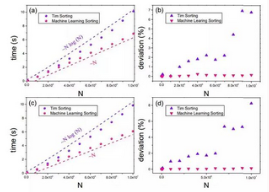
圖
3:(a)截尾正態(tài)分布的數(shù)據(jù)數(shù)量和時(shí)間復(fù)雜度的關(guān)系���。(b)截尾正態(tài)分布的數(shù)據(jù)數(shù)量和時(shí)間復(fù)雜度離均差的關(guān)系�。(c)均勻分布的數(shù)據(jù)數(shù)量和時(shí)間復(fù)雜度的關(guān)系。(d)均勻分布的數(shù)據(jù)數(shù)量和時(shí)間復(fù)雜度離均差的關(guān)系����,研究者使用了
102 次實(shí)現(xiàn)的總體均值來獲得結(jié)果。
我們提出了一種基于機(jī)器學(xué)習(xí)方法的 O(N) 排序算法���,其在大數(shù)據(jù)排序應(yīng)用上有巨大的潛力����。該排序算法可以應(yīng)用到并行排序��,且適用于 GPU 或 TPU 加速�����。此外�����,我們還將該算法應(yīng)用到了稀疏哈希表上����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330