機(jī)器學(xué)習(xí)案例實(shí)戰(zhàn)-信用卡欺詐檢測(cè)
故事背景:原始數(shù)據(jù)為個(gè)人交易記錄�����,但是考慮數(shù)據(jù)本身的隱私性���,已經(jīng)對(duì)原始數(shù)據(jù)進(jìn)行了類似PCA的處理��,現(xiàn)在已經(jīng)把特征數(shù)據(jù)提取好了�����,接下來(lái)的目的就是如何建立模型使得檢測(cè)的效果達(dá)到最好�����,這里我們雖然不需要對(duì)數(shù)據(jù)做特征提取的操作,但是面對(duì)的挑戰(zhàn)還是蠻大的��。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
數(shù)據(jù)分析與建模可不是體力活�,時(shí)間就是金錢(qián)我的朋友(魔獸玩家都懂的!)如果你用python來(lái)把玩數(shù)據(jù)���,那么這些就是你的核武器啦�����。簡(jiǎn)單介紹一下這幾位朋友�����!
Numpy-科學(xué)計(jì)算庫(kù)主要用來(lái)做矩陣運(yùn)算�,什么��?你不知道哪里會(huì)用到矩陣��,那么這樣想吧�����,咱們的數(shù)據(jù)就是行(樣本)和列(特征)組成的��,那么數(shù)據(jù)本身不就是一個(gè)矩陣嘛。
Pandas-數(shù)據(jù)分析處理庫(kù)很多小伙伴都在說(shuō)用python處理數(shù)據(jù)很容易���,那么容易在哪呢�?其實(shí)有了pandas很復(fù)雜的操作我們也可以一行代碼去解決掉��!
Matplotlib-可視化庫(kù)無(wú)論是分析還是建模����,光靠好記性可不行,很有必要把結(jié)果和過(guò)程可視化的展示出來(lái)��。
Scikit-Learn-機(jī)器學(xué)習(xí)庫(kù)非常實(shí)用的機(jī)器學(xué)習(xí)算法庫(kù)��,這里面包含了基本你覺(jué)得你能用上所有機(jī)器學(xué)習(xí)算法啦�。但還遠(yuǎn)不止如此,還有很多預(yù)處理和評(píng)估的模塊等你來(lái)挖掘的�����!
data = pd.read_csv("creditcard.csv")
data.head()

首先我們用pandas將數(shù)據(jù)讀進(jìn)來(lái)并顯示最開(kāi)始的5行���,看見(jiàn)木有����!用pandas讀取數(shù)據(jù)就是這么簡(jiǎn)單!這里的數(shù)據(jù)為了考慮用戶隱私等�����,已經(jīng)通過(guò)PCA處理過(guò)了�,現(xiàn)在大家只需要把數(shù)據(jù)當(dāng)成是處理好的特征就好啦�!
接下來(lái)我們核心的目的就是去檢測(cè)在數(shù)據(jù)樣本中哪些是具有欺詐行為的!
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")

千萬(wàn)不要著急去用機(jī)器學(xué)習(xí)算法建模做這個(gè)分類問(wèn)題���。首先我們來(lái)觀察一下數(shù)據(jù)的分布情況����,在數(shù)據(jù)樣本中有明確的label列指定了class為0代表正常情況����,class為1代表發(fā)生了欺詐行為的樣本。從上圖中可以看出來(lái)�����。��。���。等等���,你不是說(shuō)有兩種情況嗎�����,為啥圖上只有class為0的樣本?�?���?再仔細(xì)看看�����,納尼���。�。���。class為1的并不是木有���,而是太少了�,少到基本看不出來(lái)了��,那么此時(shí)我們面對(duì)一個(gè)新的挑戰(zhàn)���,樣本極度不均衡,接下來(lái)我們首先要解決這個(gè)問(wèn)題�����,這個(gè)很常見(jiàn)也是很頭疼的問(wèn)題���。
這里我們提出兩種解決方案也是數(shù)據(jù)分析中最常用的兩種方法�,下采樣和過(guò)采樣�!
