本文中,作者討論了 8 種在 Python 環(huán)境下進(jìn)行簡(jiǎn)單線性回歸計(jì)算的算法,不過沒有討論其性能的好壞,而是對(duì)比了其相對(duì)計(jì)算復(fù)雜度的度量。
GitHub 地址:https://github.com/tirthajyoti/PythonMachineLearning/blob/master/Linear_Regression_Methods.ipynb
對(duì)于大多數(shù)數(shù)據(jù)科學(xué)家而言,線性回歸方法是他們進(jìn)行統(tǒng)計(jì)學(xué)建模和預(yù)測(cè)分析任務(wù)的起點(diǎn)。但我們不可夸大線性模型(快速且準(zhǔn)確地)擬合大型數(shù)據(jù)集的重要性。如本文所示,在線性回歸模型中���,「線性」一詞指的是回歸系數(shù)��,而不是特征的 degree���。
特征(或稱獨(dú)立變量)可以是任何的 degree,甚至是超越函數(shù)(transcendental function)�����,比如指數(shù)函數(shù)����、對(duì)數(shù)函數(shù)、正弦函數(shù)���。因此,很多自然現(xiàn)象可以通過這些變換和線性模型來(lái)近似模擬���,即使當(dāng)輸出與特征的函數(shù)關(guān)系是高度非線性的也沒問題���。
另一方面,由于 Python 正在快速發(fā)展為數(shù)據(jù)科學(xué)家的首選編程語(yǔ)言���,所以能夠意識(shí)到存在很多方法用線性模型擬合大型數(shù)據(jù)集���,就顯得尤為重要�����。同樣重要的一點(diǎn)是�����,數(shù)據(jù)科學(xué)家需要從模型得到的結(jié)果中來(lái)評(píng)估與每個(gè)特征相關(guān)的重要性����。
然而��,在 Python 中是否只有一種方法來(lái)執(zhí)行線性回歸分析呢�����?如果有多種方法���,那我們應(yīng)該如何選擇最有效的那個(gè)呢����?
由于在機(jī)器學(xué)習(xí)中,Scikit-learn
是一個(gè)十分流行的 Python 庫(kù)����,因此,人們經(jīng)常會(huì)從這個(gè)庫(kù)調(diào)用線性模型來(lái)擬合數(shù)據(jù)��。除此之外��,我們還可以使用該庫(kù)的 pipeline 與
FeatureUnion
功能(如:數(shù)據(jù)歸一化���、模型回歸系數(shù)正則化�、將線性模型傳遞給下游模型)����,但是一般來(lái)看,如果一個(gè)數(shù)據(jù)分析師僅需要一個(gè)又快又簡(jiǎn)單的方法來(lái)確定回歸系數(shù)(或是一些相關(guān)的統(tǒng)計(jì)學(xué)基本結(jié)果)��,那么這并不是最快或最簡(jiǎn)潔的方法�。
雖然還存在其他更快更簡(jiǎn)潔的方法�����,但是它們都不能提供同樣的信息量與模型靈活性���。
請(qǐng)繼
有關(guān)各種線性回歸方法的代碼可以參閱筆者的 GitHub���。其中大部分都基于 SciPy 包
SciPy 基于 Numpy 建立�,集合了數(shù)學(xué)算法與方便易用的函數(shù)�����。通過為用戶提供高級(jí)命令����,以及用于操作和可視化數(shù)據(jù)的類,SciPy 顯著增強(qiáng)了 Python 的交互式會(huì)話��。
以下對(duì)各種方法進(jìn)行簡(jiǎn)要討論�����。
方法 1:Scipy.polyfit( ) 或 numpy.polyfit( )

這是一個(gè)非常一般的最小二乘多項(xiàng)式擬合函數(shù)�����,它適用于任何 degree 的數(shù)據(jù)集與多項(xiàng)式函數(shù)(具體由用戶來(lái)指定)�����,其返回值是一個(gè)(最小化方差)回歸系數(shù)的數(shù)組。
對(duì)于簡(jiǎn)單的線性回歸而言��,你可以把 degree 設(shè)為 1�。如果你想擬合一個(gè) degree 更高的模型,你也可以通過從線性特征數(shù)據(jù)中建立多項(xiàng)式特征來(lái)完成���。
詳細(xì)描述參考:https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.polyfit.html��。
方法 2:stats.linregress( )

這是
Scipy
