矩陣分解在協(xié)同過(guò)濾推薦算法中的應(yīng)用
推薦系統(tǒng)是當(dāng)下越來(lái)越熱的一個(gè)研究問(wèn)題,無(wú)論在學(xué)術(shù)界還是在工業(yè)界都有很多優(yōu)秀的人才參與其中����。近幾年舉辦的推薦系統(tǒng)比賽更是一次又一次地把推薦系統(tǒng)的研究推向了高潮,比如幾年前的Neflix百萬(wàn)大獎(jiǎng)賽��,KDD
CUP
2011的音樂(lè)推薦比賽���,去年的百度電影推薦競(jìng)賽���,還有最近的阿里巴巴大數(shù)據(jù)競(jìng)賽。這些比賽對(duì)推薦系統(tǒng)的發(fā)展都起到了很大的推動(dòng)作用����,使我們有機(jī)會(huì)接觸到真實(shí)的工業(yè)界數(shù)據(jù)�。我們利用這些數(shù)據(jù)可以更好地學(xué)習(xí)掌握推薦系統(tǒng),這些數(shù)據(jù)網(wǎng)上很多�,大家可以到網(wǎng)上下載���。
推薦系統(tǒng)在工業(yè)領(lǐng)域中取得了巨大的成功,尤其是在電子商務(wù)中�。很多電子商務(wù)網(wǎng)站利用推薦系統(tǒng)來(lái)提高銷售收入,推薦系統(tǒng)為Amazon網(wǎng)站每年帶來(lái)30%的銷售收入�。推薦系統(tǒng)在不同網(wǎng)站上應(yīng)用的方式不同,這個(gè)不是本文的重點(diǎn)����,如果感興趣可以閱讀《推薦系統(tǒng)實(shí)踐》(人民郵電出版社,項(xiàng)亮)第一章內(nèi)容���。下面進(jìn)入主題���。
為了方便介紹,假設(shè)推薦系統(tǒng)中有用戶集合有6個(gè)用戶�����,即U={u1,u2,u3,u4,u5,u6}���,項(xiàng)目(物品)集合有7個(gè)項(xiàng)目��,即V={v1,v2,v3,v4,v5,v6,v7}����,用戶對(duì)項(xiàng)目的評(píng)分結(jié)合為R,用戶對(duì)項(xiàng)目的評(píng)分范圍是[0,
5]�����。R具體表示如下:

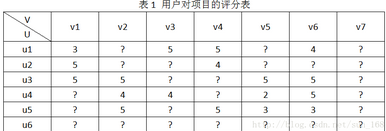
推薦系統(tǒng)的目標(biāo)就是預(yù)測(cè)出符號(hào)“�?”對(duì)應(yīng)位置的分值。推薦系統(tǒng)基于這樣一個(gè)假設(shè):用戶對(duì)項(xiàng)目的打分越高�,表明用戶越喜歡。因此��,預(yù)測(cè)出用戶對(duì)未評(píng)分項(xiàng)目的評(píng)分后��,根據(jù)分值大小排序����,把分值高的項(xiàng)目推薦給用戶。怎么預(yù)測(cè)這些評(píng)分呢���,方法大體上可以分為基于內(nèi)容的推薦���、協(xié)同過(guò)濾推薦和混合推薦三類,協(xié)同過(guò)濾算法進(jìn)一步劃分又可分為基于基于內(nèi)存的推薦(memory-based)和基于模型的推薦(model-based),本文介紹的矩陣分解算法屬于基于模型的推薦�。
矩陣分解算法的數(shù)學(xué)理論基礎(chǔ)是矩陣的行列變換��。在《線性代數(shù)》中�����,我們知道矩陣A進(jìn)行行變換相當(dāng)于A左乘一個(gè)矩陣����,矩陣A進(jìn)行列變換等價(jià)于矩陣A右乘一個(gè)矩陣,因此矩陣A可以表示為A=PEQ=PQ(E是標(biāo)準(zhǔn)陣)����。
矩陣分解目標(biāo)就是把用戶-項(xiàng)目評(píng)分矩陣R分解成用戶因子矩陣和項(xiàng)目因子矩陣乘的形式,即R=UV�,這里R是n×m, n =6�����, m =7��,U是n×k���,V是k×m�。直觀地表示如下:
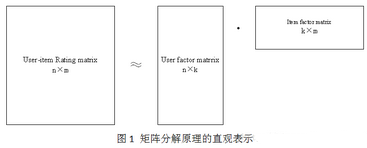
高維的用戶-項(xiàng)目評(píng)分矩陣分解成為兩個(gè)低維的用戶因子矩陣和項(xiàng)目因子矩陣,因此矩陣分解和PCA不同����,不是為了降維。用戶i對(duì)項(xiàng)目j的評(píng)分r_ij
=innerproduct(u_i, v_j)����,更一般的情況是r_ij =f(U_i,
V_j),這里為了介紹方便就是用u_i和v_j內(nèi)積的形式�����。下面介紹評(píng)估低維矩陣乘積擬合評(píng)分矩陣的方法�����。
首先假設(shè)��,用戶對(duì)項(xiàng)目的真實(shí)評(píng)分和預(yù)測(cè)評(píng)分之間的差服從高斯分布�����,基于這一假設(shè)����,可推導(dǎo)出目標(biāo)函數(shù)如下:
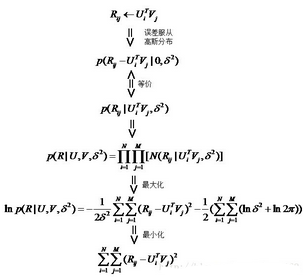
最后得到矩陣分解的目標(biāo)函數(shù)如下:
