SPSS教程:單因素多元方差分析(One-way MANOVA)
一、問題與數(shù)據(jù)
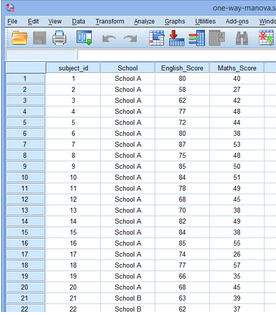
研究者想知道三所初中的學(xué)生學(xué)習(xí)成績(jī)是否不同���,因此從A��、B����、C三所學(xué)校隨機(jī)選擇20名學(xué)生���,并記錄了他們期末的英語成績(jī)和數(shù)學(xué)成績(jī)(英語成績(jī)記為English_Score��,數(shù)學(xué)成績(jī)記為Math_Score)��。自變量是School����,即學(xué)生來自的初中,分為三組��,分別為School
A���、School B和School C。部分?jǐn)?shù)據(jù)如下:
二�、對(duì)問題的分析
使用多元方差分析法進(jìn)行分析時(shí),需要考慮10個(gè)假設(shè)����。
對(duì)研究設(shè)計(jì)的假設(shè):
1.因變量有2個(gè)或以上,為連續(xù)變量����;
2.有一個(gè)自變量,為二分類或多分類變量����;
3.各觀察對(duì)象之間相互獨(dú)立。
對(duì)數(shù)據(jù)的假設(shè):
4.沒有單因素離群值(univariate outliers)與多因素離群值(multivariate outliers):?jiǎn)我蛩仉x群值是指自變量的各個(gè)組中因變量是否是離群值���;多因素離群值是指每個(gè)研究對(duì)象(case)的各因變量組合是否是一個(gè)離群值���;
5.各因變量服從多元正態(tài)分布����;
6.各因變量之間沒有多重共線性����;
7.自變量的各個(gè)組內(nèi),各因變量之間存在線性關(guān)系�;
8.樣本量足夠;
9.各組觀察對(duì)象因變量的方差協(xié)方差矩陣相等�;
10.每個(gè)因變量在自變量的各個(gè)組中方差相等。
三��、對(duì)假設(shè)的判斷
那么,進(jìn)行多元方差進(jìn)行分析時(shí),如何考慮和處理這10個(gè)假設(shè)呢���?
由于假設(shè)1-3都是對(duì)研究設(shè)計(jì)的假設(shè),需要研究者根據(jù)研究設(shè)計(jì)進(jìn)行判斷,所以我們主要對(duì)數(shù)據(jù)的假設(shè)4-10進(jìn)行檢驗(yàn)��。
(一) 檢驗(yàn)假設(shè)4�����、5:是否存在單因素離群值��、各因變量是否服從多元正態(tài)分布
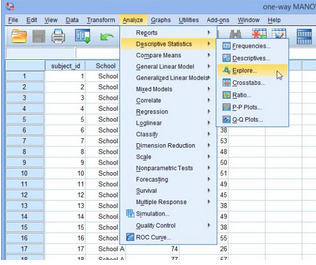
1.在主菜單點(diǎn)擊 Analyze > Descriptive Statistics > Explore...�,如下圖:
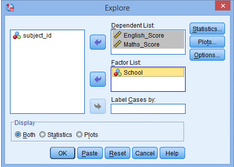
2.將English_Score和Math_Score選入Dependent List,將School選入Factor List�����,點(diǎn)擊Plots�;
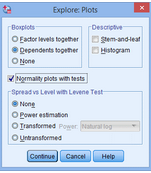
3.出現(xiàn)下圖Plots對(duì)話框��;
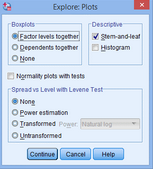
4.在Boxplots下選擇Dependents together���,去掉Descriptive下Stem-和-leaf�����,選擇Normality plots with tests��,點(diǎn)擊Continue���,點(diǎn)擊OK。
