SPSS超詳細(xì)操作:分層回歸(hierarchical multiple regression)
1�、問題與數(shù)據(jù)
最大攜氧能力(maximal aerobic capacity, VO2max)是評(píng)價(jià)人體健康的關(guān)鍵指標(biāo),但因測(cè)量方法復(fù)雜�,不易實(shí)現(xiàn)。某研究者擬通過一些方便��、易得的指標(biāo)建立受試者最大攜氧能力的預(yù)測(cè)模型�����。
目前,該研究者已知受試者的年齡和性別與最大攜氧能力有關(guān)���,但這種關(guān)聯(lián)強(qiáng)度并不足以進(jìn)行回歸模型的預(yù)測(cè)����。因此����,該研究者擬逐個(gè)增加體重(第3個(gè)變量)和心率(第4個(gè)變量)兩個(gè)變量,并判斷是否可以增強(qiáng)模型的預(yù)測(cè)能力����。
本研究中,研究者共招募100位受試者���,分別測(cè)量他們的最大攜氧能力(VO2max)���,并收集年齡(age)、性別(gender)��、體重(weight)和心率(heart_rate)變量信息��,部分?jǐn)?shù)據(jù)如下:
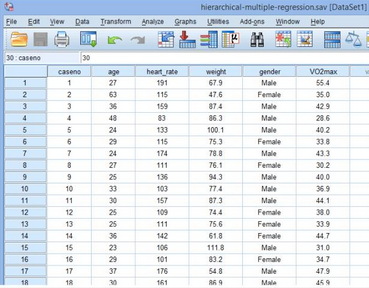
注:心率(heart_rate)測(cè)量的是受試者進(jìn)行20分鐘低強(qiáng)度步行后的心率���。
2����、對(duì)問題的分析
研究者擬判斷逐個(gè)增加自變量(weight和heart_rate)后對(duì)因變量(VO2max)預(yù)測(cè)模型的改變����。針對(duì)這種情況,我們可以使用分層回歸分析(hierarchical multiple regression)����,但需要先滿足以下8項(xiàng)假設(shè):
假設(shè)1:因變量是連續(xù)變量
假設(shè)2:自變量不少于2個(gè)(連續(xù)變量或分類變量都可以)
假設(shè)3:具有相互獨(dú)立的觀測(cè)值
假設(shè)4:自變量和因變量之間存在線性關(guān)系
假設(shè)5:等方差性
假設(shè)6:不存在多重共線性
假設(shè)7:不存在顯著的異常值
假設(shè)8:殘差近似正態(tài)分布
那么����,進(jìn)行分層回歸分析時(shí),如何考慮和處理這8項(xiàng)假設(shè)呢�?
3、對(duì)假設(shè)的判斷
3.1 假設(shè)1-2
假設(shè)1和假設(shè)2分別要求因變量是連續(xù)變量���、自變量不少于2個(gè)����。這與研究設(shè)計(jì)有關(guān)����,需根據(jù)實(shí)際情況判斷����。
3.2 假設(shè)3-8
為了檢驗(yàn)假設(shè)3-8,我們需要在SPSS中運(yùn)行分層回歸��,并對(duì)結(jié)果進(jìn)行一一分析�。
(1)點(diǎn)擊Analyze→Regression→Linear
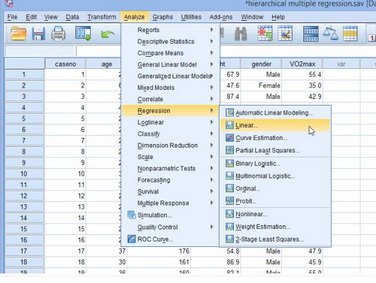
出現(xiàn)下圖:
(2)將因變量(VO2max)放入Dependent欄���,再將自變量(age和gender)放入Independent欄:
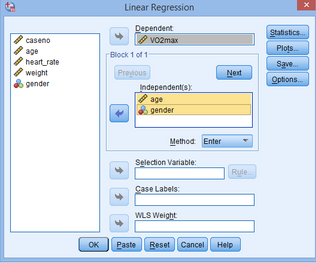
解釋:因研究者已知性別、年齡與最大攜氧能力的關(guān)系��,我們先把這兩個(gè)變量放入模型�����。
(3)點(diǎn)擊Next�����,彈出下圖:
解釋:大家可能會(huì)注意到Independent(s)框中的標(biāo)簽由-Block 1 of 1- 變?yōu)?Block 2 of 2-。這說明age和gender變量依舊存在于模型中��,在- Block 2 of 2-中����,大家可以點(diǎn)擊Previous查看。同時(shí)�����,Method欄應(yīng)設(shè)置為“Enter”��,一般是SPSS自動(dòng)設(shè)置的����;如果不是����,也應(yīng)人工設(shè)置為“Enter”。
(4) 將自變量(weight)放入Independent欄
解釋:放入weight變量是為了檢驗(yàn)加入該變量后對(duì)age�����、gender-VO2max預(yù)測(cè)模型的影響���。
(5)點(diǎn)擊Next����,彈出下圖:
解釋:大家可能會(huì)注意到Independent(s)框中的標(biāo)簽由-Block 2 of 2- 變?yōu)?Block 3 of 3-。同樣地��,age����、gender和weight變量依舊存在于模型中,可以點(diǎn)擊Previous查看�����。Method欄也應(yīng)設(shè)置為“Enter”����,如果不是,改為“Enter”�。
(6)將自變量(heart_rate)放入Independent欄
解釋:放入heart_rate變量是為了檢驗(yàn)加入該變量后對(duì)age、gender��、weight-VO2max預(yù)測(cè)模型的影響�����。
(7)點(diǎn)擊Statistics,彈出下圖:
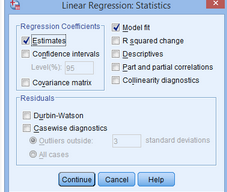
(8)在Regression
Coefficient框內(nèi)點(diǎn)選Confidence
intervals�,在Residuals框內(nèi)點(diǎn)選Durbin-Watson和Casewise diagnosis,并在主對(duì)話框內(nèi)點(diǎn)選R
squared change�、Descriptives、Part and partial correlations和Collinearity
diagnosis
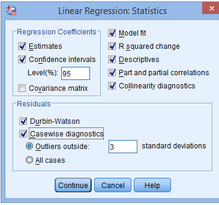
(9) 點(diǎn)擊Continue���,回到主界面��。
(10)點(diǎn)擊Plots��,彈出下圖:
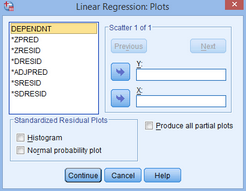
(11)在Standardized Residual Plots對(duì)話框中點(diǎn)選Histogram和Normal probability,并點(diǎn)選Produce all partial plots
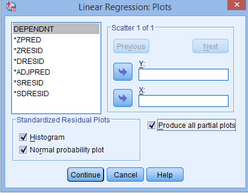
(12)點(diǎn)擊Continue回到主對(duì)話框
(13) 點(diǎn)擊Save
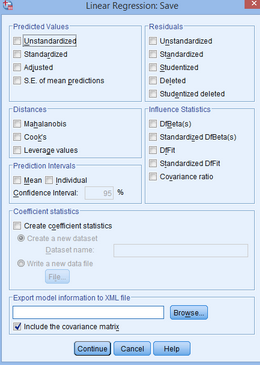
(14)在Predicted Values框內(nèi)點(diǎn)選Unstandardized���,在Distances框內(nèi)點(diǎn)選Cook’s和Leverage values,在Residuals框內(nèi)點(diǎn)選Studentized和Studentized deleted
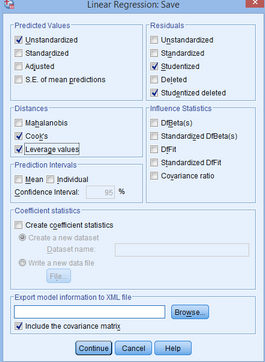
(15)點(diǎn)擊Continue→OK
經(jīng)過這些操作���,Variable View 和Data View對(duì)話框中會(huì)增加5個(gè)變量:
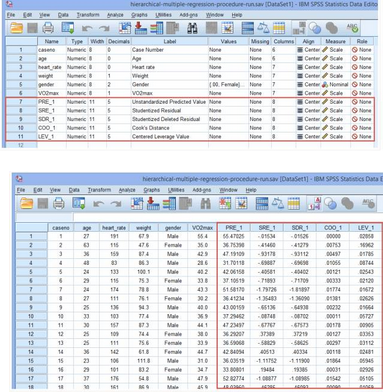
這5個(gè)變量分別是未標(biāo)化預(yù)測(cè)值(unstandardized
predicted values����,PRE_1)����,學(xué)生化殘差(studentized
residuals,SRE_1)��,學(xué)生化刪除殘差(studentized deleted
residuals�,SDR_1),Cook距離(Cook's Distance values�����,COO_1)以及杠桿值(leverage
values�����,LEV_1)��。
根據(jù)這5個(gè)新增變量和其他結(jié)果��,我們將逐一對(duì)假設(shè)3-8進(jìn)行檢驗(yàn)���。
注意:分層回歸對(duì)假設(shè)3-8的檢驗(yàn)過程與多重線性回歸基本一致��,為避免重復(fù)講解�,我們?cè)诒菊鹿?jié)只介紹基本原理��,詳細(xì)內(nèi)容請(qǐng)參見多重線性回歸分析����。
3.2.1 假設(shè)3:具有相互獨(dú)立的觀測(cè)值
觀測(cè)值之間相互獨(dú)立是分層回歸的基本假設(shè)之一�����,主要檢驗(yàn)的是1st-order
autocorrelation���,即鄰近的觀測(cè)值(主要是殘差)之間沒有相關(guān)性。我們根據(jù)SPSS中的Durbin-Watson檢驗(yàn)判斷該假設(shè)����,如果不滿足,則需要運(yùn)用其他模型��,如時(shí)間序列模型等����。
3.2.2 假設(shè)4:自變量和因變量之間存在線性關(guān)系
分層回歸不僅要求因變量與所有自變量存在線性關(guān)系,還要求因變量與每一個(gè)自變量之間存在線性關(guān)系���。其中�,我們主要通過繪制未標(biāo)化預(yù)測(cè)值(PRE_1)和學(xué)生化殘差(SRE_1)的散點(diǎn)圖檢驗(yàn)因變量與所有自變量之間的線性關(guān)系�。
而為檢驗(yàn)因變量與每一個(gè)自變量之間是否存在線性關(guān)系,我們則需要分別繪制每個(gè)自變量與因變量的散點(diǎn)圖�。如果假設(shè)4不滿足���,我們可以嘗試進(jìn)行數(shù)據(jù)轉(zhuǎn)換或者其他統(tǒng)計(jì)方法�。
3.2.3 假設(shè)5:等方差性
等方差性也可以通過學(xué)生化殘差(SRE_1)與未標(biāo)化預(yù)測(cè)值(PRE_1)之間的散點(diǎn)圖進(jìn)行檢驗(yàn)。如果研究結(jié)果提示不滿足等方差性假設(shè)�����,我們也可以通過一些統(tǒng)計(jì)手段進(jìn)行矯正�����,如對(duì)自變量進(jìn)行轉(zhuǎn)換或采用加權(quán)最小二乘法回歸方程等����。
3.2.4 假設(shè)6:不存在多重共線性
當(dāng)回歸中存在2個(gè)或多個(gè)自變量高度相關(guān)時(shí),就會(huì)出現(xiàn)多重共線��。它不僅可影響自變量對(duì)因變量變異的解釋能力�����,還影響整個(gè)分層回歸模型的擬合�����。
為了檢驗(yàn)假設(shè)6,我們主要關(guān)注相關(guān)系數(shù)(correlation
coefficients)和容忍度/方差膨脹因子(Tolerance/VIF)兩類指標(biāo)�。一般來說,如果自變量之間的相關(guān)系數(shù)大于0.7���,或者容忍度小于0.1��,方差膨脹因子大于10��,我們就會(huì)懷疑模型存在多重共線性���。