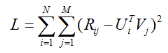
從最終得到得目標(biāo)函數(shù)可以直觀地理解�����,預(yù)測(cè)的分值就是盡量逼近真實(shí)的已知評(píng)分值。有了目標(biāo)函數(shù)之后���,下面就開始談優(yōu)化方法了�,通常的優(yōu)化方法分為兩種:交叉最小二乘法(alternative
least squares)和隨機(jī)梯度下降法(stochastic gradient descent)�。
首先介紹交叉最小二乘法����,之所以交叉最小二乘法能夠應(yīng)用到這個(gè)目標(biāo)函數(shù)主要是因?yàn)長(zhǎng)對(duì)U和V都是凸函數(shù)。首先分別對(duì)用戶因子向量和項(xiàng)目因子向量求偏導(dǎo)����,令偏導(dǎo)等于0求駐點(diǎn),具體解法如下:

上面就是用戶因子向量和項(xiàng)目因子向量的更新公式����,迭代更新公式即可找到可接受的局部最優(yōu)解。迭代終止的條件下面會(huì)講到��。
接下來(lái)講解隨機(jī)梯度下降法,這個(gè)方法應(yīng)用的最多����。大致思想是讓變量沿著目標(biāo)函數(shù)負(fù)梯度的方向移動(dòng),直到移動(dòng)到極小值點(diǎn)��。直觀的表示如下:
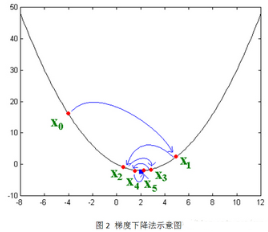
其實(shí)負(fù)梯度的負(fù)方向�����,當(dāng)函數(shù)是凸函數(shù)時(shí)是函數(shù)值減小的方向走��;當(dāng)函數(shù)是凹函數(shù)時(shí)是往函數(shù)值增大的方向移動(dòng)�。而矩陣分解的目標(biāo)函數(shù)L是凸函數(shù)���,因此,通過(guò)梯度下降法我們能夠得到目標(biāo)函數(shù)L的極小值(理想情況是最小值)�����。
言歸正傳,通過(guò)上面的講解��,我們可以獲取梯度下降算法的因子矩陣更新公式����,具體如下:
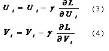
(3)和(4)中的γ指的是步長(zhǎng),也即是學(xué)習(xí)速率����,它是一個(gè)超參數(shù),需要調(diào)參確定����。對(duì)于梯度見(1)和(2)���。
下面說(shuō)下迭代終止的條件�。迭代終止的條件有很多種��,就目前我了解的主要有
1) 設(shè)置一個(gè)閾值���,當(dāng)L函數(shù)值小于閾值時(shí)就停止迭代,不常用
2) 設(shè)置一個(gè)閾值���,當(dāng)前后兩次函數(shù)值變化絕對(duì)值小于閾值時(shí)����,停止迭代
3) 設(shè)置固定迭代次數(shù)
另外還有一個(gè)問(wèn)題,當(dāng)用戶-項(xiàng)目評(píng)分矩陣R非常稀疏時(shí)����,就會(huì)出現(xiàn)過(guò)擬合(overfitting)的問(wèn)題,過(guò)擬合問(wèn)題的解決方法就是正則化(regularization)�����。正則化其實(shí)就是在目標(biāo)函數(shù)中加上用戶因子向量和項(xiàng)目因子向量的二范數(shù)�����,當(dāng)然也可以加上一范數(shù)���。至于加上一范數(shù)還是二范數(shù)要看具體情況���,一范數(shù)會(huì)使很多因子為0,從而減小模型大小�����,而二范數(shù)則不會(huì)它只能使因子接近于0����,而不能使其為0���,關(guān)于這個(gè)的介紹可參考論文Regression
Shrinkage and Selection via the Lasso。引入正則化項(xiàng)后目標(biāo)函數(shù)變?yōu)椋?
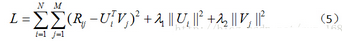
(5)中λ_1和λ_2是指正則項(xiàng)的權(quán)重���,這兩個(gè)值可以取一樣�����,具體取值也需要根據(jù)數(shù)據(jù)集調(diào)參得到����。優(yōu)化方法和前面一樣�����,只是梯度公式需要更新一下����。
矩陣分解算法目前在推薦系統(tǒng)中應(yīng)用非常廣泛�����,對(duì)于使用RMSE作為評(píng)價(jià)指標(biāo)的系統(tǒng)尤為明顯��,因?yàn)榫仃嚪纸獾哪繕?biāo)就是使RMSE取值最小�。但矩陣分解有其弱點(diǎn),就是解釋性差�,不能很好為推薦結(jié)果做出解釋。
后面會(huì)繼續(xù)介紹矩陣分解算法的擴(kuò)展性問(wèn)題�,就是如何加入隱反饋信息,加入時(shí)間信息等�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330