應(yīng)用關(guān)聯(lián)規(guī)則模型提高超市銷量
Statistics 和 Modeler作為 IBM SPSS 軟件家族中重要的成員,是專業(yè)的科學(xué)統(tǒng)計��、數(shù)據(jù)挖掘分析工具,其具有功能強大����,應(yīng)用廣泛的特點。其核心 組成部分——預(yù)測分析模型����,不僅是軟件功能實現(xiàn)的關(guān)鍵���,同時也是軟件應(yīng)用的關(guān)鍵。
Statistics中的模型側(cè)重于統(tǒng)計分析技術(shù),
而Modeler則側(cè)重于數(shù)據(jù)挖掘技術(shù)。它們都依據(jù)現(xiàn)有數(shù)據(jù)�����,運用某個或某幾個特定的算法�,來預(yù)測用戶所關(guān)注信息的未來值。Statistics 和
Modeler提供眾多的預(yù)測模型��,這使得它們可以應(yīng)用在多種商業(yè)領(lǐng)域中:如超市商品如何擺放可以提高銷量�����;分析商場營銷的打折方案��,以制定新的更為有效的方案��;保險公司分析以往的理賠案例,以推出新的保險品種等等��,具有很強的商業(yè)價值。
Statistics和
Modeler產(chǎn)品中含有大量基于高級數(shù)學(xué)統(tǒng)計算法的預(yù)測模型�����,為了保證算法的嚴(yán)密性及結(jié)果的精確性���,模型往往還需要許多詳細的參數(shù)設(shè)定�,這樣就要求用戶具有一定的統(tǒng)計專業(yè)知識��,只有理解預(yù)測模型中的各項設(shè)置及運算結(jié)果的真實意義����,才有可能結(jié)合結(jié)果做出正確的決策判斷���;另外��,為了滿足不同行業(yè)用戶的需求���,Statistics和
Modeler涉及到數(shù)學(xué)領(lǐng)域中多個不同的范疇,即使專業(yè)用戶也很難了解所有模型�����,從而挑選出最適合他們應(yīng)用的模型�����。
因此,為了讓更多的用戶更好更準(zhǔn)確地使用我們的產(chǎn)品,最大地發(fā)揮其商業(yè)價值�,我們將通過一系列的相關(guān)文章來介紹IBM SPSS軟件家族中Statistics 和 Modeler的典型預(yù)測模型以及他們在解決相應(yīng)的商業(yè)問題中的實際應(yīng)用。
本系列文章從實際問題出發(fā),通過一些實際生活中常見的商業(yè)問題來引出IBM
SPSS
軟件家族中的典型預(yù)測模型����,手把手地指導(dǎo)用戶如何在軟件中對該模型進行設(shè)置����,如何查看運行結(jié)果,講解運行結(jié)果的真實意義,最后引申到如何將該結(jié)果應(yīng)用于解決這個具體的商業(yè)問題中來。用這種最直觀簡單的方式使即使缺乏統(tǒng)計學(xué)背景的用戶也能容易地理解這些預(yù)測模型,從而很好地使用我們的產(chǎn)品。
同時�,文中也涉及了一定的統(tǒng)計知識�����,使具有專業(yè)知識的用戶能依此線索盡可能多的了解我們的產(chǎn)品的方方面面�����,從而選擇最適合他們問題的模型��。
下面�����,我們將會陸續(xù)給大家介紹IBM SPSS 軟件家族中的Statistics 和 Modeler包含的典型預(yù)測模型�。
超市典型案例
