一文搞定數(shù)據(jù)科學(xué)和機器學(xué)習(xí)的最常見面試題
去的幾個月中����,我參加了一些公司數(shù)據(jù)科學(xué)�、機器學(xué)習(xí)等方向初級崗位的面試��。
我面試的這些崗位和數(shù)據(jù)科學(xué)�����、常規(guī)機器學(xué)習(xí)還有專業(yè)的自然語言處理�����、計算機視覺相關(guān)����。我參加了亞馬遜、三星�、優(yōu)步、華為等大公司的面試��,除此之外還有一些初創(chuàng)公司的面試����。這些初創(chuàng)公司有些處于啟動階段,也有些已經(jīng)成型并得到投資�����。
簡單介紹一下我的背景:在校期間攻讀機器學(xué)習(xí)和計算機視覺的碩士學(xué)位,主要進(jìn)行學(xué)術(shù)方面的研究�����,但是有在一家早期初創(chuàng)公司(和ML無關(guān))實習(xí)八個月的經(jīng)歷���。
今天我想跟你們分享我在面試中被問到的問題����,以及如去何解答�。其中一部分問題很常見,旨在考察你的理論知識儲備���。但也有一些問題頗具創(chuàng)意��,非常有意思����。我將把常見的問題簡單列出來�����,不多做解釋���,因為網(wǎng)上有許多資料可以參考��。比較罕見��、棘手的問題��,我會深入探討一下���。希望你讀完這篇文章后,可以在機器學(xué)習(xí)的面試中表現(xiàn)出色�,獲得自己滿意的工作。
首先來看一些常見的理論問題:
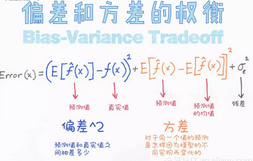
什么是偏差-方差之間的權(quán)衡?
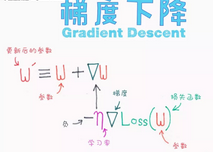
什么是梯度下降?
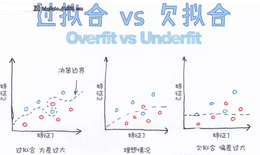
請解釋過擬合和欠擬合�。如何應(yīng)對這兩種情況?
如何解決維數(shù)災(zāi)難問題?

什么是正則化?為什么要正則化?請給出一些正則化常用方法。

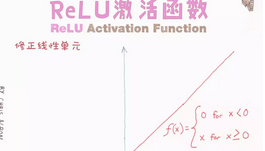
為什么在神經(jīng)網(wǎng)絡(luò)中���,ReLU是比Sigmoid更好�、更常用的激活函數(shù)?
數(shù)據(jù)規(guī)范化是什么?為什么需要對數(shù)據(jù)進(jìn)行規(guī)范化?
我覺得這個問題很重要��,值得強調(diào)�。數(shù)據(jù)規(guī)范化在預(yù)處理階段尤為重要,它可以將數(shù)值縮放到特定的范圍��,以在反向傳播時獲得更好的收斂性。一般而言�,規(guī)范化就是讓每一個數(shù)據(jù)點減去它們的均值,并除以標(biāo)準(zhǔn)差��。
如果不這樣處理�,一些(數(shù)量級較大的)特征值在代價函數(shù)中的權(quán)重就會更大(如果大數(shù)量級特征值改變1%,代價函數(shù)的變化就會很大��,但小數(shù)量級的特征值改變1%產(chǎn)生的影響則微乎其微)�����。規(guī)范化使得所有特征值具有相同的權(quán)重��。
請解釋降維�,以及使用場合和它的優(yōu)勢。
降維是一種通過分析出主變量來減少特征變量的過程�����,其中主變量通常就是重要的特征�����。一個特征變量的重要性取決于它對數(shù)據(jù)信息的解釋程度��,以及你所采用的方法����。至于如何選取方法,主要靠不斷摸索��,以及你自己的偏好���。通常大家會從線性方法開始���,如果結(jié)果欠缺擬合性,則考慮嘗試非線性的方法�����。
數(shù)據(jù)降維的優(yōu)勢有以下幾點:(1)節(jié)省存儲空間;(2)節(jié)省計算時間(比如應(yīng)用于機器學(xué)習(xí)算法時);(3)去除冗余特征變量�����,正如同時以平方米和平方英里存儲地區(qū)面積沒有任何意義(甚至可能是收集數(shù)據(jù)時出現(xiàn)錯誤);(4)將數(shù)據(jù)降維到二維或三維后�����,我們或許可以畫圖,將數(shù)據(jù)可視化���,以觀察數(shù)據(jù)具有的模式�,獲得對數(shù)據(jù)的直觀感受;(5)特征變量過多或模型過于復(fù)雜可能導(dǎo)致模型過擬合�。
如何處理數(shù)據(jù)集中缺失或損壞的數(shù)據(jù)?
