數(shù)據(jù)科學的基本內(nèi)容
什么是數(shù)據(jù)科學?它和已有的信息科學、統(tǒng)計學���、機器學習等學科有什么不同?作為一門新興的學科,數(shù)據(jù)科學依賴兩個因素:一是數(shù)據(jù)的廣泛性和多樣性;二是數(shù)據(jù)研究的共性?����,F(xiàn)代社會的各行各業(yè)都充滿了數(shù)據(jù)�����,這些數(shù)據(jù)的類型多種多樣��,不僅包括傳統(tǒng)的結(jié)構(gòu)化數(shù)據(jù)���,也包括網(wǎng)頁���、文本、圖像���、視頻�、語音等非結(jié)構(gòu)化數(shù)據(jù)�����。數(shù)據(jù)分析本質(zhì)上都是在解反問題,而且通常是隨機模型的反問題���,因此對它們的研究有很多共性�����。例如�,自然語言處理和生物大分子模型都用到隱馬爾科夫過程和動態(tài)規(guī)劃方法�����,其最根本的原因是它們處理的都是一維隨機信號;再如�����,圖像處理和統(tǒng)計學習中都用到的正則化方法��,也是處理反問題的數(shù)學模型中最常用的一種�����。

數(shù)據(jù)科學主要包括兩個方面:用數(shù)據(jù)的方法研究科學和用科學的方法研究數(shù)據(jù)�。前者包括生物信息學、天體信息學�、數(shù)字地球等領域;后者包括統(tǒng)計學、機器學習�����、數(shù)據(jù)挖掘�����、數(shù)據(jù)庫等領域��。這些學科都是數(shù)據(jù)科學的重要組成部分���,只有把它們有機地整合在一起�,才能形成整個數(shù)據(jù)科學的全貌����。
如何用數(shù)據(jù)的方法研究科學
用數(shù)據(jù)的方法研究科學,最典型的例子是開普勒關于行星運動的三大定律�。開普勒的三大定律是根據(jù)他的前任,一位叫第谷的天文學家留給他的觀察數(shù)據(jù)總結(jié)出來的�����。表1列出的觀測數(shù)據(jù)是行星繞太陽一周所需要的時間(以年為單位)和行星離太陽的平均距離(以地球與太陽的平均距離為單位)。從這組數(shù)據(jù)可以看出�,行星繞太陽運行的周期的平方和行星離太陽的平均距離的立方成正比,這就是開普勒第三定律����。
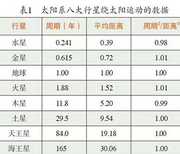
開普勒雖然總結(jié)出他的三大定律,但他并不理解其內(nèi)涵�。牛頓則不然,他用牛頓第二定律和萬有引力定律把行星運動歸結(jié)成一個純粹的數(shù)學問題����,即一個常微分方程組。如果忽略行星之間的相互作用�����,那么各行星和太陽之間就構(gòu)成了一個兩體問題���,我們很容易求出相應的解,并由此推導出開普勒的三大定律����。
牛頓運用的是尋求基本原理的方法,它遠比開普勒的方法深刻����。牛頓不僅知其然����,而且知其所以然�����。所以牛頓開創(chuàng)的尋求基本原理的方法成為科學研究的首選模式�����,這種方法的發(fā)展在20世紀初期達到了頂峰�����,在它的指導下��,物理學家們提出了量子力學�����。原則上講�,我們在日常生活中看到的自然現(xiàn)象都可以從量子力學出發(fā)得到解釋。量子力學提供了研究化學�、材料科學����、工程科學�、生命科學等幾乎所有自然和工程學科的基本原理,這應該說是很成功的����,但事情遠非這么簡單。狄拉克指出�,如果以量子力學的基本原理為出發(fā)點去解決這些問題,那么其中的數(shù)學問題就太困難了�����。因此必須妥協(xié)�,對基本原理作近似。
盡管牛頓模式很深刻����,但對復雜的問題��,開普勒模式往往更有效����。例如��,表2中形象地描述了一組人類基因組的單核苷酸多態(tài)性(Single
Nucleotide Polymorphism,
SNP)數(shù)據(jù)��。研究人員在全世界挑選出1064個志愿者�����,并把他們的SNP數(shù)據(jù)數(shù)字化��,即把每個位置上可能出現(xiàn)的10種堿基對用數(shù)字表示����,對這組數(shù)據(jù)做主成分分析(PCA)——一種簡單的數(shù)據(jù)分析方法��,其原理是對數(shù)據(jù)的協(xié)方差矩陣做特征值分解����,可以得到圖1所示的結(jié)果。其中橫軸和縱軸分別代表第一和第二奇異值所對應的特征向量�����,這些向量一共有1064個分量�,對應1064個志愿者。值得注意的是,這組點的顏色所代表的意義��。由此可見��,通過最常見的統(tǒng)計分析方法——主成分分析��,可以從這組數(shù)據(jù)中展示出人類進化的過程�����。
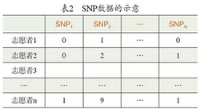
圖1 對SNP數(shù)據(jù)做主成分分析的結(jié)果[1]