如何擺放超市的商品引導(dǎo)消費者購物從而提高銷量�����,這對大型連鎖超市來說是一個現(xiàn)實的營銷問題�。關(guān)聯(lián)規(guī)則模型自它誕生之時為此類問題提供了一種科學(xué)的解決方法。該模型利用數(shù)據(jù)挖掘的技術(shù),在海量數(shù)據(jù)中依據(jù)該模型的獨特算法發(fā)現(xiàn)數(shù)據(jù)內(nèi)在的規(guī)律性聯(lián)系,進而提供具有洞察力的分析解決方案。以下我們將通過一則超市銷售商品的案例,利用
IBM SPSS Modeler
產(chǎn)品中的“關(guān)聯(lián)規(guī)則模型”�,來分析商品交易流水?dāng)?shù)據(jù),以其發(fā)現(xiàn)合理的商品擺放規(guī)則,來幫助提高銷量����。文中將詳細地描述產(chǎn)品的設(shè)置和使用方法,以及對計算結(jié)果的分析及應(yīng)用�。
關(guān)聯(lián)規(guī)則簡介
關(guān)聯(lián)規(guī)則的定義
關(guān)聯(lián)規(guī)則表示不同數(shù)據(jù)項目在同一事件中出現(xiàn)的相關(guān)性�,就是從大量數(shù)據(jù)中挖掘出關(guān)聯(lián)規(guī)則。為了更直觀的理解關(guān)聯(lián)規(guī)則�,我們首先來看下圖的場景�。
圖 1. 超市市場分析員分析顧客購買習(xí)慣
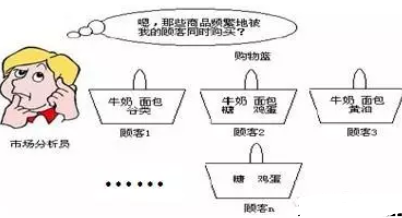
在上圖中��,超市市場分析員分析顧客購買商品的場景���,顧客購買面包同時也會購買牛奶的購物模式就可用以下的關(guān)聯(lián)規(guī)則來描述:
面包 => 牛奶 [ 支持度 =2%, 置信度 =60%] (式 1)
式 1中面包是規(guī)則前項(Antecedent)��,牛奶是規(guī)則后項 (Consequent)��。實例數(shù)(Instances)表示所有購買記錄中包含面包的記錄的數(shù)量。支持度(Support)表示購買面包的記錄數(shù)占所有的購買記錄數(shù)的百分比。規(guī)則支持度(Rule Support)表示同時購買面包和牛奶的記錄數(shù)占所有的購買記錄數(shù)的百分比����。置信度(confidence)表示同時購買面包和牛奶的記錄數(shù)占購買面包記錄數(shù)的百分比。提升(Lift)表示置信度與已知購買牛奶的百分比的比值��,提升大于 1 的規(guī)則才是有意義的�����。關(guān)聯(lián)規(guī)則 式 1的支持度
2% 意味著,所分析的記錄中的 2% 購買了面包����。置信度 60% 表明����,購買面包的顧客中的 60%
也購買了牛奶。如果關(guān)聯(lián)滿足最小支持度閾值和最小置信度閾值���,就說關(guān)聯(lián)規(guī)則是有意義的�����。這些閾值可以由用戶或領(lǐng)域?qū)<以O(shè)定��。就顧客購物而言,根據(jù)以往的購買記錄,找出滿足最小支持度閾值和最小置信度閾值的關(guān)聯(lián)規(guī)則�,就找到顧客經(jīng)常同時購買的商品�。
數(shù)據(jù)格式
關(guān)聯(lián)規(guī)則使用的數(shù)據(jù)可能是交易格式,也可能是表格格式���,如下所述���。
交易格式
交易數(shù)據(jù)對于每個交易或項目具有一個單獨的記錄。例如��,如果客戶進行了多次采購�,則每次采購都會有一個單獨的記錄,并且相關(guān)聯(lián)的商品與客戶 ID 相鏈接��。這種格式有時稱為 行窮盡格式�����。
