Python的Flask框架與數(shù)據(jù)庫(kù)連接的教程
命令行方式運(yùn)行Python腳本
在這個(gè)章節(jié)中����,我們將寫一些簡(jiǎn)單的數(shù)據(jù)庫(kù)管理腳本����。在此之前讓我們來(lái)復(fù)習(xí)一下如何通過(guò)命令行方式執(zhí)行Python腳本.
如果Linux 或者OS X的操作系統(tǒng)����,需要有執(zhí)行腳本的權(quán)限。例如:
該腳本有個(gè)指向使用解釋器的命令行�����。再腳本賦予執(zhí)行權(quán)限后就可以通過(guò)命令行執(zhí)行���,就像這樣: like this:
然而��,在Windows系統(tǒng)上這樣做是不行的����,你必須提供Python解釋器作為必選參數(shù)��,如:
flask/Scripts/
python script.py <arguments>
為了避免Python解釋器路徑輸入出錯(cuò)��,你可以將你的文件夾microoblog/flask/Scripts添加到系統(tǒng)路徑��,確保能正常顯示Python解釋器�。
從現(xiàn)在開始��,在Linux/OS X上的語(yǔ)句簡(jiǎn)潔。如果你使用Windows系統(tǒng)請(qǐng)記得轉(zhuǎn)換語(yǔ)句����。
在Flask使用數(shù)據(jù)庫(kù)
我們將使用Flask-SQLAlchemy 的擴(kuò)展來(lái)管理數(shù)據(jù)庫(kù)���。由SQLAlchemy項(xiàng)目提供的����,已封裝了關(guān)系對(duì)象映射(ORM)的一個(gè)插件���。
ORMs允許數(shù)據(jù)庫(kù)程序用對(duì)象的方式替代表和SQL語(yǔ)句��。面向?qū)ο蟮牟僮鞅籓RM轉(zhuǎn)化為數(shù)據(jù)庫(kù)命令。這樣就意味著���,不用sql語(yǔ)句�,讓Flask-SQLAlchemy為我們執(zhí)行sql語(yǔ)句����。
遷移
大多數(shù)數(shù)據(jù)庫(kù)教程都覆蓋了創(chuàng)建和使用一個(gè)數(shù)據(jù)庫(kù)的方法,但是沒(méi)有充分解決當(dāng)應(yīng)用程序擴(kuò)展時(shí)數(shù)據(jù)庫(kù)更新的問(wèn)題。通常���,你會(huì)刪除舊的數(shù)據(jù)庫(kù)�����,然后再創(chuàng)建一個(gè)新的數(shù)據(jù)庫(kù)來(lái)達(dá)到更新的效果����,這樣就丟失了所有的數(shù)據(jù)����。如果這些數(shù)據(jù)創(chuàng)建起來(lái)很費(fèi)勁����,那么我們不得不寫導(dǎo)入導(dǎo)出的腳本了。
幸運(yùn)的是��,我們有了更好的方案.
我們現(xiàn)在可以使用SQLAlchemy-migrate做數(shù)據(jù)庫(kù)遷移的更新了��,雖然它增加了數(shù)據(jù)庫(kù)啟動(dòng)時(shí)的負(fù)擔(dān),但這點(diǎn)小小的代價(jià)還是值得的���,畢竟我們不用擔(dān)心手動(dòng)遷移數(shù)據(jù)庫(kù)的問(wèn)題了��。
理論學(xué)習(xí)完畢����,我們開始吧!
配置
我們的小程序使用sqlite數(shù)據(jù)庫(kù)���。sqlite是小程序數(shù)據(jù)庫(kù)的最佳選擇��,一個(gè)可以以單文件存儲(chǔ)的數(shù)據(jù)庫(kù)。
在我們的配置文件中添加新的配置項(xiàng) (fileconfig.py):
importos
basedir=os.path.abspath(os.path.dirname(__file__))
SQLALCHEMY_DATABASE_URI='sqlite:///'+os.path.join(basedir,'app.db')
SQLALCHEMY_MIGRATE_REPO=os.path.join(basedir,'db_repository')
SQLALCHEMY_DATABASE_URI是the Flask-SQLAlchemy必需的擴(kuò)展�����。這是我們的數(shù)據(jù)庫(kù)文件的路徑��。
SQLALCHEMY_MIGRATE_REPO 是用來(lái)存儲(chǔ)SQLAlchemy-migrate數(shù)據(jù)庫(kù)文件的文件夾。
最后���,初始化應(yīng)用的時(shí)候也需要初始化數(shù)據(jù)庫(kù)�����。這里是升級(jí)后的init文件(fileapp/__init):
fromflaskimportFlask
fromflask.ext.sqlalchemyimport
SQLAlchemy
app=Flask(__name__)
app.config.from_object('config')
fromappimportviews, models
注意生成的腳本已改動(dòng)2個(gè)地方�。我們現(xiàn)在開始創(chuàng)建數(shù)據(jù)庫(kù)的adb對(duì)象��,引用新的模塊��。馬上來(lái)寫這個(gè)模塊。
數(shù)據(jù)庫(kù)模型
我們?cè)跀?shù)據(jù)庫(kù)存儲(chǔ)的數(shù)據(jù)通過(guò)數(shù)據(jù)庫(kù)model層被映射為一些類里面的對(duì)象,ORM層將根據(jù)類對(duì)象映射到數(shù)據(jù)庫(kù)對(duì)應(yīng)的字段.
