SPSS教程:判斷數(shù)據(jù)正態(tài)分布的超多方法
當(dāng)我們應(yīng)用統(tǒng)計(jì)方法對數(shù)據(jù)進(jìn)行分析時(shí),會發(fā)現(xiàn)許多計(jì)量資料的分析方法�,例如常用的T檢驗(yàn)、方差分析�、相關(guān)分析以及線性回歸等等,都要求數(shù)據(jù)服從正態(tài)分布或者近似正態(tài)分布����,但這一前提條件往往被使用者所忽略。因此為了保證數(shù)據(jù)滿足上述統(tǒng)計(jì)方法的應(yīng)用條件�,對原始數(shù)據(jù)進(jìn)行正態(tài)性檢驗(yàn)是十分必要的,這一節(jié)內(nèi)容我們主要向大家介紹如何對數(shù)據(jù)資料進(jìn)行正態(tài)性檢驗(yàn)���。
一����、正態(tài)性檢驗(yàn):偏度和峰度
1、偏度(Skewness):描述數(shù)據(jù)分布不對稱的方向及其程度(見圖1)�。
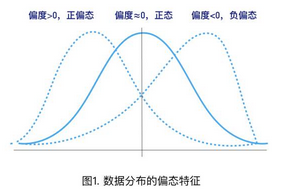
當(dāng)偏度≈0時(shí)����,可認(rèn)為分布是對稱的��,服從正態(tài)分布;
當(dāng)偏度>0時(shí)�,分布為右偏,即拖尾在右邊��,峰尖在左邊��,也稱為正偏態(tài)��;
當(dāng)偏度<0時(shí)�����,分布為左偏,即拖尾在左邊�,峰尖在右邊,也稱為負(fù)偏態(tài)����;
注意:數(shù)據(jù)分布的左偏或右偏���,指的是數(shù)值拖尾的方向�,而不是峰的位置����,容易引起誤解。
2��、峰度(Kurtosis):描述數(shù)據(jù)分布形態(tài)的陡緩程度(圖2)��。
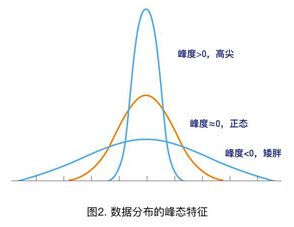
當(dāng)峰度≈0時(shí)���,可認(rèn)為分布的峰態(tài)合適���,服從正態(tài)分布(不胖不瘦);
當(dāng)峰度>0時(shí)���,分布的峰態(tài)陡峭(高尖)�;
當(dāng)峰度<0時(shí),分布的峰態(tài)平緩(矮胖)����;
利用偏度和峰度進(jìn)行正態(tài)性檢驗(yàn)時(shí),可以同時(shí)計(jì)算其相應(yīng)的Z評分(Z-score)��,即:偏度Z-score=偏度值/標(biāo)準(zhǔn)誤��,峰度Z-score=峰度值/標(biāo)準(zhǔn)誤���。在α=0.05的檢驗(yàn)水平下���,若Z-score在±1.96之間,則可認(rèn)為資料服從正態(tài)分布����。
了解偏度和峰度這兩個(gè)統(tǒng)計(jì)量的含義很重要����,在對數(shù)據(jù)進(jìn)行正態(tài)轉(zhuǎn)換時(shí),需要將其作為參考�,選擇合適的轉(zhuǎn)換方法�。
3����、SPSS操作方法
以分析某人群BMI的分布特征為例。
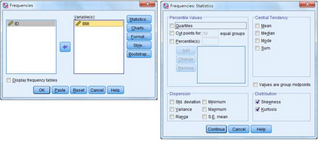
(1) 方法一
選擇Analyze → Descriptive Statistics → Frequencies
將BMI選入Variable(s)框中 → 點(diǎn)擊Statistics → 在Distribution框中勾選Skewness和Kurtosis
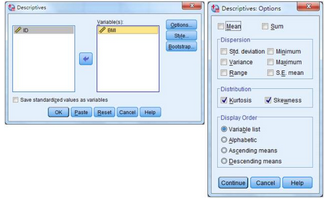
(2) 方法二
選擇Analyze → Descriptive Statistics → Descriptives
將BMI選入Variable(s)框中 → 點(diǎn)擊Options → 在Distribution框中勾選Skewness和Kurtosis