3.2.5 假設(shè)7:不存在顯著的異常值
根據(jù)作用方式的不同,分層回歸的異常值主要分為離群值(outliers)���、強(qiáng)杠桿點(diǎn)(leverage
points)和強(qiáng)影響點(diǎn)(influential
points)3類����。異常的觀測(cè)值可以符合其中一類或幾類����。但無論是哪一類都對(duì)分層回歸的預(yù)測(cè)能力有著嚴(yán)重的負(fù)面影響。好在我們可以通過SPSS檢測(cè)這些異常值����。
其中�,(1)
離群值是指實(shí)際值與預(yù)測(cè)值相差較大的數(shù)據(jù)�����,可以用Casewise
Diagnostics檢驗(yàn)和學(xué)生化刪除殘差(SDR_1)兩種方法進(jìn)行檢驗(yàn)���。(2) 我們通過數(shù)據(jù)的杠桿值(LEV_1)檢測(cè)強(qiáng)杠桿點(diǎn)。(3)
而強(qiáng)影響點(diǎn)主要通過Cook距離(COO_1)進(jìn)行檢測(cè)�����。如果存在這些異常值����,我們可以根據(jù)實(shí)際情況判斷是否需要剔除或調(diào)整。
3.2.6 假設(shè)8:殘差近似正態(tài)分布
在分層回歸中�����,我們可以使用兩種方法判斷回歸殘差是否近似正態(tài)分布:(1) 帶正態(tài)曲線的柱狀圖或P-P圖��;(2) 根據(jù)學(xué)生化殘差繪制的正態(tài)Q-Q圖��。詳細(xì)內(nèi)容參見多重線性回歸分析����。
4���、結(jié)果解釋
分層回歸可以得到3個(gè)主要結(jié)果:
新增自變量解釋因變量變異的比例
根據(jù)自變量預(yù)測(cè)因變量
自變量改變一個(gè)單位,因變量的變化情況
為了更好地解釋和報(bào)告分層回歸的結(jié)果����,我們需要統(tǒng)計(jì)以下3個(gè)方面:
各模型的比較
模型的擬合程度
回歸系數(shù)
4.1 各模型的比較
比較不同模型是進(jìn)行分層回歸的主要目的。SPSS輸出變量納入結(jié)果����,如下:
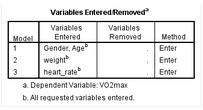
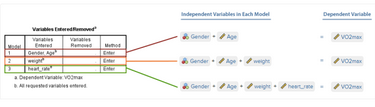
從Model欄可以看出,本研究共有3個(gè)模型:Model 1����、Model 2和Model 3。Variables Entered欄顯示該研究中每個(gè)模型較前一個(gè)模型增加的變量����。
Model
1是第一個(gè)模型,沒有前序變量����,因此該模型的自變量只有g(shù)ender和age。Model 2比前一個(gè)模型(Model
1)增加了weight變量;Model 3比Model 2增加了heart_rate變量���。這3個(gè)模型的納入變量與之前的SPSS操作一致�����,如下:
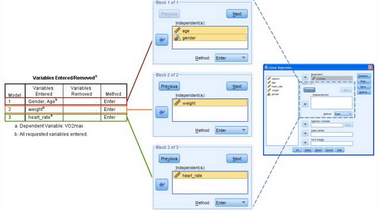
必須注意的是����,Model
2和Model 3中納入的變量都是在上一個(gè)模型基礎(chǔ)上的�����。比如���,Model 3是在Model
2的基礎(chǔ)上納入heart_rate變量,即共納入age�、gender、weight和heart_rate四個(gè)變量��,而不是heart_rate一個(gè)變量����,具體解釋如下:
4.2 判斷分層回歸模型的擬合程度
判斷分層回歸模型擬合程度的指標(biāo)有很多,我們主要向大家介紹變異的解釋程度、R2值在各模型間的變化和模型的統(tǒng)計(jì)學(xué)意義3個(gè)指標(biāo)�。