先挑個(gè)軟柿子捏,下采樣比較簡(jiǎn)單實(shí)現(xiàn)��,咱們就先搞定第一種方案���!下采樣的意思就是說(shuō)�,不是兩類數(shù)據(jù)不均衡嗎����,那我讓你們同樣少(也就是1有多少個(gè) 0就消減成多少個(gè))���,這樣不就均衡了嗎。
很簡(jiǎn)單的實(shí)現(xiàn)方法�,在屬于0的數(shù)據(jù)中,進(jìn)行隨機(jī)的選擇�,就選跟class為1的那類樣本一樣多就好了,那么現(xiàn)在我們已經(jīng)得到了兩組都是非常少的數(shù)據(jù)��,接下來(lái)就可以建模啦��!不過(guò)在建立任何一個(gè)機(jī)器學(xué)習(xí)模型之前不要忘了一個(gè)常規(guī)的操作����,就是要把數(shù)據(jù)集切分成訓(xùn)練集和測(cè)試集,這樣會(huì)使得后續(xù)驗(yàn)證的結(jié)果更為靠譜��。
在訓(xùn)練邏輯回歸的模型中做了一件非常常規(guī)的事情����,就是對(duì)于一個(gè)模型,咱們?cè)龠x擇一個(gè)算法的時(shí)候伴隨著很多的參數(shù)要調(diào)節(jié)����,那么如何找到最合適的參數(shù)可不是一件簡(jiǎn)單的事,依靠經(jīng)驗(yàn)值并不是十分靠譜���,通常情況下我們需要大量的實(shí)驗(yàn)也就是不斷去嘗試最終得出這些合適的參數(shù)����。
不同C參數(shù)對(duì)應(yīng)的最終模型效果:
C parameter: 0.01
Iteration 1 : recall score = 0.958904109589
Iteration 2 : recall score = 0.917808219178
Iteration 3 : recall score = 1.0
Iteration 4 : recall score = 0.972972972973
Iteration 5 : recall score = 0.954545454545
Mean recall score 0.960846151257
C parameter: 0.1
Iteration 1 : recall score = 0.835616438356
Iteration 2 : recall score = 0.86301369863
Iteration 3 : recall score = 0.915254237288
Iteration 4 : recall score = 0.932432432432
Iteration 5 : recall score = 0.878787878788
Mean recall score 0.885020937099
C parameter: 1
Iteration 1 : recall score = 0.835616438356
Iteration 2 : recall score = 0.86301369863
Iteration 3 : recall score = 0.966101694915
Iteration 4 : recall score = 0.945945945946
Iteration 5 : recall score = 0.893939393939
Mean recall score 0.900923434357
C parameter: 10
Iteration 1 : recall score = 0.849315068493
Iteration 2 : recall score = 0.86301369863
Iteration 3 : recall score = 0.966101694915
Iteration 4 : recall score = 0.959459459459
Iteration 5 : recall score = 0.893939393939
Mean recall score 0.906365863087
C parameter: 100
Iteration 1 : recall score = 0.86301369863
Iteration 2 : recall score = 0.86301369863
Iteration 3 : recall score = 0.966101694915
Iteration 4 : recall score = 0.959459459459
Iteration 5 : recall score = 0.893939393939
Mean recall score 0.909105589115
Best model to choose from cross validation is with C parameter = 0.01
在使用機(jī)器學(xué)習(xí)算法的時(shí)候,很重要的一部就是參數(shù)的調(diào)節(jié)���,在這里我們選擇使用最經(jīng)典的分類算法��,邏輯回歸!千萬(wàn)別把邏輯回歸當(dāng)成是回歸算法�,它就是最實(shí)用的二分類算法!這里我們需要考慮的c參數(shù)就是正則化懲罰項(xiàng)的力度����,那么如何選擇到最好的參數(shù)呢?這里我們就需要交叉驗(yàn)證啦�,然后用不同的C參數(shù)去跑相同的數(shù)據(jù),目的就是去看看啥樣的C參數(shù)能夠使得最終模型的效果最好�����!可以到不同的參數(shù)對(duì)最終的結(jié)果產(chǎn)生的影響還是蠻大的�����,這里最好的方法就是用驗(yàn)證集去尋找了!