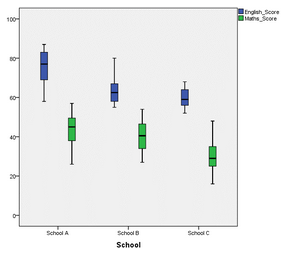
檢驗(yàn)假設(shè)4:是否存在單因素離群值
1.在輸出的箱式圖中,如下圖所示�,距離箱子邊緣超過1.5倍箱身長(zhǎng)度的數(shù)據(jù)點(diǎn)定義為離群值,在本例中��,未發(fā)現(xiàn)離群值����。
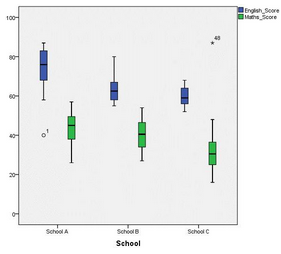
2.為了方便進(jìn)一步的理解,下面圖示是有離群值的箱式圖��,上下邊緣超過1.5倍箱式長(zhǎng)度為離群值�����,如下圖所示����,用“圓圈”表示,右上標(biāo)為離群值在數(shù)據(jù)表中所對(duì)應(yīng)的行數(shù)�,以圓點(diǎn)表示;將距離箱子邊緣超過3倍箱身長(zhǎng)度的數(shù)據(jù)點(diǎn)定義為極端值(極端離群值)�����,用“*”表示����,右上標(biāo)代表離群值在數(shù)據(jù)表中所對(duì)應(yīng)的行數(shù)�����。因此��,在箱式圖中查看離群值時(shí)���,可以直接看“圓圈”或“*”。
3.離群值的處理
數(shù)據(jù)中存在離群值的原因有3種:
(1) 數(shù)據(jù)錄入錯(cuò)誤:首先應(yīng)該考慮離群值是否由于數(shù)據(jù)錄入錯(cuò)誤所致�。如果是,用正確值進(jìn)行替換并重新進(jìn)行檢驗(yàn)��;
(2) 測(cè)量誤差:如果不是由于數(shù)據(jù)錄入錯(cuò)誤��,接下來考慮是否因?yàn)闇y(cè)量誤差導(dǎo)致(如儀器故障或超過量程)���,測(cè)量誤差往往不能修正,需要把測(cè)量錯(cuò)誤的數(shù)據(jù)刪除�;
(3) 真實(shí)存在的離群值:如果以上兩種原因都不是,那最有可能是一種真實(shí)的極端數(shù)據(jù)����。這種離群值不好處理�,但也沒有理由將其當(dāng)作無效值看待�����。目前它的處理方法比較有爭(zhēng)議�����,尚沒有一種特別推薦的方法����。
需要注意的是,如果存在多個(gè)離群值�����,應(yīng)先把最極端的離群值去掉后�����,重新檢查離群值情況�。這是因?yàn)橛袝r(shí)最極端離群值去掉后,其他離群值可能會(huì)回歸正常�。
離群值的處理方法分為2種:
(1) 保留離群值:
1) 對(duì)因變量進(jìn)行數(shù)據(jù)轉(zhuǎn)換;
2) 將離群值納入分析�����,并堅(jiān)信其對(duì)結(jié)果不會(huì)產(chǎn)生實(shí)質(zhì)影響。
(2) 剔除離群值:
直接刪除離群值很簡(jiǎn)單���,但卻是沒有辦法的辦法�。當(dāng)我們需要?jiǎng)h掉離群值時(shí)�,應(yīng)報(bào)告離群值大小及其對(duì)結(jié)果的影響,最好分別報(bào)告刪除離群值前后的結(jié)果����。而且,應(yīng)該考慮有離群值的個(gè)體是否符合研究的納入標(biāo)準(zhǔn)�����。如果其不屬于合格的研究對(duì)象���,應(yīng)將其剔除�,否則會(huì)影響結(jié)果的推論��。
檢驗(yàn)假設(shè)5:各因變量是否服從多元正態(tài)分布