讓我們來(lái)創(chuàng)建個(gè)映射到users的model��。使用WWW SQL Designer工具��,我們創(chuàng)建了代表users表的一個(gè)圖標(biāo):
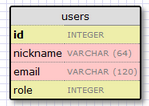
id字段通常作為主鍵的形式用在所有的models里面,每個(gè)在數(shù)據(jù)庫(kù)中的user都有一個(gè)指定的唯一id值。幸運(yùn)的是,這些都是自動(dòng)的,我們只需要提供一個(gè)id字段����。
nickname和email字段被定義為string類型���,他們的長(zhǎng)度也已經(jīng)被指定�,這樣可以節(jié)省數(shù)據(jù)庫(kù)存儲(chǔ)空間���。
role字段被定義為integer類型���,我們用來(lái)標(biāo)識(shí)users是admins還是其他類型�。
現(xiàn)在我們已經(jīng)明確了users表的結(jié)構(gòu)��,接下來(lái)轉(zhuǎn)換為編碼的工作將相當(dāng)簡(jiǎn)單了(fileapp/models.py):
fromappimportdb
ROLE_USER=0
ROLE_ADMIN=1
classUser(db.Model):
id=db.Column(db.Integer, primary_key=True)
nickname=db.Column(db.String(64), index=True, unique=True)
email=db.Column(db.String(120), index=True, unique=True)
role=db.Column(db.SmallInteger, default=ROLE_USER)
def__repr__(self):
return'<User %r>'%(self.nickname)
User類把我們剛剛創(chuàng)建的幾個(gè)字段定義為類變量。字段使用db.Column類創(chuàng)建實(shí)例,字段的類型作為參數(shù),另外還提供一些其他可選參數(shù)�。例如�����,標(biāo)識(shí)字段唯一性和索引的參數(shù).
__repr__方法告訴Python如何打印class對(duì)象,方便我們調(diào)試使用���。
創(chuàng)建數(shù)據(jù)庫(kù)
把配置和model放到正確的目錄位置���,現(xiàn)在我們創(chuàng)建數(shù)據(jù)庫(kù)文件����。SQLAlchemy-migrate包自帶命令行工具和APIs來(lái)創(chuàng)建數(shù)據(jù)庫(kù)�����,這樣的方式可以方便以后更新��。但是我覺(jué)得使用這個(gè)命令行工具有些別扭����,所以我自己寫了個(gè)python腳本來(lái)調(diào)用遷移的APIs.
這里有個(gè)創(chuàng)建數(shù)據(jù)庫(kù)的腳本 (filedb_create.py):
frommigrate.versioningimportapi
fromconfigimport
SQLALCHEMY_DATABASE_URI
fromconfigimport
SQLALCHEMY_MIGRATE_REPO
fromappimportdb
importos.path
db.create_all()
ifnotos.path.exists(
SQLALCHEMY_MIGRATE_REPO):
api.create(
SQLALCHEMY_MIGRATE_REPO,'database repository')
api.version_control(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO)
else:
api.version_control(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO, api.version(
SQLALCHEMY_MIGRATE_REPO))
注意這個(gè)腳本是完全通用的���,所有的應(yīng)用路徑名都是從配置文件讀取的���。當(dāng)你用在自己的項(xiàng)目時(shí)����,你可以把腳本拷貝到你app`s目錄下就能正常使用了��。
創(chuàng)建數(shù)據(jù)庫(kù)你只需要運(yùn)行下面的一條命令(注意windows下稍微有些不同):
運(yùn)行這條命令之后�����,你就創(chuàng)建了一個(gè)新的app.db文件��。這是個(gè)支持遷移的空sqlite數(shù)據(jù)庫(kù)�����,同時(shí)也會(huì)生成一個(gè)帶有幾個(gè)文件的db_repository目錄�����,這是SQLAlchemy-migrate存儲(chǔ)數(shù)據(jù)庫(kù)文件的地方����,注意如果數(shù)據(jù)庫(kù)已存在它就不會(huì)再重新生成了���。這將幫助我們?cè)趤G失了現(xiàn)有的數(shù)據(jù)庫(kù)后�����,再次自動(dòng)創(chuàng)建出來(lái)�����。.