如果采用從基本原理出發(fā)的牛頓模式��,上述問題基本是無法解決的�,而基于數(shù)據(jù)的開普勒模式則行之有效。開普勒模式最成功的例子是生物信息學和人類基因組工程�����,正因為它們的成功����,材料基因組工程等類似的項目也被提上了議程。同樣�,天體信息學、計算社會學等也成為熱門學科�����,這些都是用數(shù)據(jù)的方法研究科學問題的例子�。而圖像處理是另一個典型的例子。圖像處理是否成功是由人的視覺系統(tǒng)決定的��,要從根本上解決圖像處理的問題�����,就需要從理解人的視覺系統(tǒng)著手��,理解不同質(zhì)量的圖像對人的視覺系統(tǒng)會產(chǎn)生什么樣的影響����。當然,這樣的理解很深刻�����,而且也許是我們最終需要的��,但目前看來��,它過于困難也過于復雜�����,解決很多實際問題時并不會真正使用它,而是使用一些更為簡單的數(shù)學模型��。
用數(shù)據(jù)的方法研究科學問題���,并不意味著就不需要模型����,只是模型的出發(fā)點不一樣����,不是從基本原理的角度去尋找模型。以圖像處理為例�,基于基本原理的模型需要描述人的視覺系統(tǒng)以及它與圖像之間的關系,而通常的方法可以是基于更為簡單的數(shù)學模型��,如函數(shù)逼近的模型�。
如何用科學的方法研究數(shù)據(jù)
用科學的方法研究數(shù)據(jù)主要包括數(shù)據(jù)采集、數(shù)據(jù)存儲和數(shù)據(jù)分析����。本文將主要討論數(shù)據(jù)分析。
數(shù)據(jù)分析的中心問題
比較常見的數(shù)據(jù)有以下幾種類型��。
表格:最為經(jīng)典的數(shù)據(jù)類型。在表格數(shù)據(jù)中����,通常行代表樣本����,列代表特征;
點集(point cloud):很多數(shù)據(jù)都可以看成是某空間中的點的集合;
時間序列:文本、通話和DNA序列等都可以看成是時間序列��。它們也是一個變量(通常是時間)的函數(shù);
圖像:可以看成是兩個變量的函數(shù);
視頻:時間和空間坐標的函數(shù);
網(wǎng)頁和報紙:雖然網(wǎng)頁或報紙上的每篇文章都可以看成是時間序列�����,但整個網(wǎng)頁或報紙又具有空間結(jié)構(gòu);
網(wǎng)絡數(shù)據(jù):網(wǎng)絡本質(zhì)上是圖�����,由節(jié)點和聯(lián)系節(jié)點的邊構(gòu)成����。
除了上述基本數(shù)據(jù)類型外,還可以考慮更高層次的數(shù)據(jù)���,如圖像集���、時間序列集����、表格序列等�。
數(shù)據(jù)分析的基本假設是觀察到的數(shù)據(jù)都是由某個模型產(chǎn)生的,而數(shù)據(jù)分析的基本問題就是找出這個模型��。由于數(shù)據(jù)采集過程中不可避免會引入噪聲����,因此這些模型都是隨機模型。例如�����,點集對應的數(shù)據(jù)模型是概率分布�,時間序列對應的數(shù)據(jù)模型是隨機過程,圖像對應的數(shù)據(jù)模型是隨機場���,網(wǎng)絡對應的數(shù)據(jù)模型是圖模型和貝葉斯模型�。
通常我們對整個模型并不感興趣��,而只是希望找到模型的一部分內(nèi)容��。例如我們利用相關性來判斷兩組數(shù)據(jù)是否相關,利用排序來對數(shù)據(jù)的重要性進行排名�����,利用分類和聚類將數(shù)據(jù)進行分組等����。
很多情況下���,我們還需要對隨機模型作近似�。最常見的方法是將隨機模型近似為確定型模型����,所有的回歸模型和基于變分原理的圖像處理模型都采用了這種近似;另一類方法是對其分布作近似,例如假設概率分布是正態(tài)分布或假設時間序列是馬爾科夫鏈等��。
數(shù)據(jù)的數(shù)學結(jié)構(gòu)
要對數(shù)據(jù)作分析����,就必須先在數(shù)據(jù)集上引入數(shù)學結(jié)構(gòu)?���;镜臄?shù)學結(jié)構(gòu)包括度量結(jié)構(gòu)���、網(wǎng)絡結(jié)構(gòu)和代數(shù)結(jié)構(gòu)。
度量結(jié)構(gòu)����。在數(shù)據(jù)集上引進度量(距離),使之成為一個度量空間�。文本處理中的余弦距離函數(shù)就是一個典型的例子。
網(wǎng)絡結(jié)構(gòu)���。有些數(shù)據(jù)本身就具有網(wǎng)絡結(jié)構(gòu)����,如社交網(wǎng)絡;有些數(shù)據(jù)本身沒有網(wǎng)絡結(jié)構(gòu)����,但可以附加上一個網(wǎng)絡結(jié)構(gòu),例如度量空間的點集�,我們可以根據(jù)點與點之間的距離來決定是否把兩個點連接起來,這樣就得到一個網(wǎng)絡結(jié)構(gòu)��。網(wǎng)頁排名(PageRank)算法是利用網(wǎng)絡結(jié)構(gòu)的一個典型例子�。