4�����、結(jié)果解讀

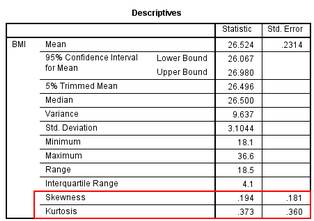
在結(jié)果輸出的Descriptives部分��,對變量BMI進(jìn)行了基本的統(tǒng)計(jì)描述�,同時(shí)給出了其分布的偏度值0.194(標(biāo)準(zhǔn)誤0.181),Z-score
= 0.194/0.181 = 1.072�����,峰度值0.373(標(biāo)準(zhǔn)誤0.360)���,Z-score = 0.373/0.360 =
1.036�����。偏度值和峰度值均≈0��,Z-score均在±1.96之間����,可認(rèn)為資料服從正態(tài)分布。
二��、正態(tài)性檢驗(yàn):圖形判斷
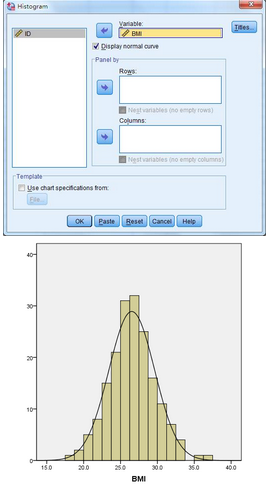
1���、直方圖:表示連續(xù)性變量的頻數(shù)分布����,可以用來考察分布是否服從正態(tài)分布
(1)選擇Graphs → Legacy Diaiogs → Histogram
(2)將BMI選入Variable中����,勾選Display normal curve繪制正態(tài)曲線
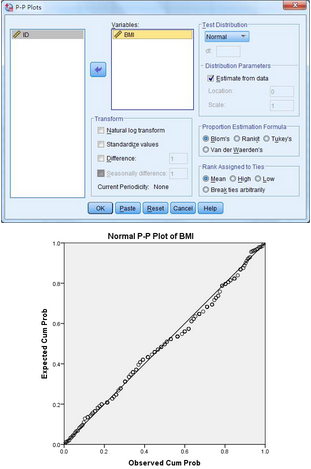
2、P-P圖和Q-Q圖
(1) P-P圖反映了變量的實(shí)際累積概率與理論累積概率的符合程度�����,Q-Q圖反映了變量的實(shí)際分布與理論分布的符合程度����,兩者意義相似,都可以用來考察數(shù)據(jù)資料是否服從某種分布類型�。若數(shù)據(jù)服從正態(tài)分布�����,則數(shù)據(jù)點(diǎn)應(yīng)與理論直線(即對角線)基本重合。
(2) SPSS操作:以P-P圖為例
選擇Analyze → Descriptive Statistics → P-P Plots
將BMI選入Variables中����,Test Distribution選擇Normal,其他選項(xiàng)默認(rèn)即可����。
三、正態(tài)性檢驗(yàn):非參數(shù)檢驗(yàn)分析法
1��、正態(tài)性檢驗(yàn)屬于非參數(shù)檢驗(yàn)�����,原假設(shè)為“樣本來自的總體與正態(tài)分布無顯著性差異�����,即符合正態(tài)分布”�,也就是說P>0.05才能說明資料符合正態(tài)分布。
通常正態(tài)分布的檢驗(yàn)方法有兩種�,一種是Shapiro-Wilk檢驗(yàn),適用于小樣本資料(SPSS規(guī)定樣本量≤5000),另一種是Kolmogorov–Smirnov檢驗(yàn)�����,適用于大樣本資料(SPSS規(guī)定樣本量>5000)��。
2�����、SPSS操作
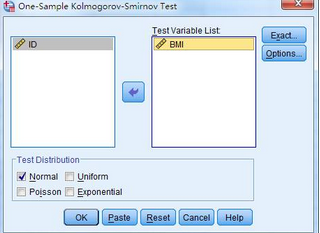
(1) 方法一:Kolmogorov–Smirnov檢驗(yàn)方法可以通過非參數(shù)檢驗(yàn)的途徑實(shí)現(xiàn)
選擇Analyze → Nonparametric Tests → Legacy Dialogs → 1-Sample K-S
將BMI選入Test Variable List中���,在Test Distribution框中勾選Normal���,點(diǎn)擊OK完成操作。
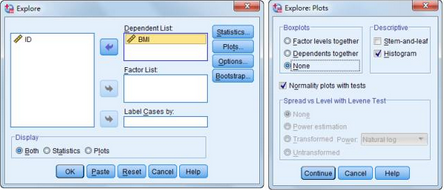
(2) 方法二:Explore方法
選擇Analyze → Descriptive Statistics → Explore