第一次遷移
既然我們已經(jīng)定義好了model����,也把它和數(shù)據(jù)庫(kù)做了關(guān)聯(lián),接下來(lái)我們來(lái)初次嘗試下做一個(gè)改變應(yīng)用數(shù)據(jù)庫(kù)結(jié)構(gòu)的一次遷移�����,這將幫助我們從一個(gè)空的數(shù)據(jù)庫(kù)變成一個(gè)可以存儲(chǔ)users信息的數(shù)據(jù)庫(kù)����。
做一個(gè)遷移我使用另一個(gè)Python小助手腳本 (filedb_migrate.py):
importimp
frommigrate.versioningimportapi
fromappimportdb
fromconfigimport
SQLALCHEMY_DATABASE_URI
fromconfigimport
SQLALCHEMY_MIGRATE_REPO
migration=
SQLALCHEMY_MIGRATE_REPO+'/versions/%03d_migration.py'%(api.db_version(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO)+1)
tmp_module=imp.new_module('old_model')
old_model=api.create_model(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO)
execold_modelintmp_module.__dict__
script=api.make_update_script_for_model(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO, tmp_module.meta, db.metadata)
open(migration,"wt").write(script)
a=api.upgrade(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO)
print'New migration saved as '+migration
print'Current database version: '+str(api.db_version(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO))
這個(gè)腳本看起來(lái)很復(fù)雜,其實(shí)做的東西真不多����。SQLAlchemy-migrate通過(guò)對(duì)比數(shù)據(jù)庫(kù)的結(jié)構(gòu)(從app.db文件讀取)和models結(jié)構(gòu)(從app/models.py文件讀?���。┑姆绞絹?lái)創(chuàng)建遷移任務(wù),兩者之間的差異將作為一個(gè)遷移腳本記錄在遷移庫(kù)中���,遷移腳本知道如何應(yīng)用或者撤銷一次遷移���,所以它可以方便的升級(jí)或者降級(jí)一個(gè)數(shù)據(jù)庫(kù)的格式�。
雖然我使用上面的腳本自動(dòng)生成遷移時(shí)沒(méi)遇到什么問(wèn)題���,但有時(shí)候真的很難決定數(shù)據(jù)庫(kù)舊格式和新格式究竟有啥改變。為了讓SQLAlchemy-migrate更容易確定數(shù)據(jù)庫(kù)的改變����,我從來(lái)不給現(xiàn)有字段重命名,限制了添加刪除models����、字段,或者對(duì)現(xiàn)有字段的類型修改���。我總是檢查下生成的遷移腳本是否正確�。
不用多講�,在你試圖遷移數(shù)據(jù)庫(kù)前必須做好備份,以防出現(xiàn)問(wèn)題���。不要在生產(chǎn)用的數(shù)據(jù)庫(kù)上運(yùn)行第一次使用的腳本�����,先在開發(fā)用的數(shù)據(jù)庫(kù)上運(yùn)行下���。
繼續(xù)前進(jìn)��,記錄下我們的遷移:
./db_migrate.py
腳本將打印出以下信息:
New migration saved as db_repository/versions/001_migration.py Current database version: 1
這個(gè)腳本信息顯示了遷移腳本的存放位置�,還有當(dāng)前數(shù)據(jù)庫(kù)的版本號(hào)�。空數(shù)據(jù)庫(kù)的版本號(hào)是0�����,當(dāng)我們導(dǎo)入users信息后版本號(hào)變?yōu)?.
