熱度碾壓 Java��、C#�、C++的 Python,為什么速度那么慢
眼下 Python 異?��;鸨?����,不論是 DevOps���、數(shù)據(jù)科學(xué)��、Web 開(kāi)發(fā)還是安全領(lǐng)域�,都在用 Python——但是它在速度上卻沒(méi)有任何優(yōu)勢(shì)�。
與
C、C++����、C# 或 Python 相比,Java
的速度如何���?答案很大程度上依賴(lài)于你需要運(yùn)行的應(yīng)用種類(lèi)�。世上沒(méi)有完美的性能測(cè)試����,但計(jì)算機(jī)語(yǔ)言評(píng)測(cè)游戲(Computer Language
Benchmarks Game)是個(gè)很好的測(cè)試方式:http://algs4.cs.princeton.edu/faq/。
我從十年前就開(kāi)始談?wù)撚?jì)算機(jī)語(yǔ)言評(píng)測(cè)游戲���。與
Java�����、C#、Go��、Java、C++ 等其他語(yǔ)言相比�����,Python 是最慢的語(yǔ)言之一����。這里包括JIT(Just In
Time)語(yǔ)言(如C#、Java)和 AOT(Ahead Of Time)語(yǔ)言(C���、C++)編譯器���,也有 Java 這種解釋語(yǔ)言。

注:本文中所說(shuō)的“Python”是指語(yǔ)言的具體實(shí)現(xiàn)���,即 CPython����。本文也會(huì)提到其他運(yùn)行��。
我希望回答以下問(wèn)題:如果 Python 完成相同的任務(wù)要花費(fèi)其他語(yǔ)言二至十倍的時(shí)間���,那么它為什么慢��,能不能更快一些呢?
以下是幾種常見(jiàn)的原因:
-
“因?yàn)樗荊IL(全局解釋器鎖)”
-
“因?yàn)樗墙忉屨Z(yǔ)言不是編譯語(yǔ)言”
-
“因?yàn)樗莿?dòng)態(tài)類(lèi)型語(yǔ)言”
究竟哪個(gè)原因?qū)π阅艿挠绊懽畲螅?
“因?yàn)樗荊IL”
現(xiàn)代計(jì)算機(jī)的
CPU 有多個(gè)核心�,有時(shí)甚至有多個(gè)處理器����。為了利用所有計(jì)算能力,操作系統(tǒng)定義了一個(gè)底層結(jié)構(gòu)�,叫做線(xiàn)程,而一個(gè)進(jìn)程(例如
Chrome瀏覽器)能夠生成多個(gè)線(xiàn)程���,通過(guò)線(xiàn)程來(lái)執(zhí)行系統(tǒng)指令���。這樣如果一個(gè)進(jìn)程是要使用很多
CPU�����,那么計(jì)算負(fù)載就會(huì)由多個(gè)核心分擔(dān),最終使得絕大多數(shù)應(yīng)用能更快地完成任務(wù)。
在撰寫(xiě)本文時(shí),我的 Chrome 瀏覽器開(kāi)了 44 個(gè)線(xiàn)程。另外,基于 POSIX 的操作系統(tǒng)(如 Mac OS 和 Linux)的線(xiàn)程結(jié)構(gòu)和 API 與 Windows 操作系統(tǒng)是不一樣的。操作系統(tǒng)還負(fù)責(zé)線(xiàn)程的調(diào)度。
如果你沒(méi)寫(xiě)過(guò)多線(xiàn)程程序,那么你應(yīng)該了解一下鎖的概念��。與單線(xiàn)程進(jìn)程不同,在多線(xiàn)程編程中��,你要確保改變內(nèi)存中的變量時(shí)����,多個(gè)線(xiàn)程不會(huì)試圖同時(shí)修改或訪(fǎng)問(wèn)同一個(gè)內(nèi)存地址��。
CPython 在創(chuàng)建變量時(shí)會(huì)分配內(nèi)存,然后用一個(gè)計(jì)數(shù)器計(jì)算對(duì)該變量的引用的次數(shù)�����。這個(gè)概念叫做“引用計(jì)數(shù)”�����。如果引用的數(shù)目為 0��,那就可以將這個(gè)變量從系統(tǒng)中釋放掉。這樣���,創(chuàng)建“臨時(shí)”變量(如在 for 循環(huán)的上下文環(huán)境中)不會(huì)耗光應(yīng)用程序的內(nèi)存。
隨之而來(lái)的問(wèn)題就是���,如果變量在多個(gè)線(xiàn)程中共享����,CPython 需要對(duì)引用計(jì)數(shù)器加鎖���。有一個(gè)“全局解釋器鎖”會(huì)謹(jǐn)慎地控制線(xiàn)程的執(zhí)行���。不管有多少個(gè)線(xiàn)程��,解釋器一次只能執(zhí)行一個(gè)操作��。
這對(duì) Python 應(yīng)用的性能有什么影響���?