4.2.1變異的解釋程度
分層回歸中的每個(gè)模型都相當(dāng)于一個(gè)強(qiáng)制納入變量(Enter method)的多重線性回歸模型,具體評(píng)價(jià)指標(biāo)也相似:
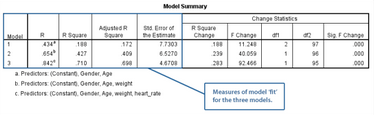
Measures of model ‘fit’ for the three models: 分別評(píng)價(jià)本研究中3個(gè)模型的擬合程度
R2是多層回歸的重要指標(biāo)����,反映自變量解釋因變量變異的程度。從上表可以看出��,隨著自變量數(shù)量的增加���,模型1-3的R2逐漸增加�����,分別是0.188���、0.427和0.710,提示各模型對(duì)因變量的預(yù)測(cè)能力逐漸加強(qiáng)����。
但是分層模型主要是檢驗(yàn)增加自變量是否具有統(tǒng)計(jì)學(xué)意義,如模型2增加了weight變量后R2的變化是否具有統(tǒng)計(jì)學(xué)意義呢�?我們將在4.2.2節(jié)為詳細(xì)大家介紹。
4.2.2R2值在各模型間的變化
為了判斷新增變量對(duì)回歸的影響���,我們需要關(guān)注下表的右半部分:
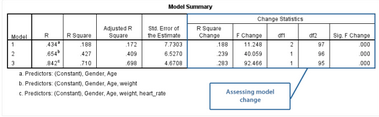
Assessing model change:對(duì)比模型變化
R Square Change欄顯示的是該模型與上一個(gè)模型R2的差值�,Sig. F Change欄顯示的是該差值的統(tǒng)計(jì)檢驗(yàn)的P值。以Model 1為例�,如下:

Initial Model(Model 1):模型1
模型1是初始模型,在空模型的基礎(chǔ)上增加了age和gender兩個(gè)變量����。該模型的R2差值(R Square Change欄)和R2值(R Square欄)相同,均為0.188�。R2差值具有統(tǒng)計(jì)學(xué)意義,P<0.001(Sig. F Change欄)����。
模型2在模型1的基礎(chǔ)上增加了weight變量,R2值的變化情況如下:
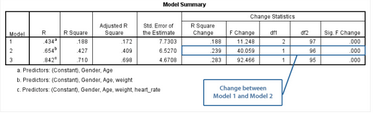
Change between Model 1 and Model 2: 對(duì)比模型1和模型2
模型2的R2差值為0.239�����,即模型2的R2值(0.427)與模型1的R2值(0.188)的差����。Sig. F Change欄提示����,P<0.001,即模型2的R2差值具有統(tǒng)計(jì)學(xué)意義。
在本研究中�����,模型2與模型1的差別僅在于weight變量���,提示在回歸中納入weight變量后自變量對(duì)因變量變異的解釋能力增加23.9%(P<0.001)����,即納入體重變量對(duì)受試者最大攜氧能力的預(yù)測(cè)改善有統(tǒng)計(jì)學(xué)意義�。
解釋:如果我們?cè)谀P?中增加了不止一個(gè)變量,那么R2值的改變就是所有新增變量共同作用的結(jié)果��,而不是某一個(gè)變量的����。
模型3在模型2的基礎(chǔ)上增加了heart_rate變量,R2值的變化情況如下:
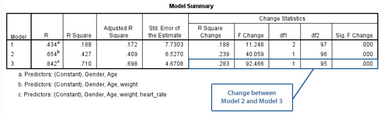
Change between Model 2 and Model 3:對(duì)比模型2和模型3
