機(jī)器學(xué)習(xí)中的特征選擇
特征選擇是一個重要的數(shù)據(jù)預(yù)處理過程,獲得數(shù)據(jù)之后要先進(jìn)行特征選擇然后再訓(xùn)練模型�。主要作用:1、降維 2���、去除不相關(guān)特征�。
特征選擇方法包含:子集搜索和子集評價兩個問題����。
子集搜索包含前向搜索��、后向搜索���、雙向搜索等���。
子集評價方法包含:信息增益,交叉熵�����,相關(guān)性,余弦相似度等評級準(zhǔn)則�����。
兩者結(jié)合起來就是特征選擇方法�,例如前向搜索與信息熵結(jié)合,顯然與決策樹很相似����。
常見特征選擇有三類方法:過濾式(filter),包裹式(wrapper)和嵌入式(embedding).————見周志華老師《機(jī)器學(xué)習(xí)》11章。
1. 過濾式(filter)
過濾式方法先對數(shù)據(jù)集進(jìn)行特征選擇�,再訓(xùn)練學(xué)習(xí)器。兩者分裂開來��。Relief是一種著名的過濾式特征選擇方法�,設(shè)計(jì)了一種相關(guān)統(tǒng)計(jì)量來度量特征重要性。
sklearn模塊中有一些特征選擇的方法��。
sklearn官方文檔
(1)* Removing features with low variance*
特征篩選的時候��,對于特征全0�,全1 ,多數(shù)1����,多數(shù)0的要刪去����。利用sklearn中模塊�����,可如下操作(個人認(rèn)為屬于過濾式的)����。
代碼如下:
from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8))) #選擇方差大于某個數(shù)的特征。
sel.fit_transform(X)
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
(2)利用單變量特征選擇(統(tǒng)計(jì)測試方法)����。
Univariate feature selection works by selecting the best features based
on univariate statistical tests. It can be seen as a preprocessing step
to an estimator. Scikit-learn exposes feature selection routines as
objects that implement the transform method:
SelectKBest選擇排名排在前n個的變量
SelectPercentile 選擇排名排在前n%的變量
其他指標(biāo): false positive rate SelectFpr, false discovery rate SelectFdr, or family wise error SelectFwe 和 GenericUnivariateSelect。
對于regression問題:用f_regression函數(shù)���。
對于classification問題:用chi2或者f_classif函數(shù)。
例如:利用 F-test for feature scoring
We use the default selection function: the 10% most significant features**
代碼來源
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
from sklearn.feature_selection import SelectPercentile, f_classif
###############################################################################
# import some data to play with
# The iris dataset
iris = datasets.load_iris() #數(shù)據(jù)本身(150,4)
# Some noisy data not correlated
E = np.random.uniform(0, 0.1, size=(len(iris.data), 20))
#添加(150�,20)的隨機(jī)噪聲
# Add the noisy data to the informative features
X = np.hstack((iris.data, E))
print X.shape #(150,24)維度
y = iris.target
###############################################################################
plt.figure(1)
plt.clf()
X_indices = np.arange(X.shape[-1])
###############################################################################
# Univariate feature selection with F-test for feature scoring
# We use the default selection function: the 10% most significant features
selector = SelectPercentile(f_classif, percentile=10)
selector.fit(X, y)
scores = -np.log10(selector.pvalues_)
scores /= scores.max()
plt.bar(X_indices - .45, scores, width=.2,
label=r'Univariate score ($-Log(p_{value})$)', color='g')
###############################################################################
# Compare to the weights of an SVM
clf = svm.SVC(kernel='linear')
clf.fit(X, y)
svm_weights = (clf.coef_ ** 2).sum(axis=0)
svm_weights /= svm_weights.max()
plt.bar(X_indices - .25, svm_weights, width=.2, label='SVM weight', color='r')
clf_selected = svm.SVC(kernel='linear')
clf_selected.fit(selector.transform(X), y)
svm_weights_selected = (clf_selected.coef_ ** 2).sum(axis=0)
svm_weights_selected /= svm_weights_selected.max()
plt.bar(X_indices[selector.get_support()] - .05, svm_weights_selected,
width=.2, label='SVM weights after selection', color='b')
plt.title("Comparing feature selection")
plt.xlabel('Feature number')
plt.yticks(())
plt.axis('tight')
plt.legend(loc='upper right')
plt.show()
P值越小,顯著性越高���。負(fù)對數(shù)也越大���。前4個有明顯的顯著性�����。(后20個無顯著性)

2.包裹式(wrapper)
與過濾式機(jī)器學(xué)習(xí)不考慮后續(xù)學(xué)習(xí)器不同�,包裹式特征選擇直接把最終要使用的學(xué)習(xí)器性能作為特征子集的評價標(biāo)準(zhǔn)����。由于包裹式特征選擇的方法直接針對給定學(xué)習(xí)器進(jìn)行優(yōu)化,包裹式特征一般回避過濾式要好���。LVW是一種典型的方法����。采用隨機(jī)策略搜索特征子集��,而每次特征子集的評價都需要訓(xùn)練學(xué)習(xí)器����,開銷很大。
3.嵌入式(embedding)
嵌入式特征選擇將特征選擇過程和機(jī)器訓(xùn)練過程融合為一體����。兩者在同一優(yōu)化過程中完成��,即在學(xué)習(xí)器訓(xùn)練過程中自動進(jìn)行了特征選擇��。
例如:L1正則化(Lasso�����,注意L2嶺回歸并不會降低維度)
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
X.shape
(150, 4)
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
X_new.shape
(150, 3)
基于樹的特征選取
對于樹模型選擇特征屬于上面哪一種���,感覺是包裹式,并不確定��。
sklearn 提供例子:
class sklearn.ensemble.ExtraTreesClassifier(n_estimators=10, criterion=’gini’, max_depth=None, min_samples_split=2……)
分類標(biāo)準(zhǔn) 默認(rèn)基尼系數(shù)����,還可以設(shè)成信息熵增益。
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.ensemble import ExtraTreesClassifier
# Build a classification task using 3 informative features
X, y = make_classification(n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False)
# Build a forest and compute the feature importances
forest = ExtraTreesClassifier(n_estimators=250,
random_state=0)
forest.fit(X, y)
importances = forest.feature_importances_
std = np.std([tree.feature_importances_ for tree in forest.estimators_],
axis=0)
indices = np.argsort(importances)[::-1]
# Print the feature ranking
print("Feature ranking:")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# Plot the feature importances of the forest
plt.figure()
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices],
color="r", yerr=std[indices], align="center")
plt.xticks(range(X.shape[1]), indices)
plt.xlim([-1, X.shape[1]])
plt.show()
特征重要性如圖所示
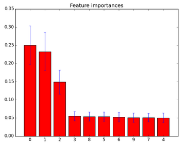
上述的所有源于sklearn上的特征選取部分��,細(xì)節(jié)[here]����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330