關(guān)于推薦算法的一些思考
最近做了一個(gè)交叉銷售的項(xiàng)目,梳理了一些關(guān)鍵點(diǎn)���,分享如下��,希望對(duì)大家有所啟發(fā)
核心目標(biāo):在有限資源下��,盡可能的提供高轉(zhuǎn)化率的用戶群��,輔助業(yè)務(wù)增長(zhǎng)
初步效果:商家ROI值為50以上�����,用戶日轉(zhuǎn)化率提升10倍以上���,用戶日最低轉(zhuǎn)化效果5pp以上
以下為正文:
數(shù)據(jù)準(zhǔn)備:
1.商品相關(guān)性
存在商品A,B,C...,商品之間用戶會(huì)存在行為信息的關(guān)聯(lián)度��,這邊可以參考協(xié)調(diào)過(guò)濾算法中的Item-based�,這邊拓展為用戶在不同商品之間的操作行為的差異性。
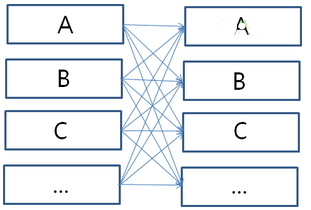
可以形成如下的特征矩陣:

這邊相關(guān)的常見度量方式有以下幾種:
a.距離衡量
包括瀏覽����、點(diǎn)擊、搜索等等各種行為的歐式�����、馬氏���、閔式����、切比雪夫距離�、漢明距離計(jì)算
b.相似度衡量
包括余弦相似度、杰卡德相似度衡量
c.復(fù)雜衡量
包括相關(guān)性衡量����,熵值衡量,互信息量衡量��,相關(guān)距離衡量
2.商品行為信息
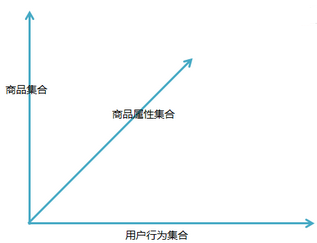
探求商品及其對(duì)應(yīng)行為信息的笛卡爾積的映射關(guān)系��,得到一個(gè)商品+用戶的行為魔方
商品集合:{商品A、商品B���、...}
商品屬性集合:{價(jià)格�����、是否打折��、相比其他電商平臺(tái)的比價(jià)����、是否缺貨...}
用戶行為集合:{瀏覽次數(shù)��、瀏覽時(shí)長(zhǎng)����、末次瀏覽間隔、搜索次數(shù)����、末次搜索間隔...}
通過(guò)商品集合*商品屬性集合*用戶行為集合,形成高維的商品信息魔方,再通過(guò)探查算法����,篩選優(yōu)秀表現(xiàn)的特征,這里推薦的有pca,randomforest的importance��,lasso變量壓縮����,相關(guān)性壓縮��,逐步回歸壓縮等方法��,根據(jù)數(shù)據(jù)的屬性特點(diǎn)可適當(dāng)選取方法
最后���,我們會(huì)得到如下一個(gè)待選特征組:
3.商品購(gòu)買周期
針對(duì)每一件商品���,都是有它自身的生命周期的,比如�,在三個(gè)月內(nèi)買過(guò)冰箱的用戶,95%以上的用戶是不會(huì)選擇二次購(gòu)買的���;而在1個(gè)月的節(jié)點(diǎn)上�����,會(huì)有20%的用戶會(huì)選擇二次購(gòu)買生活用紙���。所以我們需要做的一件事情就是不斷更新����,平臺(tái)上面每個(gè)類目下面的商品的自身生命周期����。除此之外,考慮在過(guò)渡時(shí)間點(diǎn)����,用戶的需求變化情況,是否可以提前觸發(fā)需求��;這邊利用��,艾賓浩斯遺忘曲線和因子衰減規(guī)律擬合:
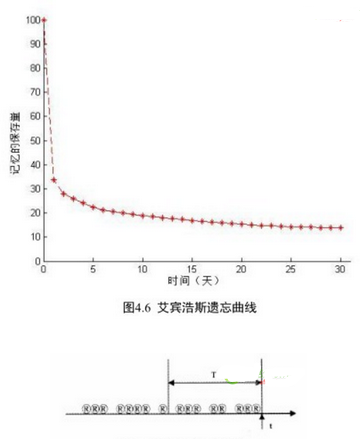
確定lamda和b�����,計(jì)算每個(gè)用戶對(duì)應(yīng)的每個(gè)類目����,當(dāng)前時(shí)間下的剩余價(jià)值:f(最高價(jià)值)*lamda*b
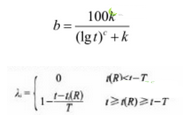
4.商品挖掘特征,用戶挖掘特征