你可以在數(shù)據(jù)集中找到缺失/損壞的數(shù)據(jù),并刪除它所在的行或列�����,或是用其他值代替之��。Pandas中有兩個非常有效的函數(shù):isnull()和dropna()�,這兩個函數(shù)可以幫你找到有缺失/損壞數(shù)據(jù)的行,并刪除對應(yīng)值�。如果要用占位符(比如0)填充這些無效值,你可以使用fillna()函數(shù)���。
請解釋一下某種聚類算法���。
我寫了一篇熱門文章《數(shù)據(jù)科學(xué)家應(yīng)當(dāng)知曉的5種聚類算法》,詳盡細(xì)致討論了這些算法��,文章的可視化也很棒�。(可以自行百度搜索)
如何開展探索性數(shù)據(jù)分析(EDA)?
EDA的目的是在應(yīng)用預(yù)測模型之前,了解數(shù)據(jù)的信息,獲得對數(shù)據(jù)的直觀感受�����?����?偟膩碚f�,開展探索性數(shù)據(jù)分析一般采取由粗到精的方法��。我們首先獲取一些高層次����、全局性的直觀感受。檢查一下不平衡的類����,查看每一類的均值和方差?����?纯吹谝恍?����,了解數(shù)據(jù)大致內(nèi)容。
運行pandas中的df.info()函數(shù)�,看看哪些是連續(xù)變量、分類變量���,并查看變量的數(shù)據(jù)類型(整型����、浮點型�����、字符串)����。然后刪掉一些在分析、預(yù)測中不需要的列����,這些列中的很多行數(shù)值都相同(提供的信息也相同),或者存在很多缺失值��。我們也可以用某一行/列的眾數(shù)或中值填充該行/列中的缺失值�����。
此外可以做一些基本的可視化操作。從相對高層次�、全局性的角度開始,比如繪制分類特征關(guān)于類別的條形圖��,繪制最終類別的條形圖����,探究一下最“常用”的特征����,對獨立變量進(jìn)行可視化以獲得一些認(rèn)知和靈感等。
接下來可以展開更具體的探索����。比如同時對兩三個特征進(jìn)行可視化,看看它們相互有何聯(lián)系����。也可以做主成分分析,來確定哪些特征中包含的信息最多���。類似地��,還可以將一些特征分組�,以觀察組間聯(lián)系。
比如可以考察一下�����,取A = B = 0時�,不同的類會有什么表現(xiàn)?取A = 1、B = 0時呢?還要比較一下不同特征的影響����,比方說特征A可以取“男性”或“女性”,則可以畫出特征A與旅客艙位的關(guān)系圖���,判斷男性和女性選在艙位選擇上是否有差異��。
除了條形圖���、散點圖或是其他基本圖表,也可以畫出PDF(概率分布函數(shù))或CDF(累計分布函數(shù))�、使用重疊繪圖方法等。還可以考察一下統(tǒng)計特性���,比如分布�����、p值等�����。最后就該建立機器學(xué)習(xí)模型了����。
從簡單的模型開始,比如樸素貝葉斯��、線性回歸等�。如果上述模型效果不理想����,或是數(shù)據(jù)高度非線性,則考慮使用多項式回歸�、決策樹或支持向量機。EDA可以挑選出重要的特征���。如果數(shù)據(jù)量很大����,可以使用神經(jīng)網(wǎng)絡(luò)。別忘了檢查ROC曲線(感受性曲線)�、準(zhǔn)確率和召回率。
怎么知道應(yīng)當(dāng)選取何種機器學(xué)習(xí)模型?
雖然人們應(yīng)當(dāng)堅信天下沒有免費的午餐�,但還是有一些指導(dǎo)原則相當(dāng)通用。我在一篇文章里寫了如何選取合適的回歸模型����,還有一篇備忘錄也很棒!
為什么對圖像使用卷積而不只是FC層?
這個問題比較有趣,因為提出這個問題的公司并不多���。恰巧����,在一家專攻計算機視覺的公司的面試中�����,我被問到這個問題���。答案應(yīng)分成兩部分:首先�,卷積可以保存���、編碼��、使用圖像的空間信息�����。只用FC層的話可能就沒有相關(guān)空間信息了�����。其次�����,卷積神經(jīng)網(wǎng)絡(luò)(CNN)某種程度上本身具有平移不變性���,因為每個卷積核都充當(dāng)了它自己的濾波器/特征監(jiān)測器����。
為什么CNN具有平移不變性?