模型3的R2差值為0.283���,即模型3的R2值(0.710)與模型2的R2值(0.427)的差����。Sig. F Change欄提示�,P<0.001�,即模型3的R2差值具有統(tǒng)計(jì)學(xué)意義���。提示在回歸中納入heart_rate變量后自變量對(duì)因變量變異的解釋能力增加28.3%(P<0.001)�����,即納入心率變量對(duì)受試者最大攜氧能力的預(yù)測(cè)改善有統(tǒng)計(jì)學(xué)意義�����。
4.2.3 模型的統(tǒng)計(jì)學(xué)意義
分層回歸的每一個(gè)模型都相當(dāng)于一個(gè)多重線性回歸模型�。SPSS輸出ANOVA表格中包括對(duì)每一個(gè)模型的評(píng)價(jià)��,如下:
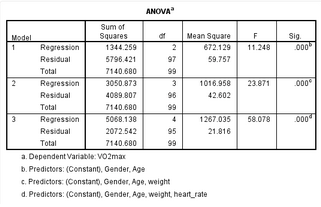
一般來說����,我們習(xí)慣性只匯報(bào)最終模型的結(jié)果(本研究的模型3),如下:
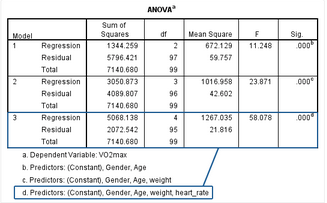
模型3是全模型�,納入gender��、age��、weight和heart_rate四個(gè)變量�����。結(jié)果示,該模型具有統(tǒng)計(jì)學(xué)意義����,F(xiàn)(4,95)=58.078,P<0.001��,提示因變量和自變量之間存在線性相關(guān)�����,說明相較于空模型�,納入這四個(gè)自變量有助于預(yù)測(cè)因變量。
注釋:如果SPSS輸出的結(jié)果中“Sig”值為“.000”���,代表的是P<0.001���,而不是P=0.000。同時(shí)�����,如果P>0.05���,我們最好在報(bào)告中寫清楚具體數(shù)值��,如P=0.092�����,從而為讀者提供更多的信息���。
4.3回歸系數(shù)
正如前文所述��,分層回歸模型主要關(guān)注的是最終模型�,即本研究中的模型3����,在對(duì)回歸系數(shù)進(jìn)行解釋時(shí)也是如此。
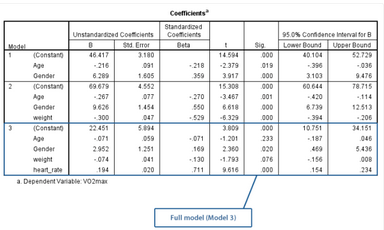
Full model (Model 3):模型3
我們可以按照多重線性回歸的分析方法對(duì)分層回歸系數(shù)進(jìn)行解釋���。連續(xù)變量(如age變量)的回歸系數(shù)表示自變量每改變一個(gè)單位���,因變量的變化情況。分類變量(如gender變量)的回歸系數(shù)表示不同類別之間的差異����,詳細(xì)內(nèi)容參見多重線性回歸。
值得注意的是��,我們運(yùn)行分層回歸的主要目的是分析是否有必要增加新的自變量�,而不是進(jìn)行預(yù)測(cè),回歸系數(shù)不是我們主要關(guān)注的結(jié)果�。但是如果在匯報(bào)時(shí)需要提供回歸系數(shù),我們也可以把這部分增加在報(bào)告中�。
5、撰寫結(jié)論
5.1 簡(jiǎn)潔匯報(bào)
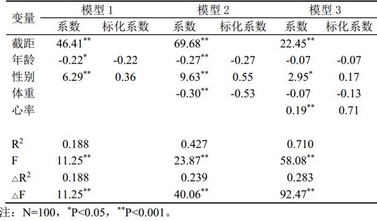
本研究采用分層回歸�,分析逐步增加體重和心率變量是否可以提高性別、年齡對(duì)最大攜氧能力的預(yù)測(cè)水平���。最終模型(模型3)納入性別����、年齡����、體重和心率4個(gè)變量,具有統(tǒng)計(jì)學(xué)意義R2=0.710���,F(xiàn)(4, 95) = 58.078 (P<0.001)����,調(diào)整R2=0.698。