表 1. 交易格式數(shù)據(jù)
客戶 采購
1 jam
2 milk
3 jam
3 bread
4 jam
4 bread
4 milk
表格格式
表格數(shù)據(jù)(也稱為籃子數(shù)據(jù)或真值表數(shù)據(jù))�����,由單獨的標(biāo)志表示項目��,其中每個標(biāo)志字段表示一個特定項目的存在或不存在。每個記錄表示一個相關(guān)項目的完整集合��。標(biāo)志字段可以是分類的��,也可以是數(shù)字的���。
表 2. 表格格式數(shù)據(jù)
客戶 Jam Bread Milk
1 T F F
2 F F T
3 T T F
4 T T T規(guī)則挖掘算法
Aprior、Carma 和序列節(jié)點是常用的關(guān)聯(lián)規(guī)則挖掘算法���,它們都可以使用交易格式和表格格式數(shù)據(jù)進行挖掘處理��。其中 Aprior 算法����,處理速度快����,對包含的規(guī)則數(shù)沒有限制,是一種最有影響的挖掘關(guān)聯(lián)規(guī)則的方法��。
IBM SPSS Modeler 關(guān)聯(lián)規(guī)則模型的使用
IBM SPSS Modeler 作為一種可視化的數(shù)據(jù)挖掘和建模工具���,支持 Aprior�、Carma 和序列節(jié)點關(guān)聯(lián)規(guī)則挖掘模型,本章節(jié)將重點介紹 Aprior 模型的設(shè)置����、使用方法和結(jié)果分析。
對于超市市場分析員分析顧客購買習(xí)慣的案例����,現(xiàn)在讓我們設(shè)定一個實際的場景,市場分析員利用超市海量的購物清單����,從中分析出顧客購買啤酒會和哪些商品一起購買,依次來合理安排商品的擺放����,進而提高啤酒的銷量。
對于此案例���,我們使用 IBM SPSS Modeler 自帶的安裝目錄下的 Demos 文件夾下的 BASKETS1n 數(shù)據(jù)��。我們希望分析出哪些商品會和啤酒一起購買�����,以此來合理安排商品的擺放�,進而提高啤酒的銷量。
此數(shù)據(jù)屬于表格格式數(shù)據(jù)���,每條記錄表示顧客的一次購物�����。記錄的字段包括卡號���、顧客基本信息�、付款方式和商品名稱(每個商品一個字段
, 該商品字段值為 T, 表示購買該商品 , 值為 F 表示未購買,具體可參考表 2, 表格格式數(shù)據(jù))�����。商品名稱都有
fruitveg(水果蔬菜)�����,freshmeat(生鮮肉)�,dairy(奶制品),cannedveg(罐裝蔬菜)���,cannedmeat(罐裝肉)����,fozenmeal(凍肉),beer(啤酒),
wine(酒類)����,softdrink(軟飲),fish(魚),
confectionery(甜食)�。如何對這些數(shù)據(jù)進行分析和處理,本節(jié)會給出詳細的演示�����。
在做詳細介紹以前�,讓我們先了解下
IBM SPSS Modeler 的建模過程,關(guān)于詳細的過程�,可以參考本文給出的參考資料。IBM SPSS Modeler
中處理的基本對象是流����,在流中可以添加數(shù)據(jù)節(jié)點、類型節(jié)點���、建模節(jié)點等�����,運行后會生成模型節(jié)點�����,進而對模型節(jié)點進行分析�,得出結(jié)論。