中的統(tǒng)計(jì)模塊中的一個(gè)高度專門化的線性回歸函數(shù)��。其靈活性相當(dāng)受限�,因?yàn)樗粚?duì)計(jì)算兩組測(cè)量值的最小二乘回歸進(jìn)行優(yōu)化���。因此�,你不能用它擬合一般的線性模型�����,或者是用它來(lái)進(jìn)行多變量回歸分析��。但是���,由于該函數(shù)的目的是為了執(zhí)行專門的任務(wù)�����,所以當(dāng)我們遇到簡(jiǎn)單的線性回歸分析時(shí)�,這是最快速的方法之一����。除了已擬合的系數(shù)和截距項(xiàng)(intercept
term)外,它還會(huì)返回基本的統(tǒng)計(jì)學(xué)值如 R2 系數(shù)與標(biāo)準(zhǔn)差�。
詳細(xì)描述參考:http://blog.minitab.com/blog/adventures-in-statistics-2/regression-analysis-how-do-i-interpret-r-squared-and-assess-the-goodness-of-fit
方法 3:optimize.curve_fit( )

這個(gè)方法與 Polyfit 方法類似,但是從根本來(lái)講更為普遍��。通過進(jìn)行最小二乘極小化�����,這個(gè)來(lái)自 scipy.optimize 模塊的強(qiáng)大函數(shù)可以通過最小二乘方法將用戶定義的任何函數(shù)擬合到數(shù)據(jù)集上�。
對(duì)于簡(jiǎn)單的線性回歸任務(wù),我們可以寫一個(gè)線性函數(shù):mx+c����,我們將它稱為估計(jì)器�。它也適用于多變量回歸。它會(huì)返回一個(gè)由函數(shù)參數(shù)組成的數(shù)列,這些參數(shù)是使最小二乘值最小化的參數(shù)���,以及相關(guān)協(xié)方差矩陣的參數(shù)����。
詳細(xì)描述參考:https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html
方法 4:numpy.linalg.lstsq
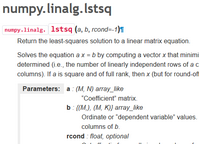
這是用矩陣因式分解來(lái)計(jì)算線性方程組的最小二乘解的根本方法�����。它來(lái)自 numpy 包中的線性代數(shù)模塊��。通過求解一個(gè) x 向量(它將|| b—a x ||2的歐幾里得 2-范數(shù)最小化)�,它可以解方程 ax=b。
該方程可能會(huì)欠定���、確定或超定(即��,a 中線性獨(dú)立的行少于����、等于或大于其線性獨(dú)立的列數(shù))���。如果 a 是既是一個(gè)方陣也是一個(gè)滿秩矩陣�����,那么向量 x(如果沒有舍入誤差)正是方程的解�����。
借助這個(gè)方法����,你既可以進(jìn)行簡(jiǎn)單變量回歸又可以進(jìn)行多變量回歸����。你可以返回計(jì)算的系數(shù)與殘差。一個(gè)小竅門是���,在調(diào)用這個(gè)函數(shù)之前,你必須要在 x 數(shù)據(jù)上附加一列 1�����,才能計(jì)算截距項(xiàng)���。結(jié)果顯示���,這是處理線性回歸問題最快速的方法之一。
詳細(xì)描述參考:https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.linalg.lstsq.html#numpy.linalg.lstsq
方法 5: Statsmodels.OLS ( )
statsmodel 是一個(gè)很不錯(cuò)的 Python 包����,它為人們提供了各種類與函數(shù),用于進(jìn)行很多不同統(tǒng)計(jì)模型的估計(jì)����、統(tǒng)計(jì)試驗(yàn),以及統(tǒng)計(jì)數(shù)據(jù)研究��。每個(gè)估計(jì)器會(huì)有一個(gè)收集了大量統(tǒng)計(jì)數(shù)據(jù)結(jié)果的列表�����。其中會(huì)對(duì)結(jié)果用已有的統(tǒng)計(jì)包進(jìn)行對(duì)比試驗(yàn)�����,以保證準(zhǔn)確性���。
對(duì)于線性回歸���,人們可以從這個(gè)包調(diào)用 OLS 或者是 Ordinary least squares 函數(shù)來(lái)得出估計(jì)過程的最終統(tǒng)計(jì)數(shù)據(jù)。
需要記住的一個(gè)小竅門是��,你必須要手動(dòng)為數(shù)據(jù) x 添加一個(gè)常數(shù)���,以用于計(jì)算截距���。否則�����,只會(huì)默認(rèn)輸出回歸系數(shù)�����。下方表格匯總了 OLS 模型全部的結(jié)果���。它和任何函數(shù)統(tǒng)計(jì)語(yǔ)言(如 R 和 Julia)一樣豐富����。
