R語言中的概率論和數(shù)理統(tǒng)計
一�、隨機變量
(一)、什么是隨機變量�?
1.定義
隨機變量(random variable)表示隨機現(xiàn)象各種結(jié)果的實值函數(shù)����。隨機變量是定義在樣本空間S上�,取值在實數(shù)域上的函數(shù),由于它的自變量是隨機試驗的結(jié)果�,而隨機實驗結(jié)果的出現(xiàn)具有隨機性,因此��,隨機變量的取值具有一定的隨機性�����。
2.R程序:生成一個在(0,1,2,3,4,5)的隨機變量
> S<-1:5
> sample(S,1)
[1] 2
> sample(S,1)
[1] 3
> sample(S,4)
[1] 3 5 4 1
#sample(x=x,size=5,replace=T)�����,其中size指定抽樣的次數(shù)����,“replace”就是重復(fù)的意思。即可以重復(fù)對元素進行抽樣���,也就是所謂的有放回抽樣��。
(二)�、離散型隨機變量
1.定義
如果隨機變量X的全部可能的取值只有有限多個或可列無窮多個��,則稱X為離散型隨機變量�����。
2.R程序:生成樣本空間為(1,2,3)的隨機變量X��,X的取值是有限的
> S<-1:3
> X<-sample(S,1);X
[1] 2
(三)�、連續(xù)型隨機變量
1.定義
隨機變量X,取值可以在某個區(qū)間內(nèi)取任一實數(shù)����,即變量的取值可以是連續(xù)的,這隨機變量就稱為連續(xù)型隨機變量
2.定義R程序:生成樣本在空間(0,1)的連續(xù)隨機函數(shù)�,取10個值
> runif(10,0,1)
[1] 0.3819569 0.7609549 0.6692581 0.6314708 0.5552201 0.8225527 0.7633086 0.4667188 0.1883553
[10] 0.> runif(10,0,1)
[1] 0.3819569 0.7609549 0.6692581 0.6314708 0.5552201 0.8225527 0.7633086 0.4667188 0.1883553
[10] 0.3741653
#1.runif(n,min=0,max=1)函數(shù)的規(guī)則:
n表示生成的隨機數(shù)數(shù)量,min表示均勻分布的下限,max表示均勻分布的上限�����;若省略參數(shù)min����、max,則默認生成[0,1]上的均勻分布隨機數(shù)。
(一)�、數(shù)學(xué)期望(mathematical expectation)
1.離散型隨機變量:一切可能的取值xi與對應(yīng)的概率Pi(=xi)之積的和稱為該離散型隨機變量的數(shù)學(xué)期望,記為E(x)�。數(shù)學(xué)期望是最基本的數(shù)學(xué)特征之一。它反映隨機變量平均取值的大小�����。
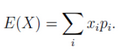
R程序:計算樣本(1,2,3,7,21)的數(shù)學(xué)期望
> S<-c(1,2,3,7,21)
> mean(S)
[1] 6.8
2.連續(xù)型隨機變量:若隨機變量X的分布函數(shù)F(x)可表示成一個非負可積函數(shù)f(x)的積分�����,則稱X為連續(xù)性隨機變量�����,f(x)稱為X的概率密度函數(shù)�,積分值為X的數(shù)學(xué)期望�,記為E(X)�。
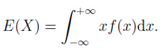
(二)、方差(Variance)
方差是各個數(shù)據(jù)與平均數(shù)之差的平方的平均數(shù)��。在概率論和數(shù)理統(tǒng)計中��,方差用來度量隨機變量和其數(shù)學(xué)期望(即均值)之間的偏離程度�����。
設(shè)X為隨機變量�,如果E{[X-E(X)]^2}存在����,則稱E{[X-E(X)]^2}為X的方差,記為Var(X)��。
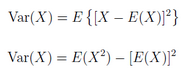
R程序:計算樣本(1,2,3,7,21)的方差
> S<-c(1,2,3,7,21)
> var(S)
[1] 68.2
(三)�����、標準差(Standard Deviation)
標準差是方差的算術(shù)平方根sqrt(var(X))����。標準差能反映一個數(shù)據(jù)集的離散程度��。平均數(shù)相同的���,標準差未必相同。