如果應(yīng)用程序是單線(xiàn)程、單解釋器的���,那么這不會(huì)對(duì)速度有任何影響��。去掉 GIL 也不會(huì)影響代碼的性能����。
但如果想用一個(gè)解釋器(一個(gè) Python 進(jìn)程)通過(guò)線(xiàn)程實(shí)現(xiàn)并發(fā)�����,而且線(xiàn)程是IO 密集型的(即有很多網(wǎng)絡(luò)輸入輸出或磁盤(pán)輸入輸出)��,那么就會(huì)出現(xiàn)下面這種 GIL 競(jìng)爭(zhēng):

來(lái)自于David Beazley的“圖解GIL”一文:http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
如果 Web
應(yīng)用(如 Django)使用了 WSGI����,那么發(fā)往 Web 應(yīng)用的每個(gè)請(qǐng)求都會(huì)由獨(dú)立的 Python
解釋器執(zhí)行�,因此每個(gè)請(qǐng)求都只會(huì)有一個(gè)鎖�����。由于 Python 解釋器啟動(dòng)很慢,一些 WSGI 實(shí)現(xiàn)就支持“守護(hù)模式”,保持 Python
進(jìn)程長(zhǎng)期運(yùn)行�。
其他 Python 運(yùn)行時(shí)如何����?
PyPy 的 GIL 通常要比 CPython 快三倍以上。
Jython 沒(méi)有 GIL 因?yàn)?Jython 中的 Python 線(xiàn)程由 Java 線(xiàn)程表示,因此能享受到 JVM 內(nèi)存管理系統(tǒng)的好處��。
Java 怎么處理這個(gè)問(wèn)題i?
首先�����,所有 Java 引擎都是用標(biāo)記-清除垃圾回收算法�����。如前所述���,對(duì) GIL 的需求主要是由 CPython 的內(nèi)存管理算法導(dǎo)致的�����。
Java 沒(méi)有 GIL�����,但它也是單線(xiàn)程的����,所以它根本不需要。Java 的時(shí)間循環(huán)和 Promise/Callback 模式實(shí)現(xiàn)了異步編程�,取代了并發(fā)編程。Python 也能通過(guò) asyncio 的事件循環(huán)實(shí)現(xiàn)類(lèi)似的模式�。
“因?yàn)樗墙忉屨Z(yǔ)言”
這條理由我也聽(tīng)過(guò)很多,我發(fā)現(xiàn)它過(guò)于簡(jiǎn)化了 CPython 的實(shí)際工作原理����。當(dāng)你在終端上寫(xiě) python my.py 時(shí),CPython 會(huì)啟動(dòng)一長(zhǎng)串操作����,包括讀取、詞法分析��、語(yǔ)法分析���、編譯��、解釋以及執(zhí)行�����。
如果你對(duì)這些過(guò)程感興趣����,可以看看我之前寫(xiě)的文章:
6分鐘修改Python語(yǔ)言:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
這個(gè)過(guò)程的重點(diǎn)就是它會(huì)在編譯階段生成.pyc文件�,字節(jié)碼會(huì)寫(xiě)到__pycache__/下的文件中(如果是Python 3),或者寫(xiě)到與源代碼同一個(gè)目錄中(Python 2)��。不僅你編寫(xiě)的腳本是這樣����,所有你導(dǎo)入的代碼都是這樣,包括第三方模塊�����。
因此絕大多數(shù)情況下(除非你寫(xiě)的代碼只會(huì)運(yùn)行一次)����,Python是在解釋字節(jié)碼并在本地執(zhí)行。與Java和C#.NET比較一下:
Java將源代碼編譯成“中間語(yǔ)言”���,然后Java虛擬機(jī)讀取字節(jié)碼并即時(shí)編譯成機(jī)器碼��。.NET CIL也是一樣的�����,.NET的公共語(yǔ)言運(yùn)行時(shí)(CLR)使用即時(shí)編譯將字節(jié)碼編譯成機(jī)器碼�。
那么,既然它們都使用虛擬機(jī)��,以及某種字節(jié)碼�,為什么Python在性能測(cè)試中比Java和C#慢那么多?第一個(gè)原因是���,.NET和Java是即時(shí)編譯的(JIT)����。
即時(shí)編譯��,即JIT(Just-in-time)����,需要一種中間語(yǔ)言,將代碼分割成小塊(或者稱(chēng)幀)����。而提前編譯(Ahead of Time,簡(jiǎn)稱(chēng)AOT)是編譯器把源代碼翻譯成CPU能理解的代碼之后再執(zhí)行����。
JIT本身并不能讓執(zhí)行更快��,因?yàn)樗鼒?zhí)行的是同樣的字節(jié)碼序列��。但是�,JIT可以在運(yùn)行時(shí)做出優(yōu)化����。好的GIT優(yōu)化器能找到應(yīng)用程序中執(zhí)行最多的部分�����,稱(chēng)為“熱點(diǎn)”���。然后對(duì)那些字節(jié)碼進(jìn)行優(yōu)化�,將它們替換成效率更高的代碼���。
這就是說(shuō)�,如果你的應(yīng)用程序會(huì)反復(fù)做某件事情����,那么速度就會(huì)快很多。此外���,別忘了Java和C#都是強(qiáng)類(lèi)型語(yǔ)言��,所以?xún)?yōu)化器可以對(duì)代碼做更多的假設(shè)��。
前面說(shuō)過(guò)��,PyPy有個(gè)JIT�����,因此它比CPython要快很多�����。下面這篇性能測(cè)試的文章介紹得更詳細(xì):
哪個(gè)版本的Python最快�����?