現(xiàn)在讓我們開始介紹如何創(chuàng)建一條包含關(guān)聯(lián)規(guī)則模型的流�,來解決市場分析員的問題。本節(jié)使用 IBM SPSS Modeler 14.2 進行演示��。首先打開 Modeler 產(chǎn)品�,會出現(xiàn)一張空白的流界面��,這時用戶可以在里面創(chuàng)建自己的流�。
圖 2. IBM SPSS Modeler 界面
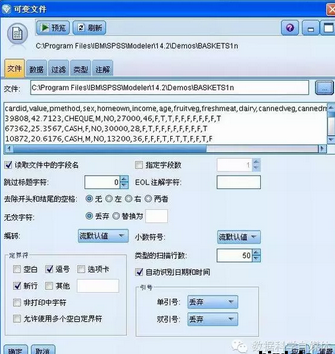
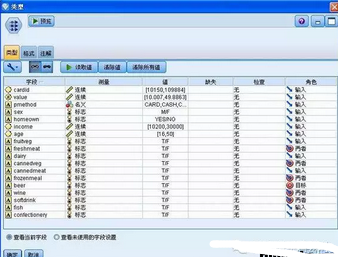
第一步,為流添加一個數(shù)據(jù)節(jié)點���,這里選擇 Modeler 自帶的 Demo 數(shù)據(jù)�。將界面下方選項卡的“源”選項中的“可變文件”拖放到空白界面中���,雙擊打開��,在文件選項卡中選擇 Modeler 自帶的 Demo 數(shù)據(jù) BASKETS1n����,如圖所示。
圖 3. 選擇添加數(shù)據(jù)節(jié)點
點擊確定按鈕���,這時就成功的創(chuàng)建了數(shù)據(jù)節(jié)點�����。
第二步���,為流添加類型節(jié)點,類型節(jié)點是顯示和設(shè)置數(shù)據(jù)每個字段的類型��、格式和角色�。從界面下方的“字段選項”卡中,將“類型”節(jié)點拖放到界面中����,接著將數(shù)據(jù)節(jié)點和類型節(jié)點連接起來,或者直接在“字段選項”卡中雙擊“類型”節(jié)點��,將兩者連接起來��。這時雙擊打開“類型”節(jié)點��,此時“類型”節(jié)點中顯示了數(shù)據(jù)的字段和其類型,點擊“類型”節(jié)點界面上的“讀取值”按鈕��,這時會將數(shù)據(jù)節(jié)點中的數(shù)據(jù)讀取過來����。如下圖所示。
圖 4. 設(shè)置類型節(jié)點
接著可以為參與建模的數(shù)據(jù)字段設(shè)置角色��,角色分“輸入”���,“目標(biāo)”����,“兩者”和“無”�。輸入表示該字段可供建模使用����,目標(biāo)表示該字段為建模的預(yù)測目標(biāo),兩者表示該字段為布爾型的輸入字段�,無表示該字段不參與建模。Apriori
節(jié)點需要一個或多個輸入字段和一個或多個目標(biāo)字段����,輸入字段和輸出字段必須是符號型字段�����。在此可以選擇一個或多個字段為目標(biāo)字段�����,表明該模型的預(yù)測目標(biāo)字段�;對于
Apriori 建模節(jié)點���,也可以不設(shè)置目標(biāo)字段�,則需要在建模節(jié)點中設(shè)置“后項”�。
第三步,為流添加 過濾節(jié)點�����,將不參與的字段排除在外��。該步驟為可選步驟���。從“字段選項”卡中選擇“過濾”節(jié)點���,并將其拖入到界面中����,將“過濾”節(jié)點加入到流中��。雙擊打開“過濾”節(jié)點����,在不參與建模字段的箭頭上點擊,會出現(xiàn)一個紅叉����,表示該字段被過濾掉了,不參與建模�����,如圖所示���。
圖 5. 設(shè)置過濾節(jié)點
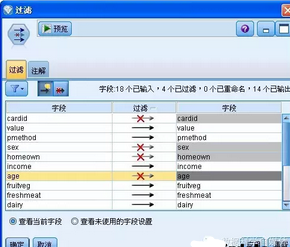
對于一些與建模關(guān)系不大的節(jié)點可以將其過濾掉���,比如卡號����、性別����、家鄉(xiāng)和年齡字段����。
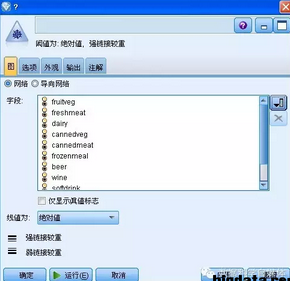