代數(shù)結(jié)構(gòu)。把數(shù)據(jù)看成向量、矩陣或更高階的張量��。有些數(shù)據(jù)集具有隱含的對稱性����,也可以用代數(shù)的方法表達出來。
在上述數(shù)學結(jié)構(gòu)的基礎上����,可以討論更進一步的問題,例如拓撲結(jié)構(gòu)和函數(shù)結(jié)構(gòu)�����。
拓撲結(jié)構(gòu)����。從不同的尺度看數(shù)據(jù)集�,得到的拓撲結(jié)構(gòu)可能是不一樣的。最著名的例子是3×3的自然圖像數(shù)據(jù)集里面隱含著一個二維的克萊因瓶(Klein bottle)����。
函數(shù)結(jié)構(gòu)。對點集而言���,尋找其中的函數(shù)結(jié)構(gòu)是統(tǒng)計學的基本問題�。這里的函數(shù)結(jié)構(gòu)包括線性函數(shù)(用于線性回歸)、分片常數(shù)(用于聚類或分類)����、分片多項式(如樣條函數(shù))、其他函數(shù)(如小波展開)等���。
數(shù)據(jù)分析的主要困難
我們研究的數(shù)據(jù)通常有幾個特點:(1)數(shù)據(jù)量大���。數(shù)據(jù)量大給計算帶來挑戰(zhàn),需要一些隨機方法或分布式計算來解決問題;(2)數(shù)據(jù)維數(shù)高�����。例如��,前面提到的SNP數(shù)據(jù)是64萬維的;(3)數(shù)據(jù)類型復雜�。網(wǎng)頁、報紙���、圖像��、視頻等多種類型的數(shù)據(jù)給數(shù)據(jù)融合帶來困難;(4)噪音大���。數(shù)據(jù)在生成�����、采集���、傳輸和處理等流程中,均可能引入噪音�����,這些噪音的存在給數(shù)據(jù)清洗和分析帶來挑戰(zhàn)�,需要有一定修正功能的模型(如圖像中的正則化和機器學習中的去噪自編碼器)來進行降噪處理。
其中����,最核心的困難是數(shù)據(jù)維數(shù)高�。它會導致維數(shù)災難(curse of
dimensionality),即模型的復雜度和計算量隨著維數(shù)的增加而指數(shù)增長。那么�����,如何克服數(shù)據(jù)維數(shù)高帶來的困難?通常有兩類方法�����。一類是將數(shù)學模型限制在一個極小的特殊類里,如線性模型;另一類是利用數(shù)據(jù)可能有的特殊結(jié)構(gòu)����,如稀疏性、低維����、低秩和光滑性等。這些特性可以通過對模型作適當?shù)恼齽t化實現(xiàn)��,也可以通過降維方法實現(xiàn)�。
總之,數(shù)據(jù)分析本質(zhì)上是一個反問題�。處理反問題的許多方法(如正則化)在數(shù)據(jù)分析中扮演了重要角色,這正是統(tǒng)計學與統(tǒng)計力學的不同之處�。統(tǒng)計力學處理的是正問題,統(tǒng)計學處理的是反問題��。
算法的重要性
與模型相輔相成的是算法以及這些算法在計算機上的實現(xiàn)���。在數(shù)據(jù)量很大的情況下���,算法的重要性尤為突出�。從算法的角度來看���,處理大數(shù)據(jù)主要有兩條思路:
降低算法的復雜度����,即計算量����。通常要求算法的計算量是線性標度的,即計算量與數(shù)據(jù)量成線性關系����。但很多關鍵的算法,尤其是優(yōu)化方法�,還達不到這個要求。對于特別大的數(shù)據(jù)集���,如萬維網(wǎng)上的數(shù)據(jù)或社交網(wǎng)絡數(shù)據(jù)���,我們希望能有次線性標度的算法�����,也就是說計算量遠小于數(shù)據(jù)量。這就要求我們采用抽樣的方法��。其中最典型的例子是隨機梯度下降法(Stochastic
Gradient Descent, SGD)�。
分布式計算。其基本思想是把一個大問題分解成很多小問題���,然后分而治之����。著名的MapReduce框架就是一個典型的例子�����。
現(xiàn)階段���,算法的研究分散在兩個基本不相往來的領域——計算數(shù)學和計算機科學�。計算數(shù)學研究的算法主要針對像函數(shù)這樣的連續(xù)結(jié)構(gòu)�����,其主要應用對象是微分方程等;計算機科學主要處理離散結(jié)構(gòu)����,如網(wǎng)絡��。而現(xiàn)實數(shù)據(jù)的特點介于兩者之間�����,即數(shù)據(jù)本身是離散的����,而數(shù)據(jù)背后有一個連續(xù)的模型��。因此���,要發(fā)展針對數(shù)據(jù)的算法����,就必須把計算數(shù)學和計算機科學研究的算法有效地結(jié)合起來�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330