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
那么為什么CPython不用JIT��?
JIT也有缺點(diǎn):首先就是啟動(dòng)速度����。CPython的啟動(dòng)速度已經(jīng)比較慢了,而PyPy的啟動(dòng)速度要比CPython慢兩到三倍���。Java虛擬機(jī)的啟動(dòng)速度也是出了名的慢���。.NET
CLR在系統(tǒng)啟動(dòng)時(shí)啟動(dòng)����,因此避免了這個(gè)問(wèn)題�,但這要?dú)w功于CLR和操作系統(tǒng)是同一撥開(kāi)發(fā)者開(kāi)發(fā)的���。
如果你有一個(gè)Python進(jìn)程需要運(yùn)行很長(zhǎng)時(shí)間����,而且代碼里包含“熱點(diǎn)”可以被優(yōu)化���,那么使用JIT就很不錯(cuò)�����。
但是���,CPython是個(gè)通用的實(shí)現(xiàn)。因此如果要用Python開(kāi)發(fā)命令行程序����,那么每次都要等待JIT調(diào)用CLI就特別慢了���。
CPython試圖滿(mǎn)足大部分情況下的需求。有一個(gè)在CPython中實(shí)現(xiàn)JIT(https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython)的項(xiàng)目���,不過(guò)這個(gè)項(xiàng)目已經(jīng)停止很久了���。
如果你想要享受JIT的好處,并且要處理的任務(wù)適合JIT��,那就使用PyPy��。
“因?yàn)樗莿?dòng)態(tài)類(lèi)型語(yǔ)言”
“靜態(tài)類(lèi)型”語(yǔ)言要求必須在變量定義時(shí)指定其類(lèi)型�����,例如C�����、C++�、Java、C#和Go等。
而動(dòng)態(tài)類(lèi)型語(yǔ)言中盡管也有類(lèi)型的概念�,但變量的類(lèi)型是動(dòng)態(tài)的。
a=1
a="foo"
在這個(gè)例子中�����,Python用相同的名字和str類(lèi)型定義了第二個(gè)變量�����,同時(shí)釋放了第一個(gè)a的實(shí)例占用的內(nèi)存���。
靜態(tài)類(lèi)型語(yǔ)言的設(shè)計(jì)目的并不是折磨人��,這樣設(shè)計(jì)是因?yàn)镃PU就是這樣工作的。如果任何操作最終都要轉(zhuǎn)化成簡(jiǎn)單的二進(jìn)制操作��,那就需要將對(duì)象和類(lèi)型都轉(zhuǎn)換成低級(jí)數(shù)據(jù)結(jié)構(gòu)�。
Python幫你做了這一切,只不過(guò)你從來(lái)沒(méi)有關(guān)心過(guò)���,也不需要關(guān)心����。
不需要定義類(lèi)型并不是Python慢的原因����。Python的設(shè)計(jì)可以讓你把一切都做成動(dòng)態(tài)的�。你可以在運(yùn)行時(shí)替換對(duì)象的方法,可以在運(yùn)行時(shí)給底層系統(tǒng)調(diào)用打補(bǔ)丁。幾乎一切都有可能���。
而這種設(shè)計(jì)使得Python的優(yōu)化變得很困難。