上文解釋過����,每個卷積核都充當(dāng)了它自己的濾波器/特征監(jiān)測器����。假設(shè)你正在進(jìn)行目標(biāo)檢測����,這個目標(biāo)處于圖片的何處并不重要�����,因為我們要以滑動窗口的方式�����,將卷積應(yīng)用于整個圖像����。
為什么用CNN分類需要進(jìn)行最大池化?
這也是屬于計算機視覺領(lǐng)域的一個問題。CNN中的最大池化可以減少計算量�����,因為特征圖在池化后將會變小����。與此同時,因為采取了最大池化��,并不會喪失太多圖像的語義信息。還有一個理論認(rèn)為��,最大池化有利于使CNN具有更好的平移不變性��。關(guān)于這個問題�����,可以看一下吳恩達(dá)講解最大池化優(yōu)點的視頻��。
為什么用CNN分割時通常需要編碼-解碼結(jié)構(gòu)?
CNN編碼器可以看作是特征提取網(wǎng)絡(luò)��,解碼器則利用它提供的信息���,“解碼”特征并放大到原始大小��,以此預(yù)測圖像片段�。
殘差網(wǎng)絡(luò)有什么意義?
殘差網(wǎng)絡(luò)主要能夠讓它之前的層直接訪問特征�,這使得信息在網(wǎng)絡(luò)中更易于傳播。一篇很有趣的論文解釋了本地的跳躍式傳導(dǎo)如何賦予網(wǎng)絡(luò)多路徑結(jié)構(gòu)�,使得特征能夠以不同路徑在整個網(wǎng)絡(luò)中傳播。
批量標(biāo)準(zhǔn)化是什么?它為什么有效?
訓(xùn)練深層神經(jīng)網(wǎng)絡(luò)很復(fù)雜�,因為在訓(xùn)練過程中���,隨著前幾層輸入的參數(shù)不斷變化�,每層輸入的分布也隨之變化。一種方法是將每層輸入規(guī)范化��,輸出函數(shù)均值為0���,標(biāo)準(zhǔn)差為1���。對每一層的每個小批量輸入都采用上述方式進(jìn)行規(guī)范化(計算每個小批量輸入的均值和方差,然后標(biāo)準(zhǔn)化)�����。這和神經(jīng)網(wǎng)絡(luò)的輸入的規(guī)范化類似����。
批量標(biāo)準(zhǔn)化有什么好處?我們知道,對輸入進(jìn)行規(guī)范化有助于神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)��。但神經(jīng)網(wǎng)絡(luò)不過是一系列的層����,每層的輸出又成為下一層的輸入。也就是說�����,我們可以將其中每一層視作子網(wǎng)絡(luò)的第一層。把神經(jīng)網(wǎng)絡(luò)想象成一系列互相傳遞信息的網(wǎng)絡(luò)結(jié)構(gòu)�����,因此在激活函數(shù)作用于輸出之前����,先將每一層輸出規(guī)范化,再將其傳遞到下一層(子網(wǎng)絡(luò))�。
如何處理不平衡數(shù)據(jù)集?
關(guān)于這個問題我寫了一篇文章,請查看文章中第三個小標(biāo)題����。
為什么要使用許多小卷積核(如3*3的卷積核),而非少量大卷積核?
這篇VGGNet的論文中有很詳細(xì)的解釋�。有兩個原因:首先,同少數(shù)大卷積核一樣����,更多小卷積核也可以得到相同的感受野和空間背景,而且用小卷積核需要的參數(shù)更少�、計算量更小。其次��,使用小卷積核需要更多過濾器��,這意味會使用更多的激活函數(shù)��,因此你的CNN可以得到更具特異性的映射函數(shù)�。
你有和我們公司相關(guān)的項目經(jīng)歷嗎?
在回答這個問題時,你需要把自己的研究和他們的業(yè)務(wù)的聯(lián)系起來��。想想看你是否做過什么研究�,或?qū)W過什么技能,能和公司業(yè)務(wù)及你申請的崗位有所聯(lián)系���。這種經(jīng)歷不需要百分之百符合所申請的崗位����,只要在某種程度上有關(guān)聯(lián)����,這些經(jīng)歷就會成為你很大的加分項。
請介紹一下你目前的碩士研究項目�。哪些項目和申請崗位有關(guān)聯(lián)?未來發(fā)展方向是什么?
這個問題的答案同上,你懂的

結(jié)論
以上就是所有我在應(yīng)聘數(shù)據(jù)科學(xué)和機器學(xué)習(xí)相關(guān)崗位時被問到的問題����。希望你喜歡這篇文章����,并從中獲益��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330