模型已經(jīng)造出來(lái)了�,那么怎么評(píng)判哪個(gè)模型好,哪個(gè)模型不好呢�?我們這里需要好好想一想!
一般都是用精度來(lái)衡量�����,也就是常說(shuō)的準(zhǔn)確率����,但是我們來(lái)想一想,我們的目的是什么呢����?是不是要檢測(cè)出來(lái)那些異常的樣本呀!換個(gè)例子來(lái)說(shuō)�,假如現(xiàn)在醫(yī)院給了我們一個(gè)任務(wù)要檢測(cè)出來(lái)1000個(gè)病人中,有癌癥的那些人���。那么假設(shè)數(shù)據(jù)集中1000個(gè)人中有990個(gè)無(wú)癌癥�,只有10個(gè)有癌癥���,我們需要把這10個(gè)人檢測(cè)出來(lái)���。假設(shè)我們用精度來(lái)衡量�,那么即便這10個(gè)人沒(méi)檢測(cè)出來(lái)����,也是有
990/1000
也就是99%的精度,但是這個(gè)模型卻沒(méi)任何價(jià)值���!這點(diǎn)是非常重要的����,因?yàn)椴煌脑u(píng)估方法會(huì)得出不同的答案����,一定要根據(jù)問(wèn)題的本質(zhì)��,去選擇最合適的評(píng)估方法���。
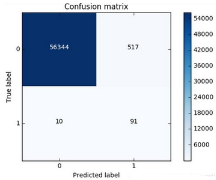
同樣的道理��,這里我們采用recall來(lái)計(jì)算模型的好壞��,也就是說(shuō)那些異常的樣本我們的檢測(cè)到了多少���,這也是咱們最初的目的����!這里通常用混淆矩陣來(lái)展示�����。
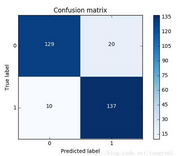
這個(gè)圖就非常漂亮了?����。ú⒉皇钦f(shuō)畫(huà)的好而是展示的很直接)從圖中可以清晰的看到原始數(shù)據(jù)中樣本的分布以及我們的模型的預(yù)測(cè)結(jié)果���,那么recall是怎么算出來(lái)的呢�����?就是用我們的檢測(cè)到的個(gè)數(shù)(137)去除以總共異常樣本的個(gè)數(shù)(10+137)�����,用這個(gè)數(shù)值來(lái)去評(píng)估我們的模型����。利用混淆矩陣我們可以很直觀的考察模型的精度以及recall,也是非常推薦大家在評(píng)估模型的時(shí)候不妨把這個(gè)圖亮出來(lái)可以幫助咱們很直觀的看清楚現(xiàn)在模型的效果以及存在的問(wèn)題�。
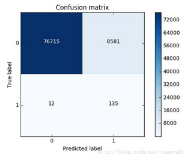
這可還木有完事,我們剛才只是在下采樣的數(shù)據(jù)集中去進(jìn)行測(cè)試的�,那么這份測(cè)試還不能完全可信,因?yàn)樗⒉皇窃嫉臏y(cè)試集�,我們需要在原始的,大量的測(cè)試集中再次去衡量當(dāng)前模型的效果�。可以看到效果其實(shí)還不錯(cuò)���,但是哪塊有些問(wèn)題呢��,是不是我們誤殺了很多呀���,有些樣本并不是異常的,但是并我們錯(cuò)誤的當(dāng)成了異常的����,這個(gè)現(xiàn)象其實(shí)就是下采樣策略本身的一個(gè)缺陷�����。
對(duì)于邏輯回歸算法來(lái)說(shuō),我們還可以指定這樣一個(gè)閾值��,也就是說(shuō)最終結(jié)果的概率是大于多少我們把它當(dāng)成是正或者負(fù)樣本�。不用的閾值會(huì)對(duì)結(jié)果產(chǎn)生很大的影響。
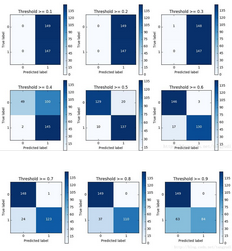
上圖中我們可以看到不用的閾值產(chǎn)生的影響還是蠻大的�����,閾值較小�����,意味著我們的模型非常嚴(yán)格寧肯錯(cuò)殺也不肯放過(guò)��,這樣會(huì)使得絕大多數(shù)樣本都被當(dāng)成了異常的樣本�����,recall很高����,精度稍低當(dāng)閾值較大的時(shí)候我們的模型就稍微寬松些啦,這個(gè)時(shí)候會(huì)導(dǎo)致recall很低��,精度稍高����,綜上當(dāng)我們使用邏輯回歸算法的時(shí)候���,還需要根據(jù)實(shí)際的應(yīng)用場(chǎng)景來(lái)選擇一個(gè)最恰當(dāng)?shù)拈撝担?