將BMI選入Dependent List中��,點(diǎn)擊Plots�,勾選Normality plots with tests,在Descriptive框中勾選Histogram��,Boxplots選擇None�,點(diǎn)擊OK完成操作。
3��、結(jié)果解讀
(1)在結(jié)果輸出的Descriptives部分,對變量BMI進(jìn)行了基本的統(tǒng)計(jì)描述����,同時(shí)給出了其分布的偏度值�����、峰度值及其標(biāo)準(zhǔn)誤���,具體意義參照上面介紹的內(nèi)容����。
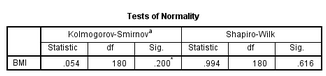
(2)在結(jié)果輸出的Tests
of
Normality部分��,給出了Shapiro-Wilk檢驗(yàn)及Kolmogorov-Smirnov檢驗(yàn)的結(jié)果�,P值分別為0.200和0.616,在α=0.05的檢驗(yàn)水準(zhǔn)下��,P>0.05���,不拒絕原假設(shè)����,可認(rèn)為資料服從正態(tài)分布。
(3)在結(jié)果輸出的最后部分����,同時(shí)給出了直方圖和Q-Q圖,具體意義參照上面介紹的內(nèi)容����。建議可以直接使用Explore方法,結(jié)果中不僅可以輸出偏度值����,峰度值,繪制直方圖�,Q-Q圖,還可以輸出非參數(shù)檢驗(yàn)的結(jié)果����,一舉多得。
四�、注意事項(xiàng)
事實(shí)上,Shapiro-Wilk檢驗(yàn)及Kolmogorov-Smirnov檢驗(yàn)從實(shí)用性的角度��,遠(yuǎn)不如圖形工具進(jìn)行直觀判斷好用�。在使用這兩種檢驗(yàn)方法的時(shí)候要注意,當(dāng)樣本量較少的時(shí)候��,檢驗(yàn)結(jié)果不夠敏感,即使數(shù)據(jù)分布有一定的偏離也不一定能檢驗(yàn)出來���;而當(dāng)樣本量較大的時(shí)候��,檢驗(yàn)結(jié)果又會太過敏感��,只要數(shù)據(jù)稍微有一點(diǎn)偏離,P值就會<0.05�����,檢驗(yàn)結(jié)果傾向于拒絕原假設(shè)��,認(rèn)為數(shù)據(jù)不服從正態(tài)分布��。所以�,如果樣本量足夠多,即使檢驗(yàn)結(jié)果P<0.05���,數(shù)據(jù)來自的總體也可能是服從正態(tài)分布的�����。
因此����,在實(shí)際的應(yīng)用中,往往會出現(xiàn)這樣的情況�,明明直方圖顯示分布很對稱,但正態(tài)性檢驗(yàn)的結(jié)果P值卻<0.05�����,拒絕原假設(shè)認(rèn)為不服從正態(tài)分布�。此時(shí)建議大家不要太刻意追求正態(tài)性檢驗(yàn)的P值,一定要參考直方圖����、P-P圖等圖形工具來幫助判斷。很多統(tǒng)計(jì)學(xué)方法���,如T檢驗(yàn)��、方差分析等����,與其說要求數(shù)據(jù)嚴(yán)格服從正態(tài)分布�,不如說“數(shù)據(jù)分布不要過于偏態(tài)”更為合適。
有專家根據(jù)經(jīng)驗(yàn)提出����,標(biāo)準(zhǔn)差超過均值的1/2時(shí)提示數(shù)據(jù)不服從正態(tài)分布����,或者四分位間距與標(biāo)準(zhǔn)差的比值在1.35左右時(shí)提示服從正態(tài)分布���,這些可以作為正態(tài)性檢驗(yàn)的一個(gè)粗略判斷依據(jù)��,僅供參考�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330