第四步,有了這些前期的準(zhǔn)備過程����,接下來就可以開始創(chuàng)建關(guān)聯(lián)規(guī)則模型節(jié)點了,在此之前����,讓我們先添加一個圖形節(jié)點—— 網(wǎng)絡(luò)節(jié)點,建立此節(jié)點的目的是為了讓用戶首先可以直觀的看到商品之間的關(guān)聯(lián)程度���,有一個感性認識�����。選擇“圖形”選項卡中的“網(wǎng)絡(luò)”節(jié)點�����,將此拖入界面��,將“網(wǎng)絡(luò)”節(jié)點加入流中���,與“過濾”節(jié)點連接起來�����。雙擊打開網(wǎng)絡(luò)節(jié)點�����,在“字段”列表中選擇添加字段�,可以將所有的商品字段添加進來�����;也可以點擊“僅顯示真值標(biāo)志”����,將只顯示那些“兩者”的字段,如圖所示����。
圖 6. 網(wǎng)絡(luò)節(jié)點設(shè)置
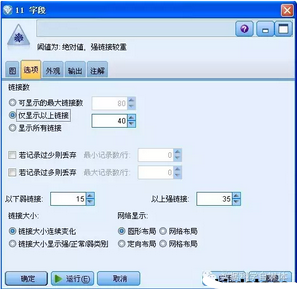
點擊“選項”卡����,進入選項設(shè)置����,用戶可以在此設(shè)置鏈接數(shù)量的顯示范圍��,不顯示一些鏈接數(shù)量低的鏈接��,如圖所示�����。
圖 7. 網(wǎng)絡(luò)節(jié)點選項設(shè)置
點擊“運行”按鈕���,這時會生成一個商品之間關(guān)聯(lián)程度(鏈接數(shù)量)的網(wǎng)絡(luò)圖��,用戶可以在下方的調(diào)節(jié)桿上調(diào)節(jié)鏈接數(shù)量的顯示范圍�����。
圖 8. 網(wǎng)絡(luò)節(jié)點運行結(jié)果
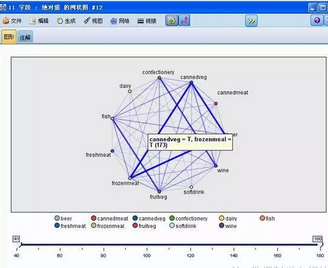
上圖中�����,線的粗細和深淺代表聯(lián)系的強弱��,可以直觀的看到 beer 和 frozenmeat�����,cannedeg 聯(lián)系程度比較強��。接下來將開始本章節(jié)的重點部分��,關(guān)聯(lián)規(guī)則模型節(jié)點的設(shè)置和使用�。
第五步,添加“建?����!惫?jié)點到流中�,開始關(guān)聯(lián)規(guī)則模型設(shè)置和使用的篇章。首先點擊界面下方“建?����!边x項卡��,再點擊“關(guān)聯(lián)”分類���,將
Apriori 節(jié)點拖放到界面中��,連接該節(jié)點到過濾節(jié)點上�����,或者雙擊 Apriori 節(jié)點��。接著設(shè)置 Apriori
節(jié)點的參數(shù)�����,建立關(guān)聯(lián)規(guī)則模型����。雙擊打開 Apriori 節(jié)點�,如下圖所示。
圖 9. Apriori 建模節(jié)點
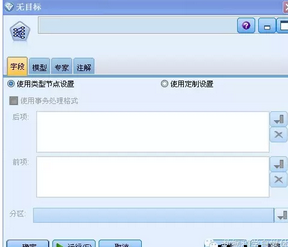
該“字段”選項卡�����,是設(shè)置參與建模的字段和目標(biāo)字段的���,可以看到其中包括兩個選項����,“使用類型節(jié)點設(shè)置”和“使用定制設(shè)置”,這里將為用戶分別呈現(xiàn)兩種選項的使用方法�����。這里無論選擇哪個選項��,都需要將市場分析員重點關(guān)注的商品包括在其中����,其他商品可以不包括。
如果用戶選擇“使用類型節(jié)點設(shè)置”選項�,則需要雙擊打開“類型”節(jié)點,將啤酒設(shè)置為目標(biāo)�,將其他重點關(guān)注的商品設(shè)置為兩者或輸入,其他無用字段可以設(shè)置為無或輸入���,如下圖所示��。