1.對(duì)于樣本量較小(<50例)的研究����,推薦使用Shapiro-Wilk 方法檢驗(yàn)正態(tài)性。當(dāng)P<0.05時(shí)�����,認(rèn)為不是正態(tài)分布�����。本例中��,P均大于0.05���,說明每所學(xué)校的英語成績(jī)和數(shù)學(xué)成績(jī)均服從正態(tài)分布�����。
2.不服從正態(tài)分布的處理
如果數(shù)據(jù)不服從正態(tài)分布����,可以有如下2種方法進(jìn)行處理:
(1) 數(shù)據(jù)轉(zhuǎn)換:對(duì)轉(zhuǎn)換后呈正態(tài)分布的數(shù)據(jù)進(jìn)行方差分析�����。當(dāng)各組因變量的分布相同時(shí)�����,正態(tài)轉(zhuǎn)換才有可能成功。對(duì)于一些常見的分布���,有特定的轉(zhuǎn)換形式���,但是轉(zhuǎn)換后的數(shù)據(jù)結(jié)果可能較難解釋。
(2) 直接進(jìn)行分析:由于多元方差分析對(duì)于偏離正態(tài)分布有一定的抗性�,尤其是在各組樣本量相等或近似相等的情況下,而且非正態(tài)分布實(shí)質(zhì)上并不影響犯I型錯(cuò)誤的概率���。因此可以直接進(jìn)行檢驗(yàn)�����,但是結(jié)果中需要報(bào)告對(duì)正態(tài)分布的偏離�����。
(二) 檢驗(yàn)假設(shè)6:各因變量之間是否存在多重共線性
1.在主菜單下點(diǎn)擊 Correlate > Bivariate...��,如下圖所示:
2.將English_Score和Math_Score選入Variables�����,點(diǎn)擊OK����。
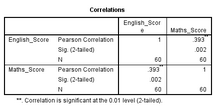
3.結(jié)果如下圖所示�����,可以看到English_Score和Math_Score的Pearson相關(guān)系數(shù)���。理想狀態(tài)下���,在做多元方差分析時(shí),各個(gè)因變量之間應(yīng)該存在一定程度的相關(guān)關(guān)系����,但相關(guān)性不能太強(qiáng),如果相關(guān)性太強(qiáng)(高于0.9)��,則存在多重共線性�,多元方差分析的假設(shè)則不再滿足。
在下表中English_Score和Math_Score的Pearson相關(guān)系數(shù)為0.393�����,兩因變量間存在輕度的相關(guān)關(guān)系,不存在多重共線性(|r| < 0.9)����。
4.存在多重共線性的處理方法
如果數(shù)據(jù)具有多重共線性,可以有如下2種方法進(jìn)行處理:
(1) 刪除具有多重共線性的一個(gè)因變量�,也是最常用的方法;
(2) 可以通過主成分分析將具有多重共線性的多個(gè)因變量匯總成一個(gè)新的因變量�����。
(三) 檢驗(yàn)假設(shè)7:自變量的各個(gè)組內(nèi)��,各因變量之間存在線性關(guān)系
1.在主菜單下點(diǎn)擊Data > Split File... �,如下圖所示:
2.出現(xiàn)下圖Split File對(duì)話框;
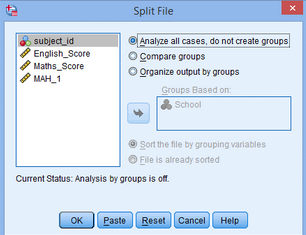
3.點(diǎn)擊Organize output by groups����,將School選入Groups Based on下的框內(nèi),點(diǎn)擊OK�。
4.在主菜單點(diǎn)擊 Graphs > Chart Builder...,如下圖所示:
5.出現(xiàn)Chart Builder對(duì)話框
6.從Choose from選擇Scatter/Dot����,在中下部的8種圖形中�����,選擇下數(shù)第三個(gè)(如果點(diǎn)擊這個(gè)圖標(biāo)會(huì)出現(xiàn)“Scatterplot Matrix”字樣),并拖拽到主對(duì)話框中�����;
7.出現(xiàn)下圖:
8.將English_Score和Math_Score拖入主對(duì)話框中��,下方會(huì)出現(xiàn) “+”標(biāo)記��,如下圖所示�����;
9.出現(xiàn)下圖����,點(diǎn)擊OK
10.在下面輸出的結(jié)果中,不難看出���,在A����、B學(xué)校中,數(shù)學(xué)成績(jī)和英語成績(jī)均存在線性關(guān)系��,然而���,在C學(xué)校中�, 線性關(guān)系難以判斷�����。為了后續(xù)進(jìn)行多元方差分析�,我們?cè)诖私邮苊克鶎W(xué)校中數(shù)學(xué)成績(jī)和英語成績(jī)存在線性關(guān)系的假設(shè)。
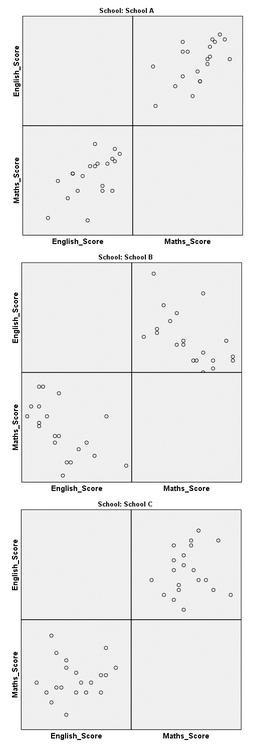
注:如果不會(huì)判斷線性關(guān)系�,可以參考下圖,從眼睛判斷大致的關(guān)系��。
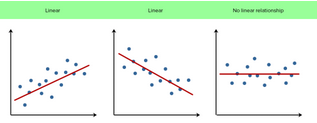
如果不存在線性關(guān)系�����,可以通過3種方式進(jìn)行處理:(1) 對(duì)1個(gè)或多個(gè)因變量進(jìn)行轉(zhuǎn)換����;(2) 去除掉不存在線性關(guān)系的因變量; (3) 直接進(jìn)行分析�����,盡管統(tǒng)計(jì)效能會(huì)降低。
(四) 檢驗(yàn)假設(shè)4: 是否存在多因素離群值
在SPSS中�,有許多方法可以檢驗(yàn)多因素離群值,但是在單因素多元方差分析中的多因素離群值�����,一般推薦用馬氏距離(Mahalanobis distance)來判斷是否存在多因素離群值�。馬氏距離一般應(yīng)用于多因素回歸分析�,在SPSS的Regression procedure中可以計(jì)算馬氏距離。
1.在步驟(三)數(shù)據(jù)拆分的情況下��, 在主菜單下點(diǎn)擊 Analyze >Regression >Linear...����,如下圖所示:
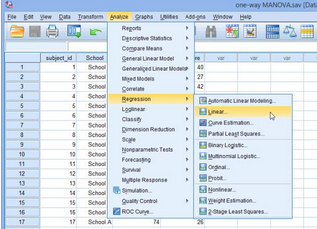
2.出現(xiàn)Linear Regression對(duì)話框,將subject_id選入Dependent框中�,將English_Score和Maths_Score選入Independent(s)中,如下圖所示:
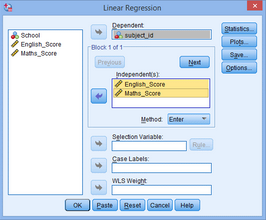
3.點(diǎn)擊Save�,出現(xiàn)Linear Regression:Save對(duì)話框,點(diǎn)擊Distances下的Mahalanobis�����,即馬氏距離,點(diǎn)擊Continue��,點(diǎn)擊OK�����。
4.在主界面下�����,可以看到出現(xiàn)新變量MAH_1����;
5.選中MAH_1變量,右鍵��,選擇Sort Descending��,對(duì)新變量進(jìn)行降序排列����;
6.如下圖所示,是對(duì)馬氏距離降序排列后的數(shù)據(jù)界面��;