R程序:計算樣本(1,2,3,7,21)標準差
> S<-c(1,2,3,7,21)
> sd(S)
[1] 8.258329
(四)�����、各種分布的期望和方差
離散型分布:兩點分布���,二項分布��,泊松分布等
連續(xù)型分布:均勻分布�����,指數(shù)分布���,正態(tài)分布,伽馬分布等
對于某一特定場景����,其所符合的分布規(guī)律一般先驗給出
(五)、常用統(tǒng)計量
1.眾數(shù)(Mode):
一組數(shù)據(jù)中出現(xiàn)次數(shù)最多的數(shù)值����,叫眾數(shù)����,有時眾數(shù)在一組數(shù)中有好幾個�����。
R程序:計算樣本(1,2,3,3,3,7,7,7,7,9,10,21)的眾數(shù)
> S<-c(1,2,3,3,3,7,7,7,7,9,10,21)
> names(which.max(table(S)))
[1] "7"
#table()的輸出可以看成是一個帶名字的數(shù)字向量���。可以用names()和as.numeric()分別得到名稱和頻數(shù)
> x <- sample(c("a", "b", "c"), 100, replace=TRUE)
> names(table(x))
[1] "a" "b" "c"
> as.numeric(table(x))
[1] 42 25 33
也可以直接把輸出結(jié)果轉(zhuǎn)化為數(shù)據(jù)框���,as.data.frame():
> as.data.frame(table(x))
x Freq
1 a 42
2 b 25
3 c 33
> table(S)
S
1 2 3 7 9 10 21
1 1 3 4 1 1 1
2.最小值(minimum):
在給定情形下可以達到的最小數(shù)量或最小數(shù)值
3.最大值(maximum):
在給定情形下可以達到的最大數(shù)量或最大數(shù)值
4.中位數(shù)(Medians):
是指將統(tǒng)計總體當中的各個變量值按大小順序排列起來�,形成一個數(shù)列����,處于變量數(shù)列中間位置的變量值就稱為中位數(shù)
5.四分位數(shù)(Quartile):
用于描述任何類型的數(shù)據(jù),尤其是偏態(tài)數(shù)據(jù)的離散程度,即將全部數(shù)據(jù)從小到大排列�,正好排列在上1/4位置叫上四分位數(shù),下1/4位置上的數(shù)就叫做下四分位數(shù)
R程序:計算樣本(1,2,3,4,5,6,7,8,9)的四分位數(shù)
> S<-c(1,2,3,4,5,6,7,8,9)
> quantile(S)
0% 25% 50% 75% 100%
1 3 5 7 9
> fivenum(S)
[1] 1 3 5 7 9
6.通用的計算統(tǒng)計函數(shù):
R程序:計算樣本(1,2,3,4,5,6,7,8,9)的統(tǒng)計函數(shù)
> S<-c(1,2,3,4,5,6,7,8,9)
> summary(S)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1 3 5 5 7 9
(六)、協(xié)方差(Covariance)
協(xié)方差用于衡量兩個變量的總體誤差����。而方差是協(xié)方差的一種特殊情況,即當兩個變量是相同的情況��。設(shè)X,Y為兩個隨機變量��,稱E{[X-E(X)][Y-E(Y)]}為X和Y的協(xié)方差��,記錄Cov(X,Y)��。
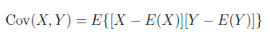
R程序:計算X(1,2,3,4)和Y(5,6,7,8)的協(xié)方差
> X<-c(1,2,3,4)
> Y<-c(5,6,7,8)
> cov(X,Y)
[1] 1.666667
(七)�����、相關(guān)系數(shù)(Correlation coefficient)
相關(guān)系數(shù)是用以反映變量之間相關(guān)關(guān)系密切程度的統(tǒng)計指標����。相關(guān)系數(shù)是按積差方法計算�����,同樣以兩變量與各自平均值的離差為基礎(chǔ),通過兩個離差相乘來反映兩變量之間相關(guān)程度��。當Var(X)>0,
Var(Y)>0時���,稱Cov(X,Y)/sqrt(Var(X)*Var(Y))為X與Y的相關(guān)系數(shù)����。