數(shù)據(jù)庫(kù)的升級(jí)和回滾
現(xiàn)在你可能想知道為什么我們要做額外的工作來(lái)做數(shù)據(jù)庫(kù)的遷移記錄��。
試想一下��,你有個(gè)應(yīng)用在開發(fā)機(jī)器上���,同時(shí)服務(wù)器上也有一個(gè)復(fù)制的應(yīng)用正在運(yùn)行���。
比方說(shuō),在你產(chǎn)品的下個(gè)版本你的models層作了修改���,比如增加了一個(gè)新表�����。沒(méi)有遷移文件的話���,你需要同時(shí)解決在開發(fā)機(jī)和服務(wù)器上數(shù)據(jù)庫(kù)格式修改的問(wèn)題,這將是個(gè)很大的工作量���。
如果你已經(jīng)有了一個(gè)支持遷移的數(shù)據(jù)庫(kù)�,那么當(dāng)你向生產(chǎn)服務(wù)器發(fā)布新的應(yīng)用版本時(shí)�����,你只需要記錄下新的遷移記錄�,把遷移腳本拷貝到你的生產(chǎn)服務(wù)器上,然后運(yùn)行一個(gè)簡(jiǎn)單的應(yīng)用改變腳本就行���。數(shù)據(jù)庫(kù)的升級(jí)可以使用下面的Python腳本(filedb_upgrade.py):
frommigrate.versioningimportapi
fromconfigimport
SQLALCHEMY_DATABASE_URI
fromconfigimport
SQLALCHEMY_MIGRATE_REPO
api.upgrade(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO)
print'Current database version: '+str(api.db_version(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO))
當(dāng)你運(yùn)行上面的腳本時(shí)�����,數(shù)據(jù)庫(kù)將升級(jí)到最新版本��,并通過(guò)腳本將改變信息存儲(chǔ)到數(shù)據(jù)庫(kù)中�。
把數(shù)據(jù)庫(kù)回滾到舊的格式���,這是不常見的一個(gè)方式����,但以防萬(wàn)一,SQLAlchemy-migrate也很好的支持(filedb_downgrade.py):
frommigrate.versioningimportapi
fromconfigimport
SQLALCHEMY_DATABASE_URI
fromconfigimport
SQLALCHEMY_MIGRATE_REPO
v=api.db_version(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO)
api.downgrade(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO, v-1)
print'Current database version: '+str(api.db_version(
SQLALCHEMY_DATABASE_URI,
SQLALCHEMY_MIGRATE_REPO))
這個(gè)腳本將回滾數(shù)據(jù)庫(kù)的一個(gè)版本����,你可以通過(guò)運(yùn)行多次的方式向前回滾多個(gè)版本。
數(shù)據(jù)庫(kù)關(guān)聯(lián)
關(guān)系型數(shù)據(jù)庫(kù)最擅長(zhǎng)存儲(chǔ)數(shù)據(jù)之間的關(guān)系�。假如用戶會(huì)寫一篇微博,用戶的信息被存儲(chǔ)在users表中����,微博存儲(chǔ)在post表中。記錄誰(shuí)寫的微博最有效的方式是建立兩條數(shù)據(jù)之間的關(guān)聯(lián).
一旦用戶和微博的關(guān)系表建立之后�,我們有兩種查詢方式可以使用。.最瑣碎的一個(gè)就是當(dāng)你看到一篇微博���,你想知道是哪個(gè)用戶寫的�����。更復(fù)雜的一個(gè)是反向的查詢��,如果你知道一個(gè)用戶��,你想了解下他寫的全部微博�。Flask-SQLAlchemy將給我們提供對(duì)兩種方式查詢的幫助。
讓我們對(duì)數(shù)據(jù)做一下擴(kuò)展來(lái)存儲(chǔ)微博信息�����,這樣我們就能看到對(duì)應(yīng)的關(guān)系了��。我們回到我們使用的數(shù)據(jù)庫(kù)設(shè)計(jì)工具來(lái)創(chuàng)建個(gè)posts表:
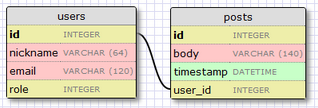
posts表包含一個(gè)必須的id,微博的內(nèi)容body��,還有一個(gè)時(shí)間戳�����。沒(méi)有什么新東西�����,但是user_id字段值得解釋下��。
我們想建立用戶和他們寫的微博之間的關(guān)聯(lián)�����,這種方法就是通過(guò)添加一個(gè)包含用戶id的字段來(lái)標(biāo)識(shí)誰(shuí)寫的微博�����,這個(gè)id叫做外鍵����。我們的數(shù)據(jù)庫(kù)設(shè)計(jì)工具也顯示了外鍵作為一個(gè)外鍵和id字段指向表的連接。這種關(guān)聯(lián)叫做一對(duì)多關(guān)聯(lián)����,也就是一個(gè)用戶可以寫多篇文章。
讓我們修改下models來(lái)響應(yīng)這些變化 (app/models.py):
fromappimportdb
ROLE_USER=0
ROLE_ADMIN=1
classUser(db.Model):
id=db.Column(db.Integer, primary_key=True)
