機器學習:談談決策樹
今天��,我們繼續(xù)開啟分類算法之旅,它是一種高效簡介的分類算法�����,后面有一個集成算法正是基于它之上�����,它是一個可視化效果很好的算法���,這個算法就是決策樹。
1 一個例子
有一堆水果�����,其中有香蕉���,蘋果�,杏這三類,現在要對它們分類����,可以選擇的特征有兩個:形狀和大小,其中形狀的取值有個:圓形和不規(guī)則形��,大小的取值有:相對大和相對小?�,F在要對其做分類�����,我們可以這樣做:
首先根據特征:形狀���,如果不是圓形�����,那么一定是香蕉�����,這個就是葉子節(jié)點;
如果是圓形��,
再進一步根據大小這個特征判斷����,如果是相對大的,則是蘋果�,如果否,則是杏子�,至此我們又得到兩個葉子節(jié)點,并且到此分類位置����,都得到了正確劃分三種水果的方法�。
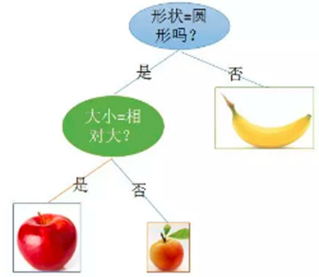
大家可以體會剛才這個過程,這就是一個決策分類����,構建樹的一個過程,說成是樹��,顯得有點高大上�����,再仔細想想就是一些列 if 和 else 的嵌套,說是樹只不過是邏輯上的一種神似罷了�。
剛才舉的這個例子,有兩個特征:形狀和大小���,并且選擇了第一個特征:形狀作為第一個分裂點���,大小作為第二個分裂點,那么不能選擇第二個特征作為第一分裂點嗎? 這樣選擇有沒有公式依據呢?
2 分裂點選擇依據
在上個例子中���,有三類水果���,現在假設杏都被我們家的寶寶吃完了,現在手里只有香蕉和蘋果這兩類水果了�,并且這個時候要對它們做分類,此時機靈的你����,一定會根據特征:形狀對它們分類了,因為這樣一下就會把它們分開了��,此時我們說這類集合的純度更高���,與之前的那三類水果在形狀這個特征上��。
純度這個概念是很好的理解的�����,種類越少純度越高�,自然兩類純度更高。 此時有人提出了一個和它相反的但是不那么容易理解的概念:熵���。它們是敵對雙方:熵越大���,純度越低;熵越小,純度越高����。
這是一種概念,那么如何用公式量化熵呢:
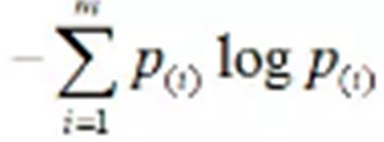
其中 i 等于蘋果��,香蕉�,杏�,P(i)是集合中取得某一個水果的概率。
試想一下����,如果我們想更好地對某個集合完成分類,會怎么做呢?我們一定會優(yōu)先選擇一個特征,使得以這個特征做分類時�,它們能最大程度的降低熵,提高分類的純度�,極限的情況是集合中100個元素(集合中只有兩類水果),根據某個最優(yōu)特征���,直接將分為兩類�����,一類都是蘋果�����,一類都是杏����,這樣熵直接等于0���。
這個特點就是所謂的信息增益�,熵降低的越多�,信息增益的就越多。很多時候都不會發(fā)生上述說的這個極限情況����,就像文章一開始舉的例子�,根據形狀劃分后����,熵變小了,但是未等于0����,比如剛開始三類水果的熵等于0.69,現在根據形狀分裂后��,熵等于了0.4��,所以信息增益為0.69
– 0.4 = 0.29 ��。如果根據大小劃分����,信息增益為0.1,那么我們回考慮第一個分裂特征:形狀���。
這種方法有問題嗎?
3 信息增益越大,分類效果越好?
這是只根據信息增益選擇分裂特征點的bug��,請看下面舉例。
如果某個特征是水果的唯一標示屬性:編號�����,那么此時如果選擇這個特征��,共得到100個葉子節(jié)點(假設這堆水果一共有100個)����,每個葉子節(jié)點只含有1個樣本,并且此時的信息增益最大為 0.69 – 0 = 0.69 �����。
但是��,這是好的分類嗎? 每一個樣本作為單獨的葉子節(jié)點�,當來了101號水果,都不知道劃分到哪一個葉子節(jié)點�����,也就不知道它屬于哪一類了!
因此���,這個問題感覺需要除以某個變量�����,來消除這種情況的存在����。
它就是信息增益率,它不光考慮選擇了某個分裂點后能獲得的信息增益���,同時還要除以分裂出來的這些節(jié)點的熵值����,什么意思呢? 剛才不是分裂出來100個節(jié)點嗎���,那么這些節(jié)點自身熵一共等于多少呢:
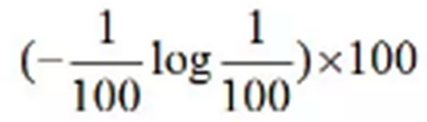
再除以上面這個數后����,往往信息增益率就不會那么大了�����。這就是傳說中的從ID3 到 C4.5 的改進�。
4 與熵的概念類似的基尼系數
只需要知道基尼系數和熵差不多的概念就行了,只不過量化的公式不同而已,這就說明理解了�����,至于公式長什么樣子�,用的時候去查就行了����。
讓我們看一下遠邊的大海,和海邊優(yōu)美的風景�����,放松一下吧!
5 展望
以上介紹了決策樹的一些概念和分裂點選取的基本方法�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330