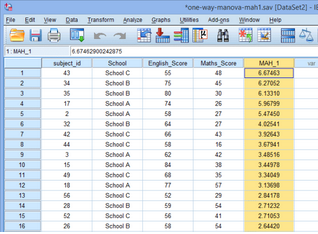
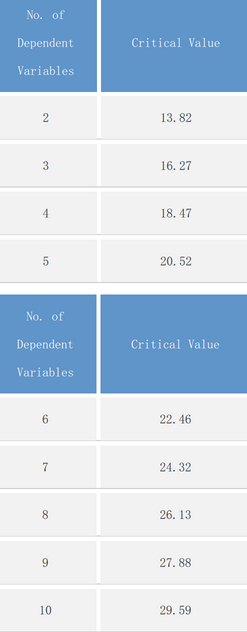
7.馬氏距離需要根據(jù)下表中Critical
Value進(jìn)行對(duì)比���,下表中Critical
Value是在α=0.001時(shí)不同變量數(shù)對(duì)應(yīng)的卡方分布的卡方值����,由于本例中因變量有2個(gè),對(duì)應(yīng)的Critical
Value為13.82���,而本例中馬氏距離最大值為6.67463<13.82����,所以不存在多因素離群值��。
如果存在多因素離群值���,處理方法分為2種:
(1) 保留離群值:
1) 將因變量轉(zhuǎn)換成其他形式;
2) 將離群值納入分析��,當(dāng)樣本量較大時(shí)�����,多元方差分析對(duì)多因素離群值較為穩(wěn)健����。
(2) 剔除離群值:
直接刪除離群值很簡(jiǎn)單����,是常用的辦法�����。當(dāng)我們需要?jiǎng)h掉離群值時(shí)�����,應(yīng)該注意一個(gè)離群值可能會(huì)掩蓋另一個(gè)離群值的存在����。所以在刪除離群值后,應(yīng)重新進(jìn)行對(duì)假設(shè)的檢驗(yàn)���。最后需要在結(jié)果中報(bào)告刪除的離群值和原因�����。
8.需要去除之前對(duì)數(shù)據(jù)的拆分�����。在主菜單下點(diǎn)擊Data > Split File...����,如下圖所示:
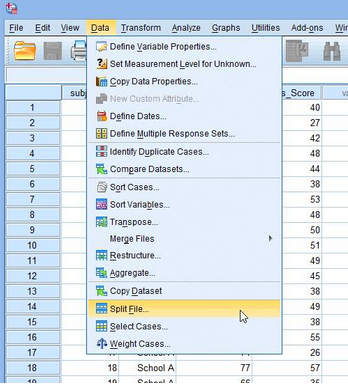
9.出現(xiàn)Split File對(duì)話框,點(diǎn)擊Analyze all cases�,do not create groups,點(diǎn)擊OK。
四����、多元方差的SPSS操作
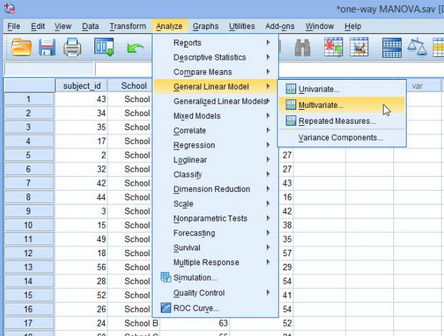
1.在主菜單下點(diǎn)擊Analyze >General Linear Model >Multivariate...,如下圖所示:
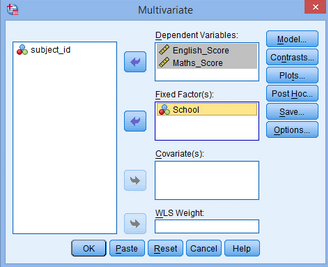
2.出現(xiàn)Multivariate對(duì)話框�,將English_Score和Maths_Score選入Dependent Variables,將School選入Fixed Factor(s)���,點(diǎn)擊Post Hoc��;
3.出現(xiàn)Multivariate:
Post Hoc Multiple Comparisons for Observed Means對(duì)話框�,將School選入Post Hoc
Tests for�����,在Equal Variances Assumed下方選擇Tukey����,點(diǎn)擊Continue���;
4.點(diǎn)擊Options����,出現(xiàn)Multivariate: Options對(duì)話框,如下圖所示���;
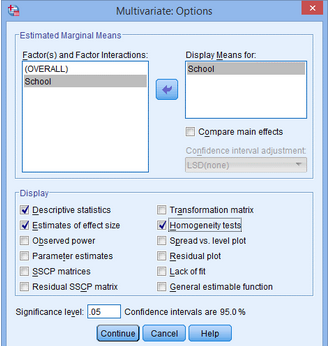
5.將School選入Display Means for:下方���,勾選Display下方的Descriptive statistics、Estimates of effect size和Homogeneity tests�,點(diǎn)擊Continue,點(diǎn)擊OK�。
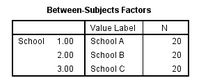