業(yè)務(wù)運(yùn)營(yíng)過(guò)程中�����,通過(guò)數(shù)據(jù)常規(guī)可以得到1.基礎(chǔ)結(jié)論,2.挖掘結(jié)論���?��;A(chǔ)結(jié)論就是統(tǒng)計(jì)結(jié)論�����,比如昨日訂單量�����,昨日銷售量 ���,昨日用戶量�;挖掘結(jié)論就是深層結(jié)論���,比如昨日活躍用戶數(shù)���,每日預(yù)估銷售量���,用戶生命周期等
存在如下的探索形式,這是一個(gè)漫長(zhǎng)而又非常有價(jià)值的過(guò)程:
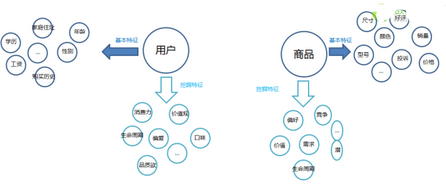
模型整合
再確定以上四大類的數(shù)據(jù)特征之后����,我們通過(guò)組合模型的方法,判斷用戶的交叉銷售結(jié)果
1.cart regression
確保非線性密度均勻數(shù)據(jù)擬合效果�,針對(duì)存在非線性關(guān)系且數(shù)據(jù)可被網(wǎng)格切分的產(chǎn)業(yè)用戶有高的預(yù)測(cè)能力
2.ridge regression
確保可線性擬合及特征繁多數(shù)據(jù)的效果�����,針對(duì)存在線性關(guān)系的產(chǎn)業(yè)用戶有高的預(yù)測(cè)能力
3.Svm-liner
確保線性且存在不可忽視的異常點(diǎn)的數(shù)據(jù)擬合效果���,針對(duì)存在異常用戶較多的部分產(chǎn)業(yè)用戶有高的預(yù)測(cè)能力
4.xgboost
確保數(shù)據(jù)復(fù)雜高維且無(wú)明顯關(guān)系的數(shù)據(jù)擬合效果����,針對(duì)存在維度高����、數(shù)據(jù)雜亂、無(wú)模型規(guī)律的部分產(chǎn)業(yè)用戶有高的預(yù)測(cè)能力
以上的組合模型并非固定���,也并非一定全部使用��,在確定自身產(chǎn)業(yè)的特點(diǎn)后�����,擇優(yōu)選擇���,然后采取投票��、加權(quán)����、分組等組合方式產(chǎn)出結(jié)果即可�。
附上推薦Rcode簡(jiǎn)述�����,
cart regression:
library(rpart)
fit <- rpart(y~x, data=database, method="class",control=ct, parms = list(prior = c(0.7,0.3), split = "information"));
## xval是n折交叉驗(yàn)證
## minsplit是最小分支節(jié)點(diǎn)數(shù)�,設(shè)置后達(dá)不到最小分支節(jié)點(diǎn)的話會(huì)繼續(xù)分劃下去
## minbucket:葉子節(jié)點(diǎn)最小樣本數(shù)
## maxdepth:樹的深度
## cp全稱為complexity parameter,指某個(gè)點(diǎn)的復(fù)雜度����,對(duì)每一步拆分,模型的擬合優(yōu)度必須提高的程度
## kyphosis是rpart這個(gè)包自帶的數(shù)據(jù)集
## na.action:缺失數(shù)據(jù)的處理辦法,默認(rèn)為刪除因變量缺失的觀測(cè)而保留自變量缺失的觀測(cè)����。
## method:樹的末端數(shù)據(jù)類型選擇相應(yīng)的變量分割方法:
## 連續(xù)性method=“anova”,離散型method=“class”,計(jì)數(shù)型method=“poisson”,生存分析型method=“exp”
## parms用來(lái)設(shè)置三個(gè)參數(shù):先驗(yàn)概率�����、損失矩陣��、分類純度的度量方法(gini和information)
## cost我覺得是損失矩陣����,在剪枝的時(shí)候�,葉子節(jié)點(diǎn)的加權(quán)誤差與父節(jié)點(diǎn)的誤差進(jìn)行比較,考慮損失矩陣的時(shí)候�����,從將“減少-誤差”調(diào)整為“減少-損失”
ridge regression:
library(glmnet)
glmmod<-glmnet(x,y,family = 'guassian',alpha = 0)
最小懲罰:
glmmod.min<-glmnet(x,y,family = 'gaussian',alpha = 0,lambda = glmmod.cv$lambda.min)
1個(gè)標(biāo)準(zhǔn)差下的最小懲罰:
glmmod.1se<-glmnet(x,y,family = 'gaussian',alpha = 0,lambda = glmmod.cv$lambda.1se)
Svm-liner :
library(e1071)
svm(x, y, scale = TRUE, type = NULL, kernel = "",degree = 3, gamma =
if (is.vector(x)) 1 else 1 / ncol(x),coef0 = 0, cost = 1, nu = 0.5,
subset, na.action = na.omit)
##type用于指定建立模型的類別:C-classification����、nu-classification、one-classification����、eps-regression和nu-regression
##kernel是指在模型建立過(guò)程中使用的核函數(shù)
##degree參數(shù)是指核函數(shù)多項(xiàng)式內(nèi)積函數(shù)中的參數(shù),其默認(rèn)值為3
##gamma參數(shù)給出了核函數(shù)中除線性內(nèi)積函數(shù)以外的所有函數(shù)的參數(shù)����,默認(rèn)值為l
##coef0參數(shù)是指核函數(shù)中多項(xiàng)式內(nèi)積函數(shù)與sigmoid內(nèi)積函數(shù)中的參數(shù)���,默認(rèn)值為0
##參數(shù)cost就是軟間隔模型中的離群點(diǎn)權(quán)重
##參數(shù)nu是用于nu-regression、nu-classification和one-classification類型中的參數(shù)
xgboost:
library(xgboost)
xgb <- xgboost(data = data.matrix(x[,-1]), label = y, eta =
0.1,max_depth = 15, nround=25, subsample = 0.5,colsample_bytree =
0.5,seed = 1,eval_metric = "merror",objective =
"multi:softprob",num_class = 12, nthread = 3)
##eta:默認(rèn)值設(shè)置為0.3���。步長(zhǎng)�,控制速度及擬合程度
##gamma:默認(rèn)值設(shè)置為0���。子樹葉節(jié)點(diǎn)個(gè)數(shù)
##max_depth:默認(rèn)值設(shè)置為6�。樹的最大深度
##min_child_weight:默認(rèn)值設(shè)置為1����?�?刂谱訕涞臋?quán)重和
##max_delta_step:默認(rèn)值設(shè)置為0��?����?刂泼靠脴涞臋?quán)重
##subsample: 默認(rèn)值設(shè)置為1�����。抽樣訓(xùn)練占比
##lambda and alpha:正則化
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330