為了演示這個(gè)觀(guān)點(diǎn)����,我使用了一個(gè)Mac OS下的系統(tǒng)調(diào)用跟蹤工具,叫做Dtrace��。CPython的發(fā)布并不支持DTrace�,因此需要重新編譯CPython。演示中用的是Python 3.6.6:
wget https://github.com/python/cpython/archive/v3.6.6.zip
unzip v3.6.6.zip
cd v3.6.6
./configure --with-dtrace
make
現(xiàn)在Python.exe的代碼中包含了Dtrace的跟蹤代碼��。Paul
Ross有一篇非常好的關(guān)于DTrace的演講(https://github.com/paulross/dtrace-py#the-lightning-talk)��?����?梢詮倪@里下載DTrace用于Python的文件(https://github.com/paulross/dtrace-py/tree/master/toolkit)用來(lái)測(cè)量函數(shù)調(diào)用�、執(zhí)行時(shí)間、CPU時(shí)間、系統(tǒng)調(diào)用以及各種函數(shù)等等��。
sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe .py’
py_callflow跟蹤器會(huì)顯示應(yīng)用程序的所有函數(shù)調(diào)用����。
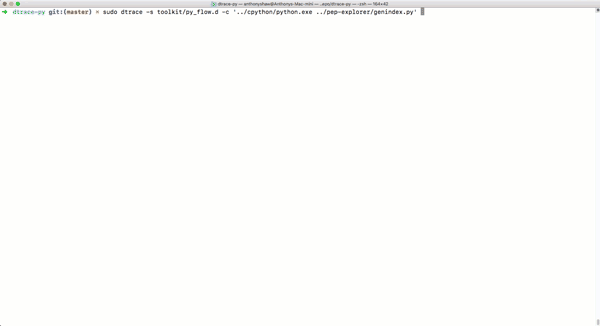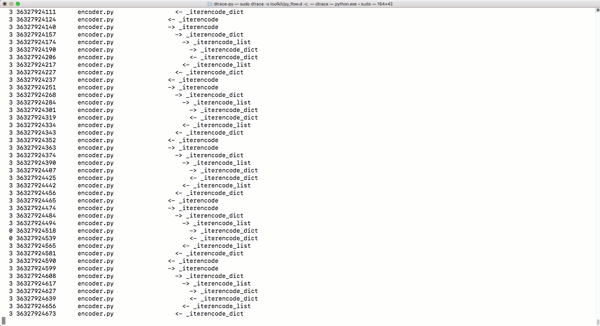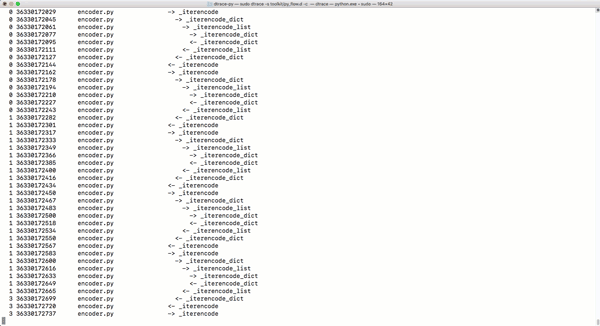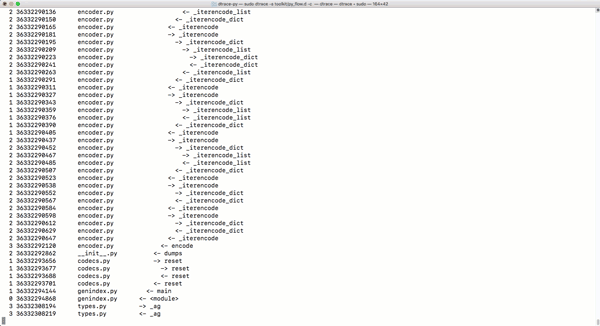
-
那么,Python的動(dòng)態(tài)類(lèi)型是否讓Python更慢���?
-
比較并轉(zhuǎn)換類(lèi)型的代價(jià)很大����。每次讀取���、寫(xiě)入或引用變臉時(shí)都會(huì)檢查類(lèi)型
-
動(dòng)態(tài)類(lèi)型的語(yǔ)言很難優(yōu)化����。許多替代Python的語(yǔ)言很快的原因就是它們犧牲了便利性來(lái)交換性能�����。
-
例如Cython(http://cython.org/)��,它通過(guò)結(jié)合C的靜態(tài)類(lèi)型和Python的方式�����,使得代碼中的類(lèi)型已知����,從而優(yōu)化代碼,能夠獲得84倍的性能提升(http://notes-on-cython.readthedocs.io/en/latest/std_dev.html)
結(jié)論
Python慢的主要原因是因?yàn)樗膭?dòng)態(tài)和多樣性����。它能用于解決各種問(wèn)題,但多數(shù)問(wèn)題都有優(yōu)化得更好和更快的解決方案���。
但Python應(yīng)用也有許多優(yōu)化措施�,如使用異步����、理解性能測(cè)試工具,以及使用多解釋器等�����。
對(duì)于啟動(dòng)時(shí)間不重要����,而代碼可能享受到JIT的好處的應(yīng)用�,可以考慮使用PyPy�。
對(duì)于代碼中性能很重要的部分,如果變量大多是靜態(tài)類(lèi)型����,可以考慮使用Cython。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330