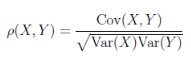
R程序:計算X(1,2,3,4)和Y(5,7,8,9)的相關(guān)系數(shù)
> X<-c(1,2,3,4)
> Y<-c(5,7,8,9)
> cor(X,Y)
[1] 0.9827076
八)����、矩
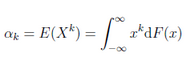
1.原點矩(moment about origin)
2.中心矩(moment about centre)
均值和方差分別就是一階原點矩和二階中心矩����,具體定義和概念,可詳見陳希孺《概率論與數(shù)理統(tǒng)計》P132-133
3.偏度(skewness):
是統(tǒng)計數(shù)據(jù)分布偏斜方向和程度的度量���,是統(tǒng)計數(shù)據(jù)分布非對稱程度的數(shù)字特征�����。設(shè)分布函數(shù)F(x)有中心矩μ2=E(X ?E(X))^2, μ3 = E(X ?E(X))^3��,則Cs=μ3/μ2^(3/2)為偏度系數(shù)��。
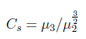
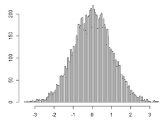
當Cs>0時����,概率分布偏向均值右則,Cs<0時,概率分布偏向均值左則���。 R語言:計算10000個正態(tài)分布的樣本的偏度
> library(PerformanceAnalytics)
> S<-rnorm(10000)
> skewness(S)
[1] -0.00178084
> hist(S,breaks=100)
#hist() 函數(shù):繪制直方圖
4.峰度(kurtosis): 又稱峰態(tài)系數(shù)��。
表征概率密度分布曲線在平均值處峰值高低的特征數(shù)���。峰度刻劃不同類型的分布的集中和分散程序。設(shè)分布函數(shù)��F(x)有中心矩μ2=E(X ?E(X))^2, μ4=E(X ?E(X))^4��,則Ck=μ4/(u2^2-3)為峰度系數(shù)���。
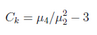
R語言:計算10000個正態(tài)分布的樣本的峰度��,(同偏度的樣本數(shù)據(jù))
> library(PerformanceAnalytics)
> kurtosis(S)
[1] -0.02443549
> hist(S,breaks=100)
(九)�、協(xié)方差矩陣(covariance matrix)
可以理解成不同維度上的協(xié)方差
> x=as.data.frame(matrix(rnorm(10),ncol=2))
> x
V1 V2
1 -2.11315384 -2.55189840
2 -0.96631271 -1.36148355
3 -0.02835058 -0.82328774
4 -1.86669567 -0.07201353
5 0.27324957 -2.23835218
> var(x)
V1 V2
V1 1.13470650 -0.09292042
V2 -0.09292042 1.03172261
> cov(x)
V1 V2
V1 1.13470650 -0.09292042
V2 -0.09292042 1.03172261
三����、極限定理
引言:
我們知道,隨機現(xiàn)象的統(tǒng)計性規(guī)律是在相同條件下進行大量重復(fù)試驗時呈現(xiàn)出來的,常見的兩種統(tǒng)計規(guī)律性為:
頻率的穩(wěn)定性��,即在大量重復(fù)試驗中�,事件發(fā)生的頻率總是在它的概率附近擺動,且隨著試驗次數(shù)的增多��,該頻率總是越來越明顯地穩(wěn)定在其概率附近��;
平均值的穩(wěn)定性���,即在多次重復(fù)測量中��,測量平均值總是在它的真實值附近擺動��,且隨著測量次數(shù)的增加�����,測量平均值總是越來越明顯地穩(wěn)定在其真實值附近。
對以上兩種規(guī)律�,人們不僅研究觀測值趨向于哪個穩(wěn)定值,而且還分析了觀測值在穩(wěn)定值周圍的擺動形式(分布情況)����。
針對觀測值趨向于哪個穩(wěn)定值,用數(shù)學(xué)語言及理論來分析研究,就引出了大數(shù)定律����。其中關(guān)于頻率穩(wěn)定性的大數(shù)定律稱為伯努利大數(shù)定律,關(guān)于均值穩(wěn)定性的大數(shù)定律稱為辛欽大數(shù)定律����。
