【機器學習】邏輯回歸原理及其實現(xiàn)
邏輯回歸是最簡單的機器學習模型,常常應用于各種簡單的任務中����。這里記錄邏輯回歸的背景以及學習方法,權當自己的學習記錄總結����。
邏輯回歸:首先,它不是一個回歸模型����,而是一個分類模型,它是被用來做分類的����。 之所以稱之為回歸,是因為它的學習的是模型模型的參數(shù)以最佳擬合已有的數(shù)據(jù)��。(比如�,根據(jù)已有的一些點,回歸出它的直線參數(shù)的擬合過程�����,就稱之為回歸���。)
學習方法:梯度上升法���,隨機梯度上升法。
模型特點:
1. 優(yōu)點:訓練快���、易理解��、易實現(xiàn)
2. 缺點:模型不夠強大����、擬合能力有限�,欠擬合,對于復雜的任務效果不夠好
在二分類的模型中�,我們能最希望的函數(shù)是一個二值化函數(shù),也就是
h(x) = 0 當 x > 閾值���,h(x)=1 當 x < 閾值
函數(shù)下圖所示:
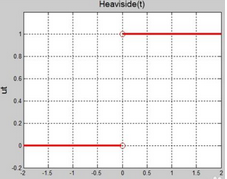
然而��,雖然這個函數(shù)是我們很想學習到的函數(shù)�����,但是由于它在閾值點處的跳躍性(不連續(xù)性)�����,使得它變得不好處理(比如在該點處沒有導數(shù)(梯度)的問題)�。
幸好,自然是美好的�����,我們可以用其它的函數(shù)來近似這個函數(shù)�,Sigmoid 函數(shù)就是一個很好的近似方法
其函數(shù)圖形如下所示(值閾(0–>1))
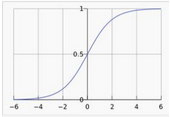
函數(shù)表達式為:

相比于原始的二值化函數(shù),sigmoid函數(shù)具有處處連續(xù)��、可導的優(yōu)點���。
為了實現(xiàn)邏輯回歸分類器��,我們將每個特征都乘以一個回歸系數(shù)wi����,然后將結果相加得到一個值����,并將這個值帶入到sigmoid函數(shù)中���,就會得到一個0–>1之間的數(shù)值,而大于0.5的值被分為1類��,小于0.5的被分為0類���。所以,邏輯回歸也被稱之為一個概率估計模型���。
在已經確定了分類器模型的函數(shù)形式之后�,問題就在于如何學習以獲得最佳的回歸系數(shù)�����?
主要是采用梯度上升及其變形的方法�����。
它的思想是:要找到某個函數(shù)的最大值���,最好的方法就是沿著該函數(shù)的梯度方向進行尋找���。(要有梯度就要求待計算的點有定義并且可導,所以二值化函數(shù)不能使用。)
權重更新:
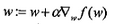
其中alpha為步長�,學習(訓練)的停止條件一般為:迭代到達一定的次數(shù),或者算法已經到達了一定的誤差范圍之內���。
注意區(qū)別于梯度下降法:跟梯度上升法是相同的道理����,加法變?yōu)闇p法�。
隨機梯度上升法:因為梯度上升法在每次更新回歸系數(shù)的時候都需要遍歷整個數(shù)據(jù)集合,當數(shù)據(jù)很多的時候��,就不適用了�,改進的方法為:一次只使用一個樣本來更新回歸系數(shù),這種方法稱之為隨機梯度上升法����。
只是它用來尋找最小值(一般是loss最?��。?,而梯度上升法用來尋找最大值��。
所以總的來說�����,邏輯回歸的計算方法很簡單,就分為兩步:1�,計算梯度,2��,更新權值�����。
具體的權重更新方法為:
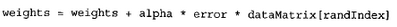
具體的代碼如下(python):
def sigmoid(x):
'''
邏輯回歸的判別函數(shù)
'''
return 1.0/(1.0+exp(-x))
def gradientAscent(datas,labels):
'''
輸入參數(shù)datas:訓練數(shù)據(jù)矩陣���,每一行為一個數(shù)據(jù)
輸入參數(shù)labels:標簽數(shù)據(jù),為一個值�����。
要求參數(shù)數(shù)據(jù)匹配
'''
dataX = mat(datas)
#每列代表一個特征����,每行代表不同的訓練樣本���。
dataY = mat(labels).transpose()
#標簽����,將行向量轉置為列向量
m,n = shape(dataX)
alpha = 0.001
#步長��,也就是學習率
itera_num = 1000
#迭代次數(shù)
W = ones((n,1))
for i in range(itera_num):
H = sigmoid(dataX * W)
# H 是一個列向量���,元素個數(shù)==m
error = dataY - H
W = W + alpha * X.transpose()*error
return W
def stochasticGradientAscent(datas,labels):
dataX = mat(datas)
#每列代表一個特征����,每行代表不同的訓練樣本�����。
dataY = mat(labels).transpose()
#標簽���,將行向量轉置為列向量
m,n = shape(datas)
alpha = 0.01
W = ones(n)
for i in range(m):
h = sigmoid(sum(dataX[i]*W))
error = dataY[i] - h
W = W + alpha * error *dataX[i]
return W
總結: 邏輯回歸的目的是為了尋找非線性函數(shù)Sigmoid的最佳擬合參數(shù)中的權值w�����,其w的值通過梯度上升法來學習到。隨機梯度上升一次只處理少量的樣本�����,節(jié)約了計算資源同時也使得算法可以在線學習。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330