圖 10. 設(shè)置字段當(dāng)選擇“使用類型節(jié)點設(shè)置”
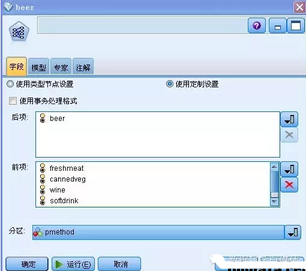
如果用戶選擇“使用定制設(shè)置”選項�,則需要將啤酒設(shè)置在“后項”列表中���,將其他重點關(guān)注的商品設(shè)置在“前項”列表中�,如下圖所示。
圖11. 設(shè)置字段當(dāng)選擇“使用定制設(shè)置”
這里�,分區(qū)允許您使用指定字段將數(shù)據(jù)分割為幾個不同的樣本,分別用于模型構(gòu)建過程中的訓(xùn)練���、測試和驗證階段����。如果設(shè)置了“分區(qū)”����,除了在此選擇分區(qū)字段外��,還需要在“模型”選項卡中���,勾上“使用分區(qū)數(shù)據(jù)”的選擇框����。關(guān)于“分區(qū)”的概念���、作用和使用方法��,本文不做詳細介紹��。
除此��,“使用事務(wù)處理格式”選擇框����,是針對于事務(wù)性數(shù)據(jù)的,如果數(shù)據(jù)為交易格式�����,需要勾上此選擇框�,但本示例的數(shù)據(jù)為表格格式,故無需選擇����。
設(shè)置好了字段后,點擊“模型”選項卡��,進入模型設(shè)置��。如下圖所示����。
圖 12. 設(shè)置模型選項卡
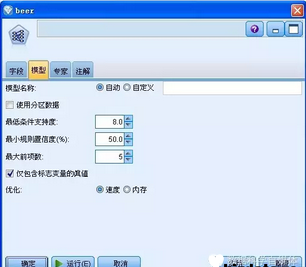
用戶可以在“模型名稱”處為本模型設(shè)置一個名字,如果想使用分區(qū)功能,則需要勾上“使用分區(qū)數(shù)據(jù)”選項����。
用戶為規(guī)則模型設(shè)置一個 最低條件支持度,那么模型將從所有規(guī)則中選擇那些為真�����,并且其對應(yīng)的記錄的百分比大于此值的規(guī)則���。如果您獲得的規(guī)則適用于非常小的數(shù)據(jù)子集���,請嘗試增加此設(shè)置。
接著�,用戶需要為模型設(shè)置一個 最小規(guī)則置信度��,表明正確預(yù)測的百分比����。置信度低于指定標(biāo)準(zhǔn)的規(guī)則將被放棄。如果您獲得的規(guī)則太多�����,請嘗試增加此設(shè)置。如果您獲得的規(guī)則太少(甚至根本無法獲得規(guī)則)����,請嘗試降低此設(shè)置。
用戶還可以為任何規(guī)則指定“最大前項數(shù)”��。這是一種用來限制規(guī)則復(fù)雜性的方式����。如果規(guī)則太復(fù)雜或者太具體,請嘗試降低此設(shè)置�。
對于“僅包含標(biāo)志變量的真值”選項,如果對于表格格式的數(shù)據(jù)選擇了此選項�����,則在生成的規(guī)則中只會出現(xiàn)真值�����。這樣使得規(guī)則更容易理解���。該選項不適用于事務(wù)格式的數(shù)據(jù)�����。
為了提高建模性能�����,設(shè)置了“優(yōu)化”選項供用戶選擇����。選擇“速度”可指示算法從不使用磁盤溢出,以便提高性能�。選擇“內(nèi)存”可指示算法在合適的時候,以犧牲某些速度為代價使用磁盤溢出��。
接下來�,進入“專家”選項卡,對于一般用戶�����,則選擇“簡單”選項;而對于高級用戶���,則可以通過此頁面進行微調(diào)�,如下圖所示�。
圖 13. 專家選項卡設(shè)置