檢驗(yàn)假設(shè)8:樣本量足夠
多元方差分析中的樣本量足夠是指自變量的每組中的例數(shù)要不少于因變量個(gè)數(shù),本例中因變量有2個(gè)����,所以自變量每組中至少有2例才能滿足樣本量足夠的假設(shè)。在輸出的結(jié)果的Between-Subjects Factors表中可以看到每組20例�,滿足條件。
檢驗(yàn)假設(shè)9:各組觀察對(duì)象因變量的方差協(xié)方差矩陣相等
在輸出的結(jié)果的Box's Test of Equality of Covariance Matrices表中���,如果P<0.001�����,則違反了協(xié)方差矩陣相等的假設(shè)�����;如果P>0.001��,則協(xié)方差矩陣相等的假設(shè)成立��。

本例中���,P=0.003>0.001, 所以各組觀察對(duì)象因變量的方差協(xié)方差矩陣相等的假設(shè)成立�。大家可能注意到此時(shí)的顯著性水平是0.001而非0.05���,這是由于該檢驗(yàn)的敏感性所以下調(diào)了顯著性水平��。
檢驗(yàn)假設(shè)10:每個(gè)因變量在自變量的各個(gè)組中是否方差相等�。
在輸出的結(jié)果的Levene's Test of Equality of Error Variances表中�����,該檢驗(yàn)中如果P<0.05�����,則方差不相等���;如果P>0.05�,則方程相等�����。本例中����,P值均大于0.05,所以方差相等的假設(shè)成立����。
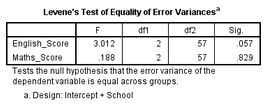
如果檢驗(yàn)發(fā)現(xiàn)方差不等,有2種方法進(jìn)行處理:(1)對(duì)因變量進(jìn)行轉(zhuǎn)換��,并重新進(jìn)行所有的檢驗(yàn)����;(2)不進(jìn)行處理,并接受較低的α水平����,即犯I類錯(cuò)誤的概率可能增大���。
五、結(jié)果解釋
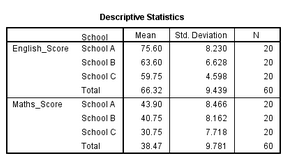
1. 描述性統(tǒng)計(jì)結(jié)果
(1)
在Descriptive
Statistics表中�,分別給出了三個(gè)英語成績(jī)和數(shù)學(xué)成績(jī)?cè)谌鶎W(xué)校的均值、標(biāo)準(zhǔn)差和例數(shù)��。A�、B、C三所學(xué)校學(xué)生的英語成績(jī)(分別為75.6 ±
8.2�����,63.6 ± 6.6和59.8 ± 4.6)均高于他們的數(shù)學(xué)成績(jī)(分別為43.9 ± 8.5��,40.8 ± 8.2和30.8 ±
7.7)���。
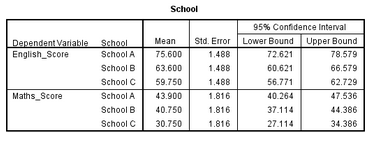
(2) 在School表中�����,還給出了均值的置信區(qū)間��,如下表所示�,在此不做贅述����。
2. 多元方差分析結(jié)果
(1)在Multivariate Tests表中,Pillai's Trace���、Wilks' Lambda��、 Hotelling's Trace和Roy's Largest Root為四個(gè)多元統(tǒng)計(jì)量���,用于檢驗(yàn)組間差異。最常用的統(tǒng)計(jì)量為Wilks' Lambda���,該檢驗(yàn)P<0.05時(shí)�,自變量的組間差異具有統(tǒng)計(jì)學(xué)意義��。
