數(shù)據(jù)分析—問卷調(diào)查從模型到算法
每個人心中都有一個完美的另一半,如何去找到這個自己心中最認可的另一半���,在慢慢人生旅途中�����,我們所經(jīng)歷過的事情�����,都在影響著我們的決定���,影響著我們對另一半的選擇����,這將是一個重大的問題���,關乎著自己未來的無論是物質(zhì)還是精神上的幸福���。這不僅僅是一個運氣的問題,還包含著巨大的人生智慧在其中��,用你獨具慧眼的原則和標準去判斷����。那么如何在長長的時間軸上判斷最優(yōu)秀的另一半是否出現(xiàn)了呢�?是否其中也有哲學在其中呢����?是否有量化的策略使得我們成功的幾率更大呢?
2.模型始于假設:
假設1:一切皆可量化�,兩個人在一起取決于價值,外貌���、性格����、潛力甚至于感情責任等等都可以被量化����,最終形成一個人的基本屬性——價值,價值越高則越優(yōu)秀����,選擇最優(yōu)秀的人為伴侶;
假設2:基于時間序列���,每接觸一個人在經(jīng)歷一段時間相處之后不具有可回溯性(即不考慮驚天大逆轉(zhuǎn),突然屌絲變高帥富)����,再次和前任談的時候��,考慮到人總是成長的�,前任以新的價值屬性出現(xiàn)��,作為挑選方���,對方價值的評估以當時那個時間節(jié)點不可變(人總會成長��,雖然過去的認知的價值在當前可能被貶低����,但被估值的人也會成長)�,對于價值的評估不會失誤到有近乎于極端異常值的判斷,在時間軸上異性有先后順序��;
假設3:挑選是單向的��,每個人都在尋找心中最高價值的TA��,并且知道會遇到多少個異性
模型的量化好壞取決于算法的優(yōu)劣����、假設的合理性���,基于以上假設,去推導其中算法:
現(xiàn)在我們的男主����,在時間軸上他會遇到N個我們的女主,男主要挑到最優(yōu)秀的真命女主�����,假定處于第i個女主是真命女主���,為了遇到這個這個真命女主����,男主需要去接觸k次女主����,作為對女主價值的認知,以便進行判斷對真命女主的價值的benchmark認知:
第一步:第i個女主是真命女主����,那么概率是1/N��。
第二步:benchmark的意義在與,前i個女主中��,比第i個真命女主價值小的次最大價值女主出現(xiàn)在試探性的1到k個女主中�,概率為k/(i-1),這個次最大價值女主為什么不是全域上的最大女主�����,因為我們遇到了第i個時�����,第i個女主是假定的最大價值女主��,我們不需要i+1到N去挑了��。同樣的道理��,一旦男主接觸試探了k個女主�����,次最大價值女主在1到k時���,那么k到i-1女主自然是不用再看了����,第一個比1到k中出現(xiàn)的次最大女主價值大的就是真命女主。
那么男主試探k個女主找到真命的概率就是:

3.結論分析
綜上可得�,目標函數(shù)可用。對目標函數(shù)求導�,發(fā)現(xiàn)x=1/e時,一階導數(shù)為0�����,x<1/e時導數(shù)為正���,x>1/e時則為負�,故而目標函數(shù)收斂于x=1/e��。代入x=1/e�,得到
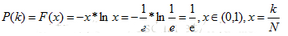
也就是說,當x=1/e的時候��,在我們的男主試探(認識了N*個女主)有最大的概率即約為37%的概率遇到我們的真命女主——那個我們男主最想要的的女主���。從理論模型我們回到現(xiàn)實����,也即是說當我們的男主在時間序列上遇到了100個女主(N=100),那么我們的男主要認識37次女主(k=37,)�����,以進行判斷真命女主����,在37次接觸中����,只要碰到從第37個開始,比前36個價值最高的女主還高�����,那么該女主就以最大可能性成為我們的最高價值女主����。那么這就是你最認可的另一半了。
實際生活中��,我們打交道的女生其實遠沒有那么多����,所以當我們認識幾個女生以后就開始“收斂”了�,從心里我們就認定彼此了�����。上述算法的結論一般性意義在與:
1.假如你對未來伴侶特別挑剔��,那你起碼應該適量的多認識幾個����,尤其是對于那些身邊異形很多的朋友,想要遇到自己中意的�����,可能就需要更多才能有一個比較理性的判斷�;
2.從“收斂”性看出,不是認識的異形越多越多就會遇到更優(yōu)秀的人����,往往越到最后就會成空。成為一個人的初戀意味著成為別人的“收斂”節(jié)點可能性更大���,假如你還可以重新加入TA的挑選隊列����,反言之初戀往往沒有好下場也是同樣的道理,人是會變的���,價值觀自然也會變��;
3.因為資源有限�,好的總是出手或者被出手快����,導致身邊的異性偏少��,越優(yōu)秀的會越快“收斂”�;反言之越優(yōu)秀可能最后就剩了下來,這是兩個極端情況���,實際生活中并不少見���,晚點結婚對于現(xiàn)代更開放的年輕人來說也是有優(yōu)勢的,處于中間則是最慘的——所以這大約也是被逼婚的重要原因���。
更多的結論在實際調(diào)查中是有待調(diào)研得出的......
我們要做的是能以最大化的幾率遇到最優(yōu)秀的人��,以最高的效率遇到你最中意的人��,然后就放手去追TA吧����!當然,也要去認識到模型的短板�,畢竟找到另一半是一個涉及方方面面,是個極為復雜的問題�。假設1缺陷在與量化的困難,一個人的價值不是裸露在外面就可以看到的��,不然也不會有這么多遇人不淑�;假設3的缺陷在與如何去確認N值的大小,雖然一個時期內(nèi)經(jīng)過一定時間的沉淀�����,身邊的異性是差不多固定的......這些都不用去管����,重要的是模型通過了,只需要添加一些問題:你身邊的異性朋友有多少�?你的性格是外向、一般、宅男���?等等這些問題�,只要人們對美的向往心無限����,那么我的模型和算法就有可取之處。
從上述模型和算法����,我們要知道,做數(shù)據(jù)分析和數(shù)據(jù)挖掘必須有著對數(shù)據(jù)的敏感性��,假如過去曾經(jīng)發(fā)生的事對于未來沒有任何影響的話�����,那么TA一定是失敗的�����,我覺得對于任何其他職業(yè)也是一樣����。在真正的數(shù)據(jù)挖掘和分析師看來,將來的事從來都不是隨機�,發(fā)生過的事情進過一定的“懲罰機制”去放大效果,對于將來的影響是巨大的����。一定幾率的事可以代表著將近絕對的概率發(fā)生,這并不是一句矛盾的話��。這正是機器學習的核心所在����,細小的變動,于細枝末節(jié)處慢慢的體現(xiàn)出對最終結果的影響�,發(fā)生過的數(shù)據(jù)一點點的推進學習的步伐,最后就能學習到一定規(guī)律的東西����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330