針對觀測值在穩(wěn)定值周圍的擺動形式,用數(shù)學(xué)理論進行研究���,就得出了中心極限定理.所謂的中心極限定理�,就是把和的分布收斂于正態(tài)分布的那些定理的一個統(tǒng)稱��。
注 在概率論中�����,“定律”與“定理”是一樣的意思.“定理”一般用于指那些能用數(shù)學(xué)工具嚴格證明的結(jié)論��;而“定律”是指人們通過觀察分析得出來一種經(jīng)驗結(jié)論��,如牛頓三大定律���,熱力學(xué)定律等.因為概率論中的“大數(shù)定律”不僅是在實踐中總結(jié)出來的經(jīng)驗結(jié)論�,而且也可以用數(shù)學(xué)工具嚴格地去證明,所以叫“大數(shù)定律”或叫“大數(shù)定理”都可以�。
(一)、大數(shù)定理
R語言:假設(shè)投硬幣����,正面概率是0.5,投4次時�,計算得到2次正面的概率?根據(jù)大數(shù)定律�,如果投是10000次,計算5000次正面的概率���?
#計算2次正面的的概率
> choose(4,2)/2^4 #choose組合數(shù)的計算:從4中選擇2個
[1] 0.375
#計算5000次正面的的概率
> pbinom(5000, 10000, 0.5)
[1] 0.5039893
#pbinom二向分布�����,5000為分位數(shù)���,產(chǎn)生10000個隨機數(shù),每個概率0.5
(二)����、中心極限定理(central limit theorem)
中心極限定理是概率論中的一組定理���。中心極限定理說明�,大量相互獨立的隨機變量,其均值的分布以正態(tài)分布為極限����。
1.林德伯格-列維(Lindburg-Levy)
是棣莫佛-拉普拉斯定理的擴展,討論獨立同分布隨機變量序列的中央極限定理���。它表明��,獨立同分布����、且數(shù)學(xué)期望和方差有限的隨機變量序列的標準化和以標準正態(tài)分布為極限:

2.棣莫佛-拉普拉斯(de Movire - Laplace)
棣莫佛-拉普拉斯(de Moivre - Laplace)定理是中央極限定理的最初版本��,討論了服從二項分布的隨機變量序列�����。它指出����,參數(shù)為n, p的二項分布以nρ為均值、nρ(1-ρ)為方差的正態(tài)分布為極限�。

R語言:中心極限定理模擬���,從指數(shù)分布到正態(tài)分布
if (!require(animation)) install.packages("animation")
library(animation)
ani.options(interval = 0.1, nmax = 100)
par(mar = c(4, 4, 1, 0.5))
clt.ani()
#
1.library和require都可以載入包,但二者存在區(qū)別���。在一個函數(shù)中�����,如果一個包不存在�����,執(zhí)行到library將會停止執(zhí)行����,require則會繼續(xù)執(zhí)行����。
require將會根據(jù)包的存在與否返回true或者false。
2.interval:a positive number to set the time interval of the animation (unit in seconds); default to be 1.
3.nmax:maximum number of steps in a loop (e.g. iterations) to create
animation frames. Note: the actual number of frames can be less than
this number, depending on specific animations. Default to be 50.
4.mar設(shè)置圖形空白邊界行數(shù)�����,mar = c(bottom, left, top, right)
5.clt.ani:Demonstration of the Central Limit Theorem
6.shapiro.test檢驗���,P值大于0.05說明數(shù)據(jù)正態(tài)分布
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330