R語(yǔ)言vs Python:硬碰硬的數(shù)據(jù)分析
我們將在已有的數(shù)十篇從主觀角度對(duì)比Python和R的文章中加入自己的觀點(diǎn)�����,但是這篇文章旨在更客觀地看待這兩門語(yǔ)言���。我們會(huì)平行使用Python和R分析一個(gè)數(shù)據(jù)集,展示兩種語(yǔ)言在實(shí)現(xiàn)相同結(jié)果時(shí)需要使用什么樣的代碼�����。這讓我們了解每種語(yǔ)言的優(yōu)缺點(diǎn)��,而不是猜想�����。
我們將會(huì)分析一個(gè)NBA數(shù)據(jù)集,包含運(yùn)動(dòng)員和他們?cè)?013-2014賽季的表現(xiàn)�����,可以在這里下載這個(gè)數(shù)據(jù)集。我們展示Python和R的代碼���,同時(shí)做出一些解釋和討論�����。事不宜遲�,現(xiàn)在就開始這場(chǎng)硬碰硬的對(duì)決吧!
讀取CSV文件
R
nba <- read.csv("nba_2013.csv")
Python
import pandas
nba = pandas.read_csv("nba_2013.csv")
上面的代碼分別在兩種語(yǔ)言中將包含2013-2014賽季NBA球員的數(shù)據(jù)的 nba_2013.csv
文件加載為變量nba。Python中實(shí)際的唯一不同是需要加載pandas庫(kù)以使用Dataframe����。Dataframe在R和Python中都可用�����,它是一個(gè)二維數(shù)組(矩陣),其中每列都可以是不同的數(shù)據(jù)類型�。在完成這一步后���,csv文件在兩種語(yǔ)言中都加載為dataframe��。
統(tǒng)計(jì)球員數(shù)量
R
print(dim(nba))
[1] 481 31
Python
print(nba.shape)
(481, 31)
兩者分別輸出球員數(shù)量和數(shù)據(jù)列數(shù)量����。我們有481行,或者說(shuō)球員����,和31列關(guān)于球員的數(shù)據(jù)。
查看數(shù)據(jù)的第一行
R
print(head(nba, 1))
player pos age bref_team_id
1 Quincy Acy SF 23 TOT
[output truncated]
Python
print(nba.head(1))
player pos age bref_team_id
0 Quincy Acy SF 23 TOT
[output truncated]
它們幾乎完全相同�����。兩種語(yǔ)言都打印出數(shù)據(jù)的第一行���,語(yǔ)法也非常類似��。Python在這里更面向?qū)ο笠恍?�,head是dataframe對(duì)象的一個(gè)方法�����,而R具有一個(gè)單獨(dú)的head函數(shù)����。當(dāng)開始使用這些語(yǔ)言做分析時(shí),這是一個(gè)共同的主題�,可以看到Python更加面向?qū)ο蠖鳵更函數(shù)化。
計(jì)算每個(gè)指標(biāo)的均值
讓我們?yōu)槊總€(gè)指標(biāo)計(jì)算均值��。如你所見���,數(shù)據(jù)列以類似fg(field goals made)和ast(assists)的名稱命名��。它們都是球員的賽季統(tǒng)計(jì)指標(biāo)�����。如果想得到指標(biāo)的完整說(shuō)明���,參閱這里。
R
meanNoNA <- function(values){
mean(values, na.rm=TRUE)
}
sapply(nba, meanNoNA)
player NA
pos NAage 26.5093555093555
bref_team_id NA
[output truncated]
Python
import numpy
nba_numeric = nba._get_numeric_data()
nba_numeric.apply(numpy,.mean, axis=0)
age 26.509356
g 53.253638
gs 25.571726
[output truncated]
這里有一些明顯的分歧�����。在兩種方法中�,我們均在dataframe的列上應(yīng)用了一個(gè)函數(shù)����。在python中���,如果我們?cè)诜菙?shù)值列(例如球員姓名)上應(yīng)用函數(shù)����,會(huì)返回一個(gè)錯(cuò)誤。要避免這種情況,我們只有在取平均值之前選擇數(shù)值列��。
在R中��,對(duì)字符串列求均值會(huì)得到NA——not