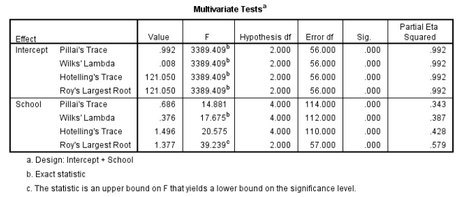
本例中F=17.675��,P<0.001�,Wilks' Lambda =0.376; partial η2=0.387,所以各學(xué)校的學(xué)生學(xué)習(xí)成績(jī)存在的差異具有統(tǒng)計(jì)學(xué)意義�。
(2)Tests of Between-Subjects Effects表實(shí)際上是對(duì)因變量單獨(dú)進(jìn)行一元方差分析的結(jié)果。
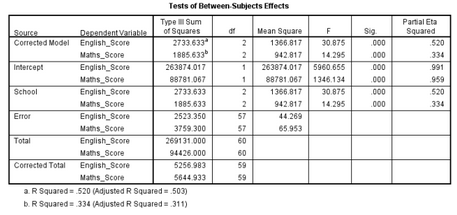
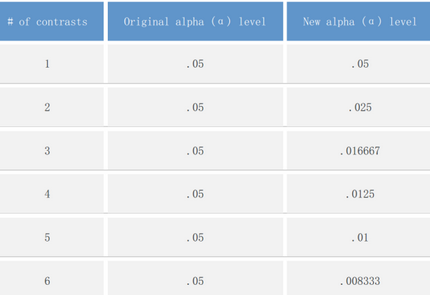
本例中共有2個(gè)因變量��,所以α水平需要進(jìn)行校正,采用Bonferroni方法對(duì)顯著性水平α進(jìn)行校正�����,調(diào)整后的α水平為0.025(可參考下表)����。
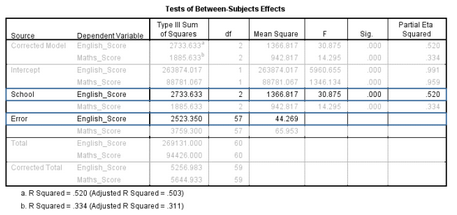
如下表中突出顯示的部分,來自不同學(xué)校的學(xué)生英語成績(jī)的差異具有統(tǒng)計(jì)學(xué)意義�����,F(xiàn)=30.875��,P<0.001�����,partial η2= 0.520����。
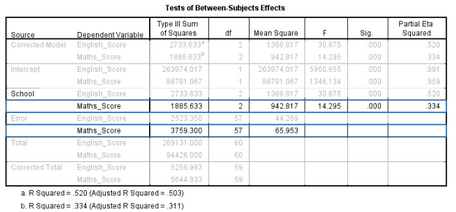
如下表中突出顯示的部分,來自不同學(xué)校的學(xué)生數(shù)學(xué)成績(jī)的差異具有統(tǒng)計(jì)學(xué)意義�����,F(xiàn)=14.295,P<0.001�����;partial η2=0.334�����。
(3)如果任何一個(gè)一元方差分析具有統(tǒng)計(jì)學(xué)意義���,就需要進(jìn)行多重比較。一般用Tukey post-hoc tests方法檢驗(yàn)�。如果違反了方差相等的假設(shè),可以用Games-Howell post-hoc test方法���。
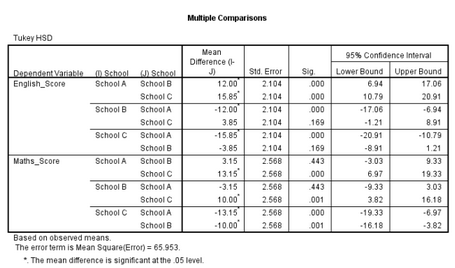
Tukey post-hoc檢驗(yàn)顯示���,來自A學(xué)校的學(xué)生的英語平均成績(jī)顯著高于來自B(P<0.001)和C學(xué)校的學(xué)生(P<0.001),但未發(fā)現(xiàn)來自B學(xué)校的學(xué)生和來自C學(xué)校的學(xué)生英語平均成績(jī)存在差異(P=0.169)�;
對(duì)于數(shù)學(xué)成績(jī),Tukey post-hoc檢驗(yàn)顯示���,來自C學(xué)校的學(xué)生數(shù)學(xué)平均成績(jī)顯著低于來自A學(xué)校(P<0.001)和B學(xué)校(P=0.001)的學(xué)生�,但未發(fā)現(xiàn)來自A學(xué)校的學(xué)生和來自B學(xué)校的學(xué)生數(shù)學(xué)平均成績(jī)存在差異(P=0.443)。
此處詳細(xì)的解釋請(qǐng)參考:?jiǎn)我蛩?a href='/map/fangchafenxi/' style='color:#000;font-size:inherit;'>方差分析��,我見過的最詳細(xì)SPSS教程�。
(4)邊際均值與輪廓圖