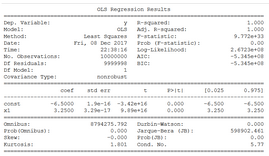
詳細(xì)描述參考:http://www.statsmodels.org/dev/index.html
方法6�、7:使用矩陣求逆方法的解析解
對(duì)于一個(gè)良態(tài)(well-conditioned)線性回歸問題(至少是對(duì)于數(shù)據(jù)點(diǎn)����、特征)��,回歸系數(shù)的計(jì)算存在一個(gè)封閉型的矩陣解(它保證了最小二乘的最小化)����。它由下面方程給出:
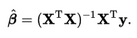
在這里,我們有兩個(gè)選擇:
方法 6:使用簡(jiǎn)單矩陣求逆乘法�。
方法 7:首先計(jì)算數(shù)據(jù) x 的廣義 Moore-Penrose 偽逆矩陣,然后將結(jié)果與 y 進(jìn)行點(diǎn)積��。由于這里第二個(gè)步驟涉及到奇異值分解(SVD)��,所以它在處理非良態(tài)數(shù)據(jù)集的時(shí)候雖然速度慢�����,但是結(jié)果不錯(cuò)���。(參考:開發(fā)者必讀:計(jì)算機(jī)科學(xué)中的線性代數(shù))
詳細(xì)描述參考:https://en.wikipedia.org/wiki/Linear_least_squares_%28mathematics%29
方法 8: sklearn.linear_model.LinearRegression( )
這個(gè)方法經(jīng)常被大部分機(jī)器學(xué)習(xí)工程師與數(shù)據(jù)科學(xué)家使用���。然而,對(duì)于真實(shí)世界的問題���,它的使用范圍可能沒那么廣�,我們可以用交叉驗(yàn)證與正則化算法比如 Lasso 回歸和 Ridge 回歸來(lái)代替它。但是要知道���,那些高級(jí)函數(shù)的本質(zhì)核心還是從屬于這個(gè)模型��。
詳細(xì)描述參考:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
以上方法的速度與時(shí)間復(fù)雜度測(cè)量
作為一個(gè)數(shù)據(jù)科學(xué)家����,他的工作經(jīng)常要求他又快又精確地完成數(shù)據(jù)建模����。如果使用的方法本來(lái)就很慢�����,那么在面對(duì)大型數(shù)據(jù)集的時(shí)候便會(huì)出現(xiàn)執(zhí)行的瓶頸問題���。
一個(gè)判斷算法能力可擴(kuò)展性的好辦法���,是用不斷擴(kuò)大的數(shù)據(jù)集來(lái)測(cè)試數(shù)據(jù),然后提取所有試驗(yàn)的執(zhí)行時(shí)間��,畫出趨勢(shì)圖。
可以在 GitHub 查看這個(gè)方法的代碼��。下方給出了最終的結(jié)果��。由于模型的簡(jiǎn)單性��,stats.linregress 和簡(jiǎn)單矩陣求逆乘法的速度最快�,甚至達(dá)到了 1 千萬(wàn)個(gè)數(shù)據(jù)點(diǎn)。

總結(jié)
作為一個(gè)數(shù)據(jù)科學(xué)家�,你必須要經(jīng)常進(jìn)行研究,去發(fā)現(xiàn)多種處理相同的分析或建模任務(wù)的方法�����,然后針對(duì)不同問題對(duì)癥下藥��。
在本文中����,我們討論了 8 種進(jìn)行簡(jiǎn)單線性回歸的方法。其中大部分方法都可以延伸到更一般的多變量和多項(xiàng)式回歸問題上�。我們沒有列出這些方法的 R2 系數(shù)擬合,因?yàn)樗鼈兌挤浅=咏?1��。
對(duì)于(有百萬(wàn)人工生成的數(shù)據(jù)點(diǎn)的)單變量回歸����,回歸系數(shù)的估計(jì)結(jié)果非常不錯(cuò)�。
這篇文章首要目標(biāo)是討論上述
8 種方法相關(guān)的速度/計(jì)算復(fù)雜度�����。我們通過在一個(gè)合成的規(guī)模逐漸增大的數(shù)據(jù)集(最大到 1
千萬(wàn)個(gè)樣本)上進(jìn)行實(shí)驗(yàn)�,我們測(cè)出了每種方法的計(jì)算復(fù)雜度。令人驚訝的是���,簡(jiǎn)單矩陣求逆乘法的解析解竟然比常用的 scikit-learn
線性模型要快得多��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330