available(不可用)��。然而�,我們?cè)谌【禃r(shí)需要確實(shí)忽略NA(因此需要構(gòu)建我們自己的函數(shù))。否則類似x3p.這樣的一些列的均值將會(huì)為NA����,這一列代表三分球的比例。有些球員沒有投出三分球�����,他們的百分比就是缺失的�����。如果我們直接使用R中的mean函數(shù)��,就會(huì)得到NA��,除非我們指定na.rm=TRUE�����,在計(jì)算均值時(shí)忽略缺失值�。
繪制成對(duì)散點(diǎn)圖
一個(gè)探索數(shù)據(jù)的常用方法是查看列與列之間有多相關(guān)。我們將會(huì)比較ast,fg和trb���。
R
library(GGally)
ggpairs(nba[, c("ast", "fg", "trb")])
import seaborn as snsimport matplotlib.pyplot as plt
sns.pairplot(nba[["ast", "fg", "trb"]])
plt.show()
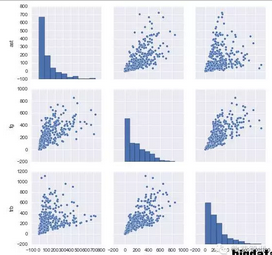
我們會(huì)得到非常相似的兩張圖,但是可以看到R的數(shù)據(jù)科學(xué)生態(tài)中有許多較小的軟件包(GGally是最常用的R繪圖包ggplot2的輔助包)和更多的通用可視化軟件包��。在Python中���,matplotlib是主要的繪圖包���,seaborn是一個(gè)廣泛用于matplotlib上的圖層����。Python中的可視化通常只有一種蛀牙哦的方法完成某件事���,而R中可能有許多包支持不同的方法(例如,至少有半打繪制成對(duì)散點(diǎn)圖的包)�����。
對(duì)球員聚類
另一個(gè)很好探索數(shù)據(jù)的方式是生成類別圖。這將會(huì)顯示哪些球員更相似��。
R
library(cluster)
set.seed(1)
isGoodCol <- function(col){
sum(is.na(col)) ==0&& is.numeric(col)
}
goodCols <- sapply(nba, isGoodCol)
clusters <- kmeans(nba[,goodCols], centers=5)
labels <- clusters$cluster
Python
from sklearn.cluster import KMeans
kmeans_model = KMeans(n_clusters=5, random_state=1)
good_columns = nba._get_numeric_data().dropna(axis=1)
kmeans_model.fit(good_columns)
labels = kmeans_model.labels_
為了正確的聚類����,我們移除了所有非數(shù)值列,以及包含缺失值的列�。在R中,我們?cè)诿恳涣猩蠎?yīng)用一個(gè)函數(shù)��,如果該列包含任何缺失值或不是數(shù)值��,則刪除它��。接下來(lái)我們使用cluster包實(shí)施k-means聚類��,在數(shù)據(jù)中發(fā)現(xiàn)5個(gè)簇。通過(guò)set.seed設(shè)置隨機(jī)種子以使結(jié)果可復(fù)現(xiàn)��。
在Python中����,我們使用了主要的Python機(jī)器學(xué)習(xí)包scikit-learn擬合k-means模型并得到類別標(biāo)簽��。數(shù)據(jù)準(zhǔn)備的過(guò)程和R非常類似�����,但是用到了get_numeric_data和dropna方法����。
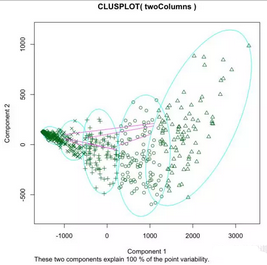
繪制類別圖
我們現(xiàn)在可以按類別繪制球員分布圖以發(fā)現(xiàn)模式。首先使用PCA將數(shù)據(jù)降至2維��,然后畫圖�,用不同標(biāo)記或深淺的點(diǎn)標(biāo)志類別。
nba2d <- prcomp(nba[,goodCols], center=TRUE)
twoColumns <- nba2d$x[,1:2]
clusplot(twoColumns, labels)
Python
from sklearn.decomposition import PCA
pca_2 = PCA(2)
plot_columns = pca_2.fit_transform(good_columns)
plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=labels)
plt.show()
在R中,我們通過(guò)聚類庫(kù)中的函數(shù)clusplot函數(shù)繪圖��,使用內(nèi)建函數(shù)pccomp實(shí)行PCA�����。
在Python中����,我們使用scikit-learn庫(kù)中的PCA類,使用matplotlib創(chuàng)建圖形��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330