除上述結(jié)果外,SPSS還給出了English_Score和Math_Score的邊際均值輪廓圖����,較為直觀地反映各組因變量情況。邊際均值是值基于現(xiàn)有模型�����,當(dāng)控制了其他因素的作用時(shí)����,根據(jù)樣本情況計(jì)算出的用于比較各水平的均值估計(jì)值。然而�����,該圖并沒有太大的參考價(jià)值��,在此不作詳述�。
六、撰寫結(jié)論
運(yùn)用多元方差分析方法,分析入學(xué)前所在學(xué)校對(duì)學(xué)生學(xué)習(xí)表現(xiàn)的影響���。學(xué)生的學(xué)習(xí)表現(xiàn)主要通過英語和數(shù)學(xué)期末考試成績(jī)體現(xiàn)�����,學(xué)生來自三所A����、B����、C三所學(xué)校����。
分析前,對(duì)方法的假設(shè)進(jìn)行檢驗(yàn):Shapiro-Wilk檢驗(yàn)顯示因變量服從正態(tài)分布(P>0.05)����;通過箱式圖未發(fā)現(xiàn)單因素離群值,通過馬氏距離未發(fā)現(xiàn)多元離群值(P>0.001)�����;散點(diǎn)圖發(fā)現(xiàn)因變量間存在線性關(guān)系�;English_Score和Math_Score的Pearson相關(guān)系數(shù)為0.393��,兩因變量間存在輕度的相關(guān)關(guān)系�����,不存在多重共線性(r=0.393�����,P=0.002); Box's M檢驗(yàn)顯示方差的協(xié)方差矩陣相等(P=0.003)�����。
A�、B��、C三所學(xué)校學(xué)生的英語成績(jī)(分別為75.6 ± 8.2�����,63.6 ± 6.6和59.8 ± 4.6)均高于他們的數(shù)學(xué)成績(jī)(分別為43.9 ± 8.5��,40.8 ± 8.2和30.8 ± 7.7)����。
各學(xué)校的學(xué)生學(xué)習(xí)成績(jī)存在的差異具有統(tǒng)計(jì)學(xué)意義�����,F(xiàn)=17.675�����,P<0.001�,Wilks' Lambda = 0.376; partial η2=0.387�。
單因素方差分析顯示三所學(xué)校學(xué)生的英語成績(jī)(F=30.875,P<0.0005;partial η2=0.520)和數(shù)學(xué)成績(jī)(F=14.295,P<0.001����;partial η2=0.334)均存在差異�,采用Bonferroni法進(jìn)行校正的α水平為0.025。
Tukey post-hoc檢驗(yàn)顯示���,來自A學(xué)校的學(xué)生的英語平均成績(jī)顯著高于來自B(P<0.001)和C學(xué)校的學(xué)生(P<0.001)�,但未發(fā)現(xiàn)來自B學(xué)校的學(xué)生和來自C學(xué)校的學(xué)生英語平均成績(jī)存在差異(P=0.169)����;
對(duì)于數(shù)學(xué)成績(jī),Tukey post-hoc檢驗(yàn)顯示,來自C學(xué)校的學(xué)生數(shù)學(xué)平均成績(jī)顯著低于來自A學(xué)校(P<0.001)和B學(xué)校(P=0.001)的學(xué)生�,但未發(fā)現(xiàn)來自A學(xué)校的學(xué)生和來自B學(xué)校的學(xué)生數(shù)學(xué)平均成績(jī)存在差異(P=0.443)。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330