說(shuō)完了下采樣策略,我們繼續(xù)嘮一下過(guò)采樣策略��,跟下采樣相反�����,現(xiàn)在咱們的策略是要讓class為0和1的樣本一樣多���,也就是我們需要去進(jìn)行數(shù)據(jù)的生成啦�����。
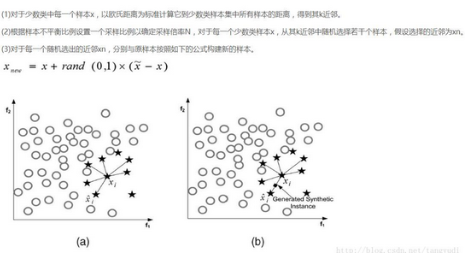
SMOTE算法是用的非常廣泛的數(shù)據(jù)生成策略��,流程可以參考上圖��,還是非常簡(jiǎn)單的�����,下面我們使用現(xiàn)成的庫(kù)來(lái)幫助我們完成過(guò)采樣數(shù)據(jù)生成策略。
很簡(jiǎn)單的幾步操作我們就完成過(guò)采樣策略,那么現(xiàn)在正負(fù)樣本就是一樣多的啦�,都有那么20多W個(gè),現(xiàn)在我們?cè)偻ㄟ^(guò)混淆矩陣來(lái)看一下�����,邏輯回歸應(yīng)用于過(guò)采樣樣本的效果����。數(shù)據(jù)增強(qiáng)的應(yīng)用面已經(jīng)非常廣了,對(duì)于很多機(jī)器學(xué)習(xí)或者深度學(xué)習(xí)問(wèn)題�����,這已經(jīng)成為了一個(gè)常規(guī)套路啦��!
我們對(duì)比一下下采樣和過(guò)采樣的效果�����,可以說(shuō)recall的效果都不錯(cuò)��,都可以檢測(cè)到異常樣本���,但是下采樣是不是誤殺的比較少呀��,所以如果我們可以進(jìn)行數(shù)據(jù)生成���,那么在處理樣本數(shù)據(jù)不均衡的情況下�����,過(guò)采樣是一個(gè)可以嘗試的方案����!
總結(jié):對(duì)于一個(gè)機(jī)器學(xué)習(xí)案例來(lái)說(shuō)�����,一份數(shù)據(jù)肯定伴隨著很多的挑戰(zhàn)和問(wèn)題����,那么最為重要的就是我們?cè)撛趺唇鉀Q這一系列的問(wèn)題,大牛們不見(jiàn)得代碼寫(xiě)的比咱們強(qiáng)但是他們卻很清楚如何去解決問(wèn)題�。今天咱們講述了一個(gè)以檢測(cè)任務(wù)為背景的案例,其中涉及到如何處理樣本不均衡問(wèn)題��,以及模型評(píng)估選擇的方法����,最后給出了邏輯回歸在不用閾值下的結(jié)果��。這里也是希望同學(xué)們可以通過(guò)案例多多積攢經(jīng)驗(yàn)�,早日成為大牛��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330