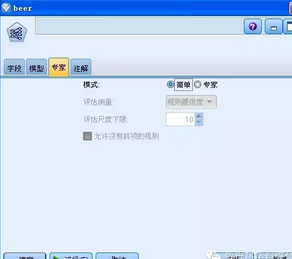
關(guān)于“專家”選項的設(shè)置和介紹,請參見 IBM SPSS Modeler 幫助文檔。
此時�����,我們已經(jīng)創(chuàng)建好了關(guān)聯(lián)規(guī)則模型的整個流�����,點擊工具欄的綠色箭頭�����,運行該流��,會生成一個“模型”節(jié)點����,該節(jié)點里包含了模型運行結(jié)果。整個運行后的流圖����,如下圖所示。
圖 14. 關(guān)聯(lián)規(guī)則模型流圖
第六步�����,在得到了運行結(jié)果后,我們雙擊打開生成的“模型”節(jié)點����,點擊“顯示 / 隱藏標(biāo)準(zhǔn)菜單”下拉框,選擇“顯示所有”�,結(jié)果如下圖所示��。
圖 15. 模型節(jié)點信息
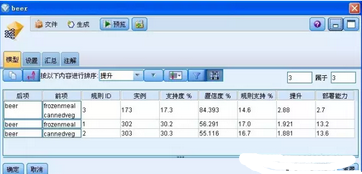
從結(jié)果可以看出�����,通過關(guān)聯(lián)規(guī)則模型挖掘出了三個規(guī)則,分別是規(guī)則一�����,購買了凍肉(frozenmeal)和罐裝蔬菜(cannedveg)的顧客都會購買啤酒(beer)��;規(guī)則二�,購買了凍肉的顧客都會購買啤酒�;規(guī)則三�,購買了罐裝蔬菜的顧客都會購買啤酒���。其中,第一列代表結(jié)果���,而下一列代表條件,后面的列包含規(guī)則信息��,如置信度�、支持度和提升等。
市場分析員對于模型結(jié)果的三條規(guī)則和規(guī)則信息��,如何分析得出結(jié)論呢��?首先分析第一條規(guī)則��,購買了凍肉和罐裝蔬菜的顧客會購買啤酒��,此規(guī)則中購買了凍肉和罐裝蔬菜的記錄有
173 條����,占 17.3%,同時購買了凍肉��、罐裝蔬菜和啤酒的記錄占 14.6%�,而在購買了凍肉和罐裝蔬菜的顧客中會有 84.393%
的顧客會購買啤酒����,并且提升為
2.88����,表明此規(guī)則的相關(guān)性很強,部署能力和置信度類似��,可以不考慮���。對于規(guī)則二三��,可以同樣分析�。問題的關(guān)鍵是���,哪些規(guī)則信息才能作為評判標(biāo)準(zhǔn)�����。通過對規(guī)則信息的分析和了解��,建議將置信度和提升作為選擇規(guī)則的標(biāo)準(zhǔn)��,因為置信度能反映出規(guī)則預(yù)測的準(zhǔn)確程度��,提升值越大����,規(guī)則的相關(guān)性越強�。據(jù)此,可以將規(guī)則一作為分析結(jié)果��。
因此可以將啤酒和凍肉����、罐裝蔬菜放在一起銷售,這也正好和前面的網(wǎng)絡(luò)節(jié)點圖的顯示相一致�。
總結(jié)
本文通過一個實際的商業(yè)場景,引入了
IBM SPSS Modeler
關(guān)聯(lián)規(guī)則模型�����,首先給出了關(guān)聯(lián)規(guī)則的相關(guān)概念���,接著帶領(lǐng)您一步一步的創(chuàng)建了數(shù)據(jù)流�,并且介紹了模型的建立和設(shè)置��,并且對結(jié)果進行了分析��。您可以將本模型應(yīng)用到其他的場景中,如網(wǎng)絡(luò)日志分析���、銀行潛在客戶分析�����、電子商務(wù)的捆綁銷售等����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330