python編寫分類決策樹的代碼
決策樹通常在機器學習中用于分類�。
優(yōu)點:計算復雜度不高,輸出結果易于理解����,對中間值缺失不敏感,可以處理不相關特征數據�。
缺點:可能會產生過度匹配問題。
適用數據類型:數值型和標稱型��。
1.信息增益
劃分數據集的目的是:將無序的數據變得更加有序��。組織雜亂無章數據的一種方法就是使用信息論度量信息���。通常采用信息增益���,信息增益是指數據劃分前后信息熵的減少值�。信息越無序信息熵越大����,獲得信息增益最高的特征就是最好的選擇。
熵定義為信息的期望���,符號xi的信息定義為:
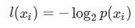
其中p(xi)為該分類的概率�����。
熵����,即信息的期望值為:
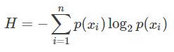
計算信息熵的代碼如下:
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts:
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0
for key in labelCounts:
shannonEnt = shannonEnt - (labelCounts[key]/numEntries)*math.log2(labelCounts[key]/numEntries)
return shannonEnt
可以根據信息熵�,按照獲取最大信息增益的方法劃分數據集。
2.劃分數據集
劃分數據集就是將所有符合要求的元素抽出來����。
def splitDataSet(dataSet,axis,value):
retDataset = []
for featVec in dataSet:
if featVec[axis] == value:
newVec = featVec[:axis]
newVec.extend(featVec[axis+1:])
retDataset.append(newVec)
return retDataset
3.選擇最好的數據集劃分方式
信息增益是熵的減少或者是信息無序度的減少��。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
bestInfoGain = 0
bestFeature = -1
baseEntropy = calcShannonEnt(dataSet)
for i in range(numFeatures):
allValue = [example[i] for example in dataSet]#列表推倒����,創(chuàng)建新的列表
allValue = set(allValue)#最快得到列表中唯一元素值的方法
newEntropy = 0
for value in allValue:
splitset = splitDataSet(dataSet,i,value)
newEntropy = newEntropy + len(splitset)/len(dataSet)*calcShannonEnt(splitset)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
4.遞歸創(chuàng)建決策樹
結束條件為:程序遍歷完所有劃分數據集的屬性���,或每個分支下的所有實例都具有相同的分類。
當數據集已經處理了所有屬性�,但是類標簽還不唯一時,采用多數表決的方式決定葉子節(jié)點的類型�。
def majorityCnt(classList):
classCount = {}
for value in classList:
if value not in classCount: classCount[value] = 0
classCount[value] += 1
classCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return classCount[0][0]
生成決策樹:
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
labelsCopy = labels[:]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeature = chooseBestFeatureToSplit(dataSet)
bestLabel = labelsCopy[bestFeature]
myTree = {bestLabel:{}}
featureValues = [example[bestFeature] for example in dataSet]
featureValues = set(featureValues)
del(labelsCopy[bestFeature])
for value in featureValues:
subLabels = labelsCopy[:]
myTree[bestLabel][value] = createTree(splitDataSet(dataSet,bestFeature,value),subLabels)
return myTree
5.測試算法——使用決策樹分類
同樣采用遞歸的方式得到分類結果。
def classify(inputTree,featLabels,testVec):
currentFeat = list(inputTree.keys())[0]
secondTree = inputTree[currentFeat]
try:
featureIndex = featLabels.index(currentFeat)
except ValueError as err:
print('yes')
try:
for value in secondTree.keys():
if value == testVec[featureIndex]:
if type(secondTree[value]).__name__ == 'dict':
classLabel = classify(secondTree[value],featLabels,testVec)
else:
classLabel = secondTree[value]
return classLabel
except AttributeError:
print(secondTree)
6.完整代碼如下
import numpy as np
import math
import operator
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no'],]
label = ['no surfacing','flippers']
return dataSet,label
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts:
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0
for key in labelCounts:
shannonEnt = shannonEnt - (labelCounts[key]/numEntries)*math.log2(labelCounts[key]/numEntries)
return shannonEnt
def splitDataSet(dataSet,axis,value):
retDataset = []
for featVec in dataSet:
if featVec[axis] == value:
newVec = featVec[:axis]
newVec.extend(featVec[axis+1:])
retDataset.append(newVec)
return retDataset
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
bestInfoGain = 0
bestFeature = -1
baseEntropy = calcShannonEnt(dataSet)
for i in range(numFeatures):
allValue = [example[i] for example in dataSet]
allValue = set(allValue)
newEntropy = 0
for value in allValue:
splitset = splitDataSet(dataSet,i,value)
newEntropy = newEntropy + len(splitset)/len(dataSet)*calcShannonEnt(splitset)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
classCount = {}
for value in classList:
if value not in classCount: classCount[value] = 0
classCount[value] += 1
classCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return classCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
labelsCopy = labels[:]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeature = chooseBestFeatureToSplit(dataSet)
bestLabel = labelsCopy[bestFeature]
myTree = {bestLabel:{}}
featureValues = [example[bestFeature] for example in dataSet]
featureValues = set(featureValues)
del(labelsCopy[bestFeature])
for value in featureValues:
subLabels = labelsCopy[:]
myTree[bestLabel][value] = createTree(splitDataSet(dataSet,bestFeature,value),subLabels)
return myTree
def classify(inputTree,featLabels,testVec):
currentFeat = list(inputTree.keys())[0]
secondTree = inputTree[currentFeat]
try:
featureIndex = featLabels.index(currentFeat)
except ValueError as err:
print('yes')
try:
for value in secondTree.keys():
if value == testVec[featureIndex]:
if type(secondTree[value]).__name__ == 'dict':
classLabel = classify(secondTree[value],featLabels,testVec)
else:
classLabel = secondTree[value]
return classLabel
except AttributeError:
print(secondTree)
if __name__ == "__main__":
dataset,label = createDataSet()
myTree = createTree(dataset,label)
a = [1,1]
print(classify(myTree,label,a))
7.編程技巧
extend與append的區(qū)別
newVec.extend(featVec[axis+1:])
retDataset.append(newVec)
extend([])���,是將列表中的每個元素依次加入新列表中
append()是將括號中的內容當做一項加入到新列表中
列表推到
創(chuàng)建新列表的方式
allValue = [example[i] for example in dataSet]
提取列表中唯一的元素
allValue = set(allValue)
列表/元組排序,sorted()函數
classCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
列表的復制
labelsCopy = labels[:]
以上就是本文的全部內容��,希望對大家的學習有所幫助.
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330