nickname=db.Column(db.String(64), unique=True)
email=db.Column(db.String(120), unique=True)
role=db.Column(db.SmallInteger, default=ROLE_USER)
posts=db.relationship('Post', backref='author', lazy='dynamic')
def__repr__(self):
return'<User %r>'%(self.nickname)
classPost(db.Model):
id=db.Column(db.Integer, primary_key=True)
body=db.Column(db.String(140))
timestamp=db.Column(db.DateTime)
user_id=db.Column(db.Integer, db.ForeignKey('user.id'))
def__repr__(self):
return'<Post %r>'%(self.body)
我們?cè)黾恿艘粋€(gè)表示用戶寫的微博的Post類�����,user_id字段在Post類中被初始化指定為一個(gè)外鍵�����,因此Flask-SQLAlchemy會(huì)知道這個(gè)字段將會(huì)和用戶做關(guān)聯(lián)�����。
注意我們還在User類中添加了一個(gè)新字段命名為posts�,它被定義成一個(gè)db.relationship字段,這個(gè)字段并非是數(shù)據(jù)庫(kù)中實(shí)際存在的字段��,所以它不在我們的數(shù)據(jù)庫(kù)圖表中。對(duì)于一對(duì)多的關(guān)聯(lián)db.relationship字段通常只需要在一邊定義����。根據(jù)這個(gè)關(guān)聯(lián)我們可以獲取到用戶的微博列表。db.relationship的第一個(gè)參數(shù)表示“many”一方的類名���。backref參數(shù)定義了一個(gè)字段將"many"類的對(duì)象指回到"one"對(duì)象��,就我們而言�����,我們可以使用psot.author獲取到User實(shí)例創(chuàng)建一個(gè)微博。如果理解不了不要擔(dān)心���,在文章的后面我們將通過(guò)一個(gè)例子來(lái)解釋���。
讓我們用另外一個(gè)遷移文件記錄下這次的改變。簡(jiǎn)單運(yùn)行下面腳本:
./db_migrate.py
運(yùn)行腳本后將得到如下輸出:
New migration saved as db_repository/versions/002_migration.py Current database version: 2
我們沒(méi)必要每次都用一個(gè)獨(dú)立的遷移文件來(lái)記錄數(shù)據(jù)庫(kù)model層的小變化����,一個(gè)遷移文件通常只是記錄一個(gè)發(fā)布版本的改變。接下來(lái)更重要的事情是我們需要了解下遷移系統(tǒng)的工作原理�。
應(yīng)用實(shí)踐
我們已經(jīng)花了大量的時(shí)間在數(shù)據(jù)庫(kù)定義上��,但是我們?nèi)匀粵](méi)有看到他是如何工作的����,因?yàn)槲覀兊膽?yīng)用程序里沒(méi)有任何的數(shù)據(jù)相關(guān)的編碼����,接下來(lái)我們將在Python解釋器里使用我們的嶄新數(shù)據(jù)庫(kù)吧。
繼續(xù)前進(jìn)���,啟動(dòng)Python�����。 在 Linux 或者 OS X:
Windows下:
當(dāng)你在Python命令行提示符中輸入下面信息:
>>>fromappimportdb, models >>>
這樣我們的數(shù)據(jù)庫(kù)模塊和models就被加載到了內(nèi)存里.
讓我們來(lái)創(chuàng)建個(gè)新用戶:
>>> u=models.User(nickname='john', email='john@email.com', role=models.ROLE_USER)
>>> db.session.add(u)
>>> db.session.commit()
>>>
在同一個(gè)會(huì)話環(huán)境下更改數(shù)據(jù)庫(kù)����,多次的修改可以積累到一個(gè)會(huì)話中最后通過(guò)調(diào)用一個(gè)db.session.commit()命令提交���,提交同時(shí)也保證了原子性���。如果在會(huì)話中出現(xiàn)了錯(cuò)誤,會(huì)調(diào)用db.session.rollback()把數(shù)據(jù)庫(kù)回滾到會(huì)話之前的狀態(tài)。如果調(diào)用的既不是提交也不是回滾�����,那么系統(tǒng)會(huì)默認(rèn)回滾這個(gè)會(huì)話�。Sessions(會(huì)話)保證了數(shù)據(jù)庫(kù)的數(shù)據(jù)一致性。
讓我們來(lái)添加另外一個(gè)用戶:
>>> u=models.User(nickname='susan', email='susan@email.com', role=models.ROLE_USER)
>>> db.session.add(u)
>>> db.session.commit()
>>>
現(xiàn)在我們可以查詢出用戶信息:
>>> users=models.User.query.all()
>>>printusers
[<User u'john'>, <User u'susan'>]
>>>foruinusers:
... printu.id,u.nickname
...