僅增加體重變量(模型2)后���,R2值增加0.239���,F(xiàn)(1, 96) = 40.059(P<0.001),具有統(tǒng)計(jì)學(xué)意義����。增加心率變量(模型3)后,R2值增加0.283���,F(xiàn)(1, 96) = 92.466(P<0.001),具有統(tǒng)計(jì)學(xué)意義���,具體結(jié)果見表1�����。
表1. 分層回歸結(jié)果
5.2具體匯報(bào)
本研究采用分層回歸�,分析逐步增加體重和心率變量是否可以提高性別����、年齡對(duì)最大攜氧能力的預(yù)測(cè)水平�。通過繪制部分回歸散點(diǎn)圖和學(xué)生化殘差與預(yù)測(cè)值的散點(diǎn)圖����,判斷自變量和因變量之間存在線性關(guān)系���。
已驗(yàn)證研究觀測(cè)值之間相互獨(dú)立(Durbin-Watson檢驗(yàn)值為1.910)�;并通過繪制學(xué)生化殘差與未標(biāo)化的預(yù)測(cè)值之間的散點(diǎn)圖����,證實(shí)數(shù)據(jù)具有等方差性。
回歸容忍度均大于0.1���,不存在多重共線性����。異常值檢驗(yàn)中�,不存在學(xué)生化刪除殘差大于3倍標(biāo)準(zhǔn)差的觀測(cè)值,數(shù)據(jù)杠桿值均小于0.2���,也沒有Cook距離大于1的數(shù)值����。Q-Q圖提示,研究數(shù)據(jù)滿足正態(tài)假設(shè)����。
最終模型(模型3)納入性別、年齡�、體重和心率4個(gè)變量,具有統(tǒng)計(jì)學(xué)意義R2=0.710�,F(xiàn)(4, 95) = 58.078 (P<0.001),調(diào)整R2 = 0.698���。僅增加體重變量(模型2)后����,R2值增加0.239��,F(xiàn)(1, 96) = 40.059 (P<0.001)�,具有統(tǒng)計(jì)學(xué)意義。增加心率變量(模型3)后��,R2值增加0.283���,F(xiàn)(1, 96) = 92.466 (P<0.001)�,具有統(tǒng)計(jì)學(xué)意義,具體結(jié)果見表1�����。
表1.分層回歸結(jié)果
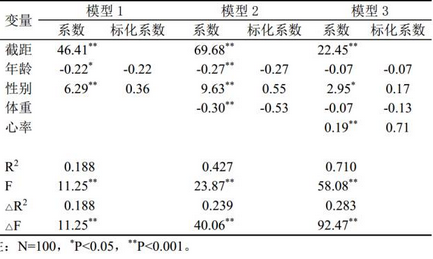
解釋:我們?yōu)榱吮M可能地向大家展示分層回歸結(jié)果����,在表1里納入了所有可能需要匯報(bào)的指標(biāo)��。但在實(shí)際工作中�,大家可能并不需要匯報(bào)這么多,應(yīng)視情況而定�。
相關(guān)性分析背后的統(tǒng)計(jì)學(xué)原理很有趣吧?想深入學(xué)習(xí)統(tǒng)計(jì)學(xué)知識(shí)���,為數(shù)據(jù)分析筑牢根基��?那快來看看統(tǒng)計(jì)學(xué)極簡(jiǎn)入門課程���!

學(xué)習(xí)鏈接:https://edu.cda.cn/goods/show/3386?targetId=5647&preview=0
課程由專業(yè)數(shù)據(jù)分析師打造,完全免費(fèi)�����,60 天有效期且隨到隨學(xué)。它用獨(dú)特思路講重點(diǎn)����,從數(shù)據(jù)種類到統(tǒng)計(jì)學(xué)體系,內(nèi)容通俗易懂�����。學(xué)完它���,能讓你輕松入門統(tǒng)計(jì)學(xué)��,還能提升數(shù)據(jù)分析能力���。趕緊點(diǎn)擊鏈接開啟學(xué)習(xí),讓自己在數(shù)據(jù)領(lǐng)域更上一層樓���!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330