Python實現(xiàn)的堆排序算法原理與用法實例分析
本文實例講述了Python實現(xiàn)的堆排序算法。分享給大家供大家參考�����,具體如下:
堆排序(Heapsort)是指利用堆這種數(shù)據(jù)結(jié)構(gòu)所設(shè)計的一種排序算法。堆是一個近似完全二叉樹的結(jié)構(gòu),并同時滿足堆性質(zhì):即子結(jié)點的鍵值或索引總是小于(或者大于)它的父節(jié)點���。
具體代碼如下:
#-*- coding: UTF-8 -*-
import numpy as np
def MakeHeap(a):
for i in xrange(a.size / 2 - 1, -1, -1):#對非葉子節(jié)點的子節(jié)點進行調(diào)節(jié)�,構(gòu)建堆
AdjustHeap(a, i, a.size)
def AdjustHeap(a, i, n):
j = i*2 +1 #選擇節(jié)點i的左子節(jié)點
x = a[i] #選擇節(jié)點的數(shù)值
while j < n: #循環(huán)對子節(jié)點及其子樹進行調(diào)整
if j + 1 < n and a[j+1] < a[j]: #找到節(jié)點i子節(jié)點的最小值
j += 1
if a[j] >= x : #若兩個子節(jié)點均不小于該節(jié)點,則不同調(diào)整
break
a[i], a[j] = a[j], a[i] #將節(jié)點i的數(shù)值與其子節(jié)點中最小者的數(shù)值進行對調(diào)
i = j #將i賦為改變的子節(jié)點的索引
j = i*2 + 1 #將j賦為節(jié)點對應的左子節(jié)點
def HeapSort(a):
MakeHeap(a) #構(gòu)建小頂堆
for i in xrange(a.size - 1,0, -1): #對堆中的元素逆向遍歷
a[i], a[0] = a[0], a[i] #將堆頂元素與堆中最后一個元素進行對調(diào)��,因為小頂堆中堆頂元素永遠最小,因此�,輸出即為最小元素
AdjustHeap(a, 0, i) #重新調(diào)整使剩下的元素仍為一個堆
if __name__ == '__main__':
a = np.random.randint(0, 10, size = 10)
print "Before sorting..."
print "---------------------------------------------------------------"
print a
print "---------------------------------------------------------------"
HeapSort(a)
print "After sorting..."
print "---------------------------------------------------------------"
print a[::-1] #因為堆排序按大到小進行排列,采用a[::-1]對其按從小到大進行輸出
print "---------------------------------------------------------------"
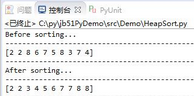
運行結(jié)果:
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330