1john
2susan
>>>
此處我們使用了query查詢函數(shù)����,在所有的model類中都可以使用這個(gè)函數(shù)。注意id是如何自動(dòng)生成的��。
還有另外一種方式來(lái)查詢��,如果我們知道了用戶的id����,我們可以使用下面的方式查找用戶信息:
>>> u=models.User.query.get(1)
>>>printu
<User u'john'>
>>>
現(xiàn)在讓我們添加一條微博信息:
>>>importdatetime
>>> u=models.User.query.get(1)
>>> p=models.Post(body='my first post!', timestamp=datetime.datetime.utcnow(), author=u)
>>> db.session.add(p)
>>> db.session.commit()
這個(gè)地方我們把時(shí)間設(shè)置為UTC時(shí)區(qū)�,所有的存儲(chǔ)在數(shù)據(jù)庫(kù)里的時(shí)間將是UTC格式,用戶可能在世界各地寫微博���,因此我們需要使用統(tǒng)一的時(shí)間單位��。在以后的教程中我們將學(xué)習(xí)如何在用戶本地時(shí)區(qū)使用這些時(shí)間�。
你也許注意到我們沒(méi)有在Post類中設(shè)置user_id字段����,取而代之的是把用戶對(duì)象存儲(chǔ)到了author字段�����。auhtor字段是個(gè)通過(guò)Flask-SQLAlchemy添加的虛擬字段用來(lái)建立關(guān)聯(lián)關(guān)系的���,我們之前已經(jīng)定義好了這個(gè)名字,參照:model中的db.relationship中backref參數(shù)����。通過(guò)這些信息,ORM層就能知道如何取到user_id����。
要完成這個(gè)會(huì)話,讓我們來(lái)看看更多可做的數(shù)據(jù)庫(kù)查詢:
# get all posts from a user
>>> u=models.User.query.get(1)
>>>printu
<User u'john'>
>>> posts=u.posts.all()
>>>printposts
[<Post u'my first post!'>]
# obtain author of each post
>>>forpinposts:
... printp.id,p.author.nickname,p.body
...
1john my first post!
# a user that has no posts
>>> u=models.User.query.get(2)
>>>printu
<User u'susan'>
>>>printu.posts.all()
[]
# get all users in reverse alphabetical order
>>>printmodels.User.query.order_by('nickname desc').all()
[<User u'susan'>, <User u'john'>]
>>>
要了解更多的數(shù)據(jù)庫(kù)查詢選項(xiàng)�,最好的方式就是去看 Flask-SQLAlchemy 的文檔。
在結(jié)束會(huì)話之前�����,我們把之前創(chuàng)建的測(cè)試用戶和文章刪除掉����,就可以在接下來(lái)的章節(jié)��,從一個(gè)干凈的數(shù)據(jù)庫(kù)開始:
>>> users=models.User.query.all()
>>>foruinusers:
... db.session.delete(u)
...
>>> posts=models.Post.query.all()
>>>forpinposts:
... db.session.delete(p)
...
>>> db.session.commit()
>>>
結(jié)束語(yǔ)
這一長(zhǎng)篇新手入門���,我們了解到了數(shù)據(jù)庫(kù)的基本操作,但我們還沒(méi)有將數(shù)據(jù)庫(kù)關(guān)聯(lián)到程序中���。在下一個(gè)章節(jié)中我們通過(guò)用戶登錄系統(tǒng)來(lái)練習(xí)所學(xué)的數(shù)據(jù)庫(kù)操作。
在此同時(shí)�����,如果你還沒(méi)開始寫程序�,你需要下載當(dāng)前文件 microblog-0.4.zip.注意,zip文件中沒(méi)有包括數(shù)據(jù)庫(kù)����,但是已經(jīng)有存儲(chǔ)腳本。用db_create.py創(chuàng)建一個(gè)新的數(shù)據(jù)庫(kù)����,用db_upgrade.py把你的數(shù)據(jù)庫(kù)